Большие языковые модели осваивают язык, факты и умения из текстов, взятых с веб-страниц. Архив Common Crawl служит основой для большинства наборов данных для тренировки.
Сначала из HTML-кода страниц приходится извлекать чистый текст. Убираются меню навигации, невидимые элементы и код оформления.
Задача выглядит элементарной, однако свежее исследование специалистов из Apple, Стэнфордского университета и Вашингтонского университета подчеркивает: этот этап серьезно сказывается на объеме и чистоте обучающих данных.
Доступны разные инструменты извлечения — скоростной Resiliparse, универсальный Trafilatura и JusText, опирающийся на стоп-слова. Крупные инициативы по датасетам берут один инструмент и используют его повсеместно. Раз результаты моделей на стандартных тестах схожи, выбор раньше считали неважным.
Сочетание экстракторов дает прирост токенов до 71%
Анализ ставит это под сомнение. Специалисты применили одинаковый фильтр к результатам всех трех экстракторов и проверили пересечения сайтов. Лишь 39% страниц прошли через несколько инструментов. Полные 61% — только через один. Каждый метод достает уникальные фрагменты сети; выбор одного оставляет без внимания массу полезного материала.
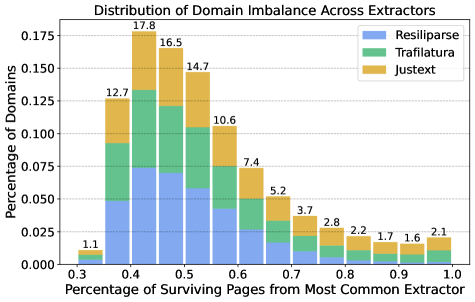
Объединение выходов трех инструментов поднимает выход токенов на 71%, не меняя показателей на бенчмарках. После удаления дубликатов сохраняется 58% дополнительного объема. Набор данных для моделей 7B разрастается с 193 млрд токенов (только Resiliparse) до 283 млрд.
Такой метод превосходит ослабление порогов фильтров в одиночном экстракторе: жесткие правила на комбинации приносят чище страницы, чем мягкие в одном случае. Разница особенно бросается в глаза при моделировании задач на таблицы.
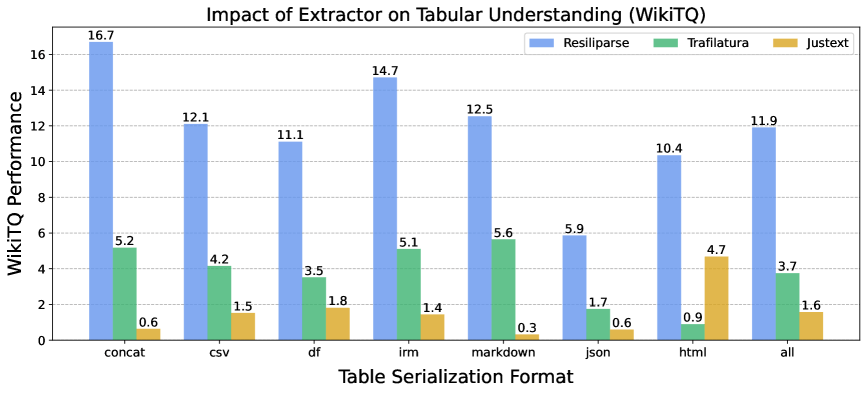
Таблицы и фрагменты кода исчезают в зависимости от инструмента
В общих языковых тестах экстракторы ведут себя похоже. С структурированными данными вроде таблиц и блоков кода разрыв колоссальный: JusText нередко выбрасывает их полностью. Trafilatura конвертирует таблицы в Markdown, но гасит содержимое ячеек. Resiliparse держит материал intact.
На бенчмарке WikiTableQuestions модель 7B с Resiliparse выдаёт 11,9 очков. Trafilatura — 3,7, JusText — 1,6. Resiliparse преодолевает 73% дистанции между DCLM-7B-8k и Llama-3-8B по таблицам, несмотря на паритет в универсальных тестах.
На HumanEval по коду JusText проигрывает до 3,6 процентных пункта — из-за потери блоков кода. Trafilatura ломает отступы, необходимые для синтаксиса языков программирования.
Крошечный этап с гигантским эффектом
Авторы не пытались изобрести новые инструменты, а продемонстрировали: комбинация существующих с отбором по контенту работает эффективнее. Не проверяли способы для расширения охвата дальше. Работа также предупреждает об опасности: лучшая экстракция впустит в модели больше токсичного или авторского материала.
Интернет-данные для языковых моделей исчерпаемы. Осознание, что базовый шаг обработки диктует их использование, побудит команды датасетов перестроить процессы.