С ростом возможностей ИИ задача оценки технических специалистов усложняется. Тестовое задание на дом, которое сейчас позволяет четко разделить кандидатов по уровню навыков, в скором времени модели смогут решать без усилий, и оно перестанет быть полезным инструментом отбора.
Команда по оптимизации производительности в Anthropic применяет задание, где соискатели улучшают код для симулированного ускорителя. Более тысячи человек его выполнили, и десятки инженеров теперь трудятся в компании — те самые, кто запустил кластер Trainium и доработал все модели начиная с Claude 3 Opus.
Каждый свежий релиз Claude требовал переработки теста. Claude Opus 4 в отведенное время обошел почти всех людей. Это еще позволяло выделить лучших, но Claude Opus 4.5 сравнялся и с ними. С неограниченным временем люди опережают модели, однако в жестких рамках задания разница между работой топ-специалистов и самой мощной моделью стирается.
Создатели прошли три итерации задания, чтобы оно продолжало давать полезный сигнал. Ниже описан исходный вариант, способы, которыми модели его преодолевали, и все более нестандартные методы, чтобы тест опережал возможности ведущей модели. Задачи в команде меняются вместе с моделями, но сильных инженеров требуется больше, и их приходится искать креативно.
Как появилось тестовое задание
В ноябре 2023-го в Anthropic готовились к обучению и выпуску Claude 3 Opus. Получили новые кластеры TPU и GPU, подключили крупный Trainium, расходы на ускорители выросли, но специалистов по производительности не хватало для такого масштаба. Стандартный процесс собеседований отнимал уйму времени у сотрудников и кандидатов.
Нужен был эффективный способ проверки соискателей. За две недели разработали задание на дом, отражающее требования роли и выявляющее самых сильных.
Цели создания
Тестовые задания часто критикуют: скучные общие задачи, слабый фильтр. Здесь цель иная — сделать процесс увлекательным, чтобы кандидаты горели желанием участвовать, и оценить навыки с высокой точностью.
Формат лучше живых собеседований для проверки навыков оптимизации производительности:
Длительный горизонт: Инженеры редко работают под дедлайнами меньше часа. Окно в 4 часа (позже сократили до 2) ближе к реальности. Это все равно короче типичных задач, но баланс с нагрузкой на соискателей обязателен.
Реалистичная среда: Без наблюдателей и необходимости комментировать. Кандидаты кодят в своем редакторе без помех.
Время на анализ и инструменты: Оптимизация требует разбора систем и создания отладочных средств. В 50-минутном интервью это сложно проверить правдоподобно.
Совместимость с ИИ: Руководство Anthropic для кандидатов разрешает задания без ИИ, кроме случаев с пометкой. Здесь явно разрешено.
Длинные задачи сложнее для ИИ полностью решить, так что соискатели применяют инструменты ИИ (как на работе), но проявляют свои умения.
Помимо особенностей формата, при создании применили принципы для любых собеседований:
Близость к реальной работе: Задача дает представление о повседневности роли.
Высокий сигнал: Избегать задач на одну идею, дать множество возможностей показать способности — минимизировать случайность. Широкий разброс баллов, глубина, чтобы даже сильные не осилили все.
Без узких знаний: С базовыми навыками specifics осваивают на месте. Специфика сужает пул кандидатов.
Интерес: Быстрые циклы разработки, глубокие проблемы, пространство для творчества.
Симулированная машина
Создали симулятор на Python для вымышленного ускорителя, похожего на TPU. Кандидаты оптимизируют код на нем с hot-reloading трассировкой Perfetto, показывающей каждую инструкцию — как инструменты на Trainium.
Машина имеет черты, делающие оптимизацию увлекательной: ручное управление памятью scratchpad (ускорители часто требуют явного контроля, в отличие от CPU), VLIW (параллельные юниты исполнения в цикле, нужно умело упаковывать инструкции), SIMD (векторные операции на множестве элементов за раз), многозадачность (распределение по ядрам).

Задача — параллельный обход дерева, без акцента на глубоком обучении: большинство инженеров тогда не работали с ним, а детали осваивают на работе. Идея взята из безветвевого SIMD-обхода деревьев решений — классика оптимизации ML, знакомая немногим.
Старт с чисто последовательной реализацией, потом задействуют параллелизм машины. Сначала многозадачность по ядрам, затем на выбор — векторизация SIMD или упаковка VLIW. В первой версии был баг для отладки, проверяющий умение создавать инструменты.
