Китайский стартап Deepseek выпустил модель DeepseekMath-V2, которая демонстрирует результаты на уровне золотой медали на олимпиадах по математике и держит компанию в шаге от ведущих западных лабораторий ИИ.
Как сообщает Deepseek, свежая модель DeepseekMath-V2 получила оценки, соответствующие золотой медали, на Международной математической олимпиаде (IMO) 2025 года и на Китайской олимпиаде CMO 2024 года. В соревновании Putnam ИИ набрал 118 баллов из 120 возможных, превзойдя максимальный человеческий показатель в 90 баллов.
