Международная группа ученых наводит порядок в исследованиях моделей мира с помощью библиотеки OpenWorldLib. Генераторы видео по текстовым описаниям вроде Sora прямо исключены из определения.
Понятие "модель мира" то и дело всплывает в работах по ИИ, однако единого понимания, что к нему относится, до сих пор нет. Специалисты из Пекинского университета, компании Kuaishou Technology (разработчики видео-генератора Kling), Национального университета Сингапура, университета Цинхуа и других организаций предлагают стандартное определение плюс универсальный фреймворк с открытым кодом OpenWorldLib. Этот инструмент собирает воедино разнообразные задачи для моделей мира.
Ученые считают: модель мира обязана опираться на восприятие реальности, взаимодействовать с окружением и запоминать события на долгий срок — только так она сможет разбираться в поведении сложного мира и прогнозировать его. Такая система работает с мультимодальными данными из окружающего пространства, чтобы их анализировать и на них реагировать, вне зависимости от формы выдачи результатов.
Почему Sora не дотягивает до модели мира
Самое спорное положение в работе касается генерации видео по тексту. После анонса модели Sora от OpenAI, которую потом сняли с производства, ее нередко величали "симулятором мира". Глава DeepMind Демис Хассабис то же самое говорил про видео-модель Veo от Google, называя ее шагом к моделям мира.
Авторы статьи с ними не согласны и поддерживают позицию Яна ЛеКуна: генерация видео хоть и улавливает физические связи, но лишена ключевого элемента — петли обратной связи с реальностью. Такие системы не воспринимают окружение и не влияют на него. Поэтому текст-видео лежит "вне основных задач моделей мира", как указано в публикации.
Из определения также вынесли генерацию кода, поиск в сети и создание видео с аватарами. Последние, к примеру, заточены под развлечения и слабо связаны с постижением физического пространства.

Моделям реального мира нужно взаимодействие, а не просто генерация
Ученые сосредоточились не на пассивном создании медиа, а на трех направлениях задач:
- В интерактивной генерации видео система прогнозирует следующий кадр, опираясь на прошлые и ввод от пользователя. В отличие от текст-видео она отзывается на команды управления или перемещения камеры.
- Мультимодальное рассуждение подразумевает распознавание пространственных, временных и причинно-следственных связей по изображениям, видео и звуку — например, где лежит предмет или по какой причине событие произошло.
- В задачах зрение-язык-действие визуальные данные плюс речевые указания превращаются в точные команды для манипуляторов роботов или беспилотных машин.
Ученые выделяют 3D-реконструкцию и симуляторы как фундаментальные компоненты. Они создают среду с жесткими физическими законами для проверок. Обычное предсказание видео дает лишь визуальную гипотезу о будущем без гарантии соответствия физике.

Пять модулей образуют общий конвейер
Проект OpenWorldLib организует эти функции в модульную структуру. Модуль Operator приводит в единый формат любой ввод — текст, снимки, данные с датчиков. Synthesis отвечает за создание изображений, видео, аудио и управляющих сигналов. Reasoning разбирает пространственный, визуальный и звуковой контекст. Representation возводит 3D-модели и симуляционные миры. Memory фиксирует цепочки взаимодействий, обеспечивая последовательность на протяжении сеанса.
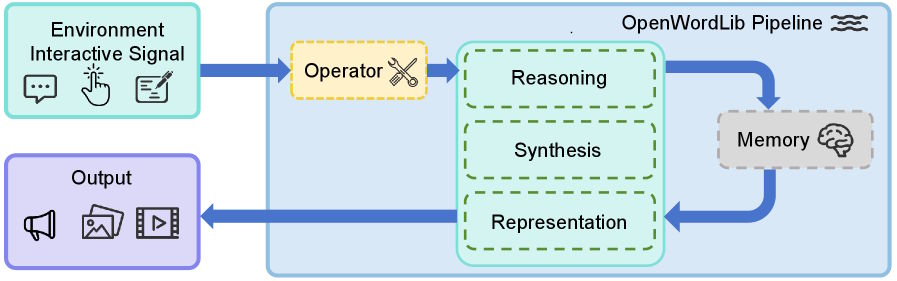
Общий конвейер координирует модули и предоставляет стандартный интерфейс. Благодаря этому исследователи сравнивают модели и подходы в единой среде, без необходимости каждый раз строить свою инфраструктуру.
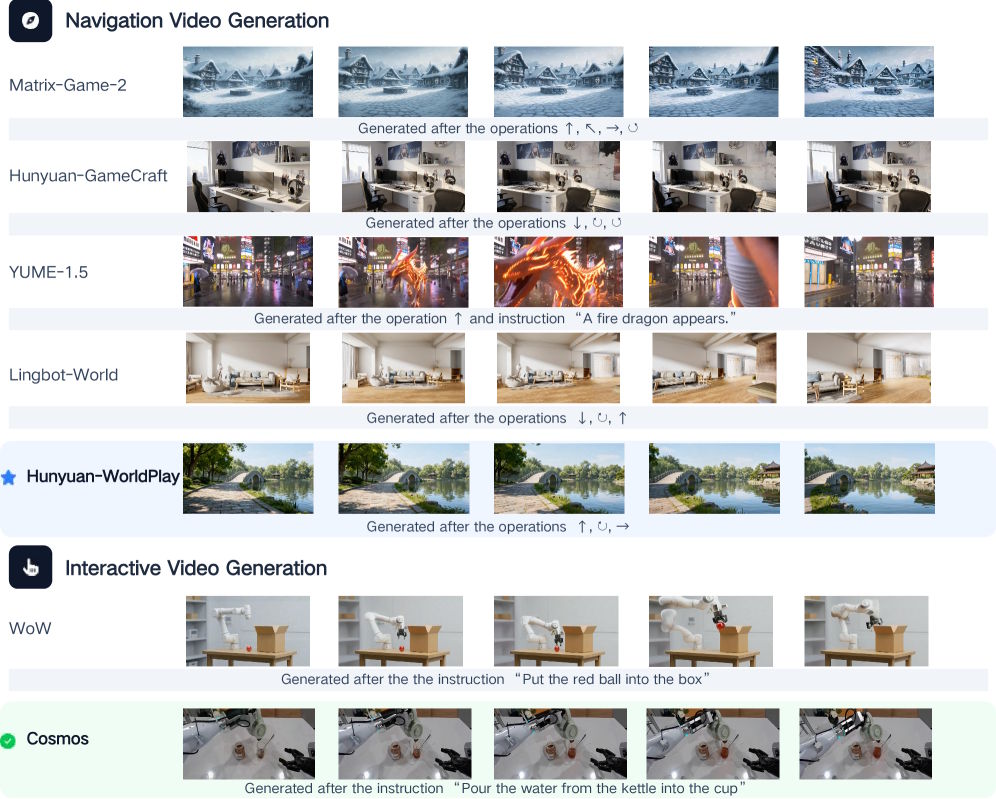
Hunyuan-WorldPlay и Cosmos лидируют в первых тестах
На ускорителях Nvidia A800 и H200 команда провела сравнение доступных моделей в своем фреймворке. Hunyuan-WorldPlay показала высшее визуальное качество в интерактивной генерации видео для сцен навигации.
Модель Cosmos от Nvidia возглавила рейтинг в сложных интерактивных ситуациях с разнообразным вводом от пользователей. Старые методы вроде Matrix-Game-2 работали шустрее, но в длинных последовательностях заметно сбивался цвет.
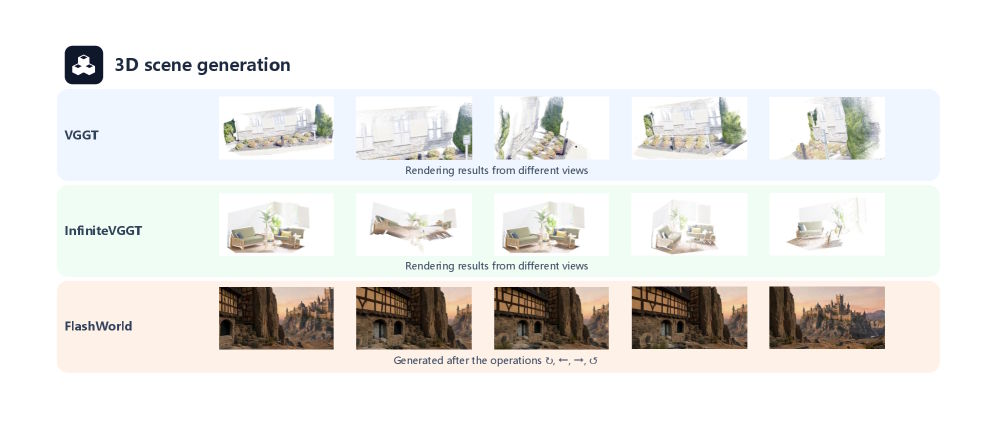
Системы VGGT и InfiniteVGGT явно провалились в реконструкции 3D-сцен. При сильном перемещении камеры возникали геометрические несоответствия и размытости текстур. Тем не менее ученые уверены: 3D-генерация жизненно нужна моделям мира.
Текущие чипы мешают моделям мира развиваться
Авторы также разбирают аппаратную часть, заявляя, что нынешние процессоры принципиально не подходят под нужды моделей мира. Современные чипы заточены под токены, поэтому даже предсказание целых видео-кадров внутри модели дробится на токены. По мнению ученых, это крайне неэффективно для обработки масштабных пространственно-временных данных. Исходный код проекта доступен на GitHub.