Первые итоги
Задание сработало отлично. Один из первой группы сильно обогнал остальных. Он приступил через две недели после первых наймов по стандартной схеме. Тест предсказал успех: новичок сразу взялся за ядра, нашел обход компиляторского бага с переполнением 32-битной математики индексации тензоров.
За полтора года около тысячи соискателей прошли тест, он помог нанять основу команды по производительности. Особенно полезен для кандидатов без большого опыта: несколько топ-инженеров пришли прямо с университета, но задание убедило в их силах.
Отзывы положительные. Многие превысили 4-часовой лимит от азарта. Лучшие безлимитные работы включали мини-компиляторы и неожиданные оптимизации.
Claude Opus 4 его одолел
К маю 2025-го Claude 3.7 Sonnet поднялся так, что свыше 50% кандидатов выиграли бы, переложив все на Claude Code. Тест предрелизной Claude Opus 4 дал оптимизацию лучше почти всех людей за 4 часа.
Это не первый раз, когда Claude побеждает собеседование. В 2023-м живое задание создали из-за того, что старые опирались на типовые задачи, знакомые ранним Claude. Новое требовало больше мышления, чем знаний, на реальной нишевой проблеме. Claude 3 Opus взял первую часть, Claude 3.5 Sonnet — вторую. Используют дальше, так как другие вопросы тоже уязвимы.
Для задания фикс простой: глубины хватало за 4 часа не осилить. Claude Opus 4 подсказал, где он буксует — это стало стартом версии 2. Переписали код чище, добавили фичи машины, убрали многозадачность (Claude ее решил, она только тормозила без сигнала).
Сократили лимит до 2 часов. 4 часа выбрали по отзывам, чтобы не утонуть в баге, но планирование растягивалось на недели. 2 часа проще вписать в выходные.
Версия 2 фокусировалась на остроумных идеях оптимизации, а не дебаге и объеме кода. Прослужила несколько месяцев.
Claude Opus 4.5 одолел и ее
Предрелизный чекпоинт Claude Opus 4.5 за 2 часа постепенно улучшал решение: решил стартовые узкие места, ввел микрооптимизации, прошел порог за час.
Потом застрял на "непреодолимом" bottleneck пропускной способности памяти. Большинство людей тоже. Но структура задачи позволяет хитрые обходы. Подсказав достижимый счет циклов, модель подумала и нашла трюк, доработала, отладила. К 2 часам балл лучших людей за лимит — и тот человек активно юзал Claude 4 с подсказками.
Внутренний harness подтвердил: за 2 часа бьет людей, дальше растет. После релиза улучшили harness — балл выше.
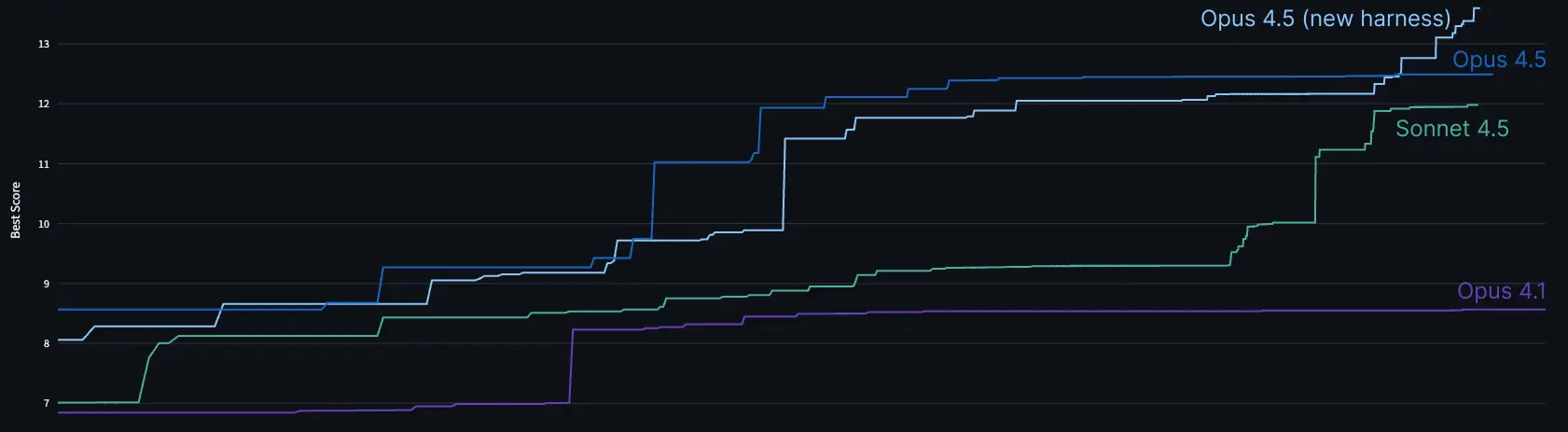
Проблема назрела: модель, где на тесте выгоднее делегировать Claude Code.
Варианты решений
Коллеги предлагали запретить ИИ. Не подошло: сложно контролировать, плюс люди важны в работе, так что нужно отличать их с ИИ — как на деле. Не хотелось сдаваться идее, что преимущество людей только на задачах длиннее часов.
Другие советовали требовать сильно опередить Claude Code соло. Но модель быстрая. Люди тратят половину времени на чтение и разбор. Стир Claude — отстанешь, поймешь постфактум. Стратегия — смотреть со стороны.
Сегодня инженеры в Anthropic заняты сложным дебагом, дизайном систем, анализом производительности, верификацией корректности, упрощением кода Claude. Это трудно проверить объективно без времени или общего контекста. Собеседования всегда были вызовом, сейчас — еще больше.
Беспокоило: новый тест Claude Opus 4.5 сломает, или станет слишком тяжелым для людей за 2 часа.
Попытка 1: Другая задача оптимизации
Claude быстро реализует идеи, так что попробовали сложнее. Выбрали хитрую оптимизацию из опыта Anthropic: эффективный транспонирование данных на 2D-регистрах TPU без конфликтов банков. Упростили для симулятора, Claude воплотил за день.
Claude Opus 4.5 нашел крутую оптимизацию: транспонировал всю вычислительную логику вместо данных, переписал программу.
В реальности это не сработало бы, так что подлатали задачу. Модель продвинулась, но не до топа. Казалось, годится — если люди справятся быстро. Проверили с "ultrathink" и длинным мышлением: решила, включая трюки с банками.
Вспомнив, не лучший выбор: транспонирование и конфликты банков — боль многих платформ, у Claude данных полно. Решение нашли с нуля, модель черпала шире.
Попытка 2: Еще страннее
Нужна задача, где человеческое мышление побеждает опыт модели: сильно out-of-distribution. Конфликт с реализмом работы.
Вспомнили необычные оптимизации из игр Zachtronics. Пазлы с крошечными ограниченными наборами инструкций, код в нетривиальном стиле. В Shenzhen I/O программы на чипах по 10 инструкций с 1-2 регистрами. Оптимизации — кодирование состояния в IP или флагах.
Новое задание — пазлы с миниатюрным ограниченным набором инструкций, цель — минимум инструкций. Сделали средне-сложный, Claude Opus 4.5 не осилил. Дополнили пазлами, коллеги подтвердили: менее погруженные люди бьют модель.
В отличие от игр Zachtronics, без визуализации и дебаггеров. Стартер только проверяет валидность. Создание инструментов — часть теста: принты или ИИ-дебаггер за минуты. Выбор в tooling — сигнал.
Новое задание радует. Возможно, разброс баллов меньше из-за независимых подзадач. Ранние данные хороши: баллы коррелируют с прошлыми достижениями, топ-коллега выше всех кандидатов.
Жаль терять реализм и разнообразие оригинала. Но реализм — роскошь. Оригинал работал как похожий на реальность. Замена — как симуляция новизны.
Открытый вызов
Оригинальное задание открыто для всех с неограниченным временем. Эксперты-люди сохраняют преимущество на длинных горизонтах. Самый быстрый человеческий результат сильно лучше Claude даже с большим compute на тесте.
Версия начинается с нуля (как v1), но с набором инструкций и single-core v2 — циклы сравнимы.
Бенчмарки производительности (циклы симулятора):
- 2164 цикла: Claude Opus 4 после многих часов в test-time compute harness
- 1790 циклов: Claude Opus 4.5 в обычной сессии Claude Code, примерно как лучшие люди за 2 часа
- 1579 циклов: Claude Opus 4.5 после 2 часов в harness
- 1548 циклов: Claude Sonnet 4.5 после многих часов compute
- 1487 циклов: Claude Opus 4.5 после 11.5 часов в harness
- 1363 цикла: Claude Opus 4.5 в улучшенном harness после многих часов