Долгое время бенчмарк ARC оставался почти непреодолимым барьером для систем искусственного интеллекта, проверяя настоящую способность к мышлению, а не простое запоминание. Однако свежие данные демонстрируют, что даже этот рубеж рушится под натиском неустанной оптимизации в лабораториях ИИ.
Корпус абстракции и рассуждений, позже переименованный в ARC-AGI, изначально создавался, чтобы отличать подлинное обучение от статистического повторения. Теперь он повторяет судьбу многих предыдущих тестов: передовые подходы просто преодолевают его.
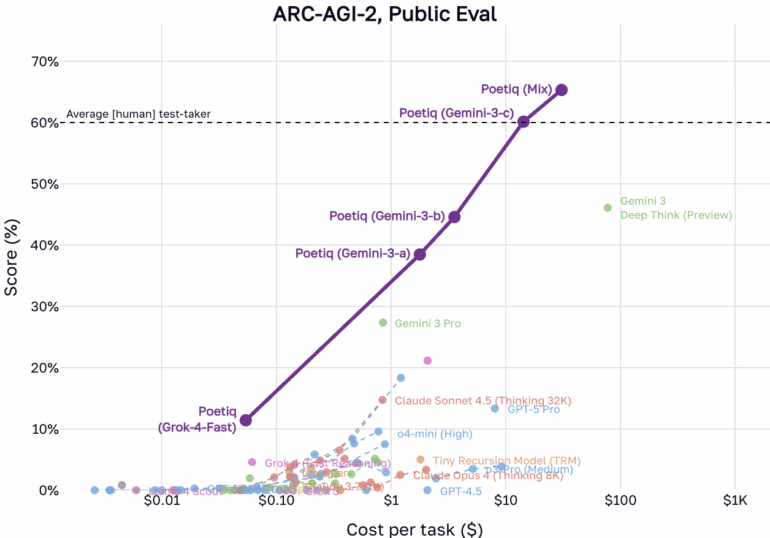
Свежие итоги от компании Poetiq указывают на то, что исходный бенчмарк ARC-AGI-1 фактически решен. В недавнем объявлении фирма утверждает, что ее системы, основанные на моделях от OpenAI и Google, достигли максимума на первом наборе данных. Еще важнее, что система обошла средний человеческий показатель в 60 процентов на куда более трудном датасете ARC-AGI-2.
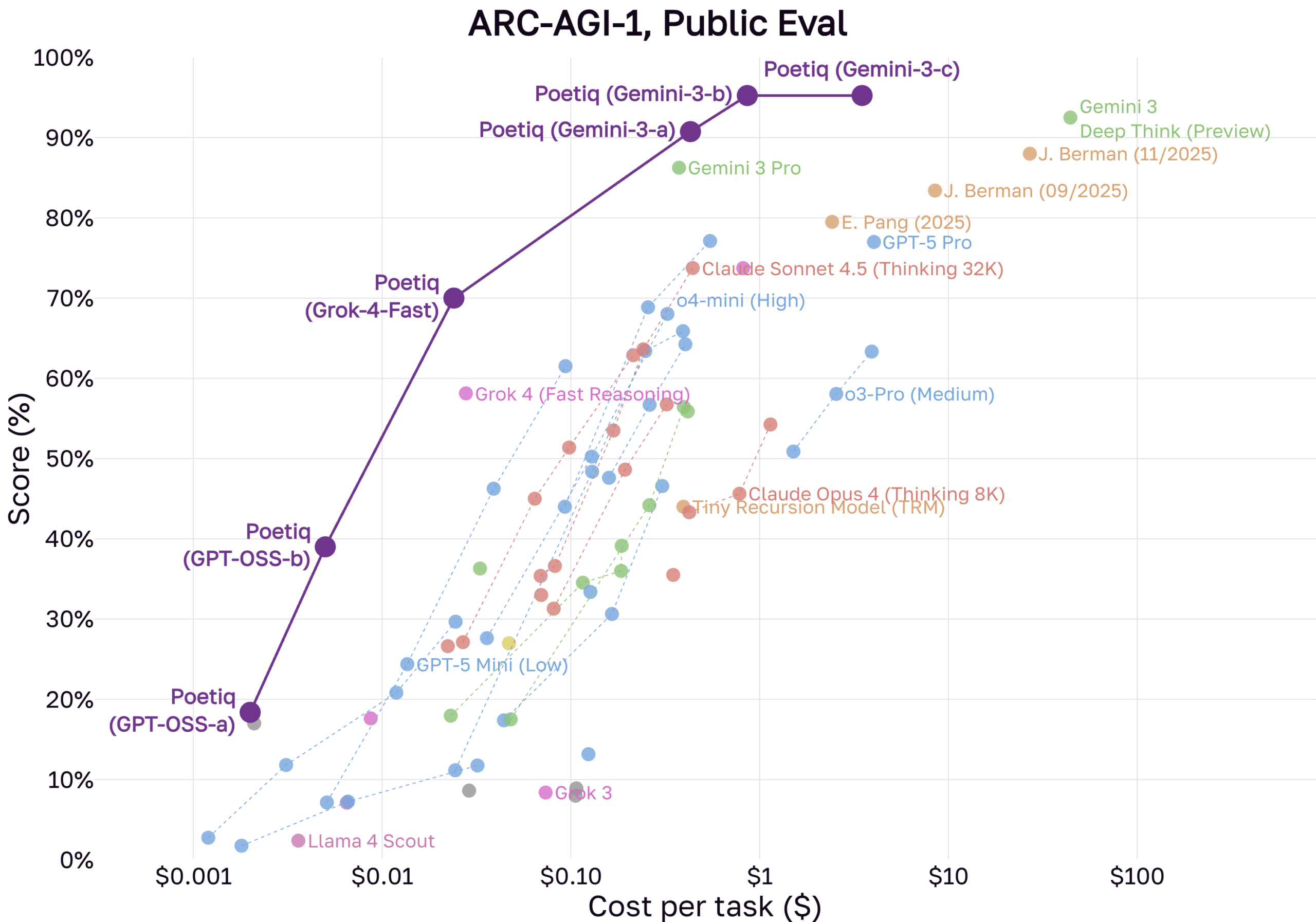
Подход Poetiq сочетает продвинутые языковые модели, такие как Gemini 3 и GPT-5.1, с открытыми моделями в собственной архитектуре. По данным Poetiq, система работает в цикле: она предлагает варианты решений, анализирует отклик, корректирует ответы через внутреннюю проверку и выдает финальный результат.
Специализированные модели превращают абстракцию в задачу оптимизации
Когда исследователь ИИ и создатель Keras Франсуа Шолле представил ARC в 2019 году, он позиционировал его как противовес парадигме глубокого обучения. Цель состояла в оценке эффективности освоения навыков — насколько хорошо система усваивает новые задания, — а не в объеме запоминаемых данных.
Ученые годами бились над этими яркими головоломками на сетках. Хотя языковые модели доминировали на других тестах, результаты на ARC оставались скромными. Для одних это стало ориентиром в исследованиях AGI; для других — указанием на пределы масштабирования больших моделей.
Ситуация изменилась с появлением моделей для рассуждений и методов вроде обучения во время тестирования (TTT). Ключевой момент наступил в декабре 2024 года, когда o3-preview от OpenAI внезапно набрала свыше 75 процентов на ARC-AGI-1. То, что начиналось как проверка абстрактного мышления, подобного человеческому, быстро превратилось в цель для алгоритмов обучения с подкреплением и поиска. Лаборатории теперь настраивают системы под логику ARC.
Эффективность растет вместе с показателями. По словам Poetiq, ее система "Poetiq (GPT-OSS-b)", построенная на открытой модели GPT-OSS-120B, дает более 40 процентов точности на ARC-AGI-1 за менее чем цент за задачу. Эпоха решений ARC, требующих огромных вычислений, похоже, подходит к концу — тенденцию подтверждает и немодельный "Tiny Recursive Model".
Снижение производительности намекает на запоминание общедоступных данных
Эти высокие баллы пока касаются только "публичных" наборов данных, а не "полуприватных", которые держат администраторы ARC. В своем разборе Poetiq отмечает, что базовые языковые модели сильно проседают при переходе с публичных оценочных наборов на полуприватные.
Причина, вероятно, в "загрязнении данными": публичные бенчмарки часто попадают в обучающие наборы больших моделей. Настоящая обобщаемость доказывается только на задачах, которых модель точно не видела. Poetiq предполагает аналогичное падение для своих систем на ARC-AGI-1 по той же причине.
Впрочем, новый ARC-AGI-2 может лучше противостоять этому. Poetiq называет наборы "более точно откалиброванными" и уверяет, что ее система не обучалась на задачах ARC-AGI-2, хотя базовые модели, на которых она стоит, могли.
Отрасль переключается на адаптацию во время тестирования
Шолле внимательно следит за этими изменениями. Он видит в недавних успехах признак фундаментального сдвига в стратегии развития ИИ.
Описывая результаты моделей для рассуждений вроде o3 как "неожиданный и значительный скачок в возможностях ИИ", Шолле считает, что старая тактика масштабирования через большие модели и данные упирается в стену на задачах вроде ARC. Вместо этого отрасль вошла в эпоху адаптации во время тестирования.
Модели больше не статичные ответчики. Они меняются на лету, применяя методы синтеза программ и цепочку мыслей, чтобы перестраиваться под конкретные проблемы. Для Шолле это подтверждает его идею, что интеллект — это процесс приспособления, а не склад знаний.
Он настаивает, что решение ARC необходимо для AGI, но не равно ему. Современные модели все еще спотыкаются на простых заданиях и лишены глубокого понимания мира. Бенчмарк создавался, чтобы подтолкнуть исследования к лучшим системам. И это сработало.
Отрасль отреагировала, хоть и прагматичнее, чем мечтали когнитивные ученые. Вместо "общего интеллекта" появились машины для специализированных рассуждений, которые решают загадки через циклы и генерацию кода.
С насыщением ARC-AGI-1 даже сложный ARC-AGI-2 падает. Система Poetiq обошла человеческий средний уровень, не обучаясь на этих задачах специально.
Решение бенчмарка подтверждает его роль как катализатора
ARC-AGI проходит стандартный цикл бенчмарка: он становится метрикой для маркетинга. Когда цель четкая, а стимулы есть — вроде миллиона долларов от ARC Prize, — лаборатории оптимизируют, пока не добьются цифры.
Это не значит, что ИИ мыслит по-человечески. Это показывает гибкость современных исследований ИИ, которые поражают почти любую абстрактную цель, комбинируя вычисления, синтетические данные и умные методы поиска.
ARC-AGI-1 и ARC-AGI-2 преуспели, заставив сосредоточиться на рассуждениях и приспособлении. Их "решение" — не провал теста, а доказательство его силы в продвижении развития. Останется ли это путем к настоящему fluid intelligence, увидим. Многие, включая Шолле, уверены, что чего-то не хватает.
Он уже думает об ARC-AGI-3, который задействует интерактивные среды для проверки "агентности" моделей — способности действовать.
Poetiq выложила код и результаты на GitHub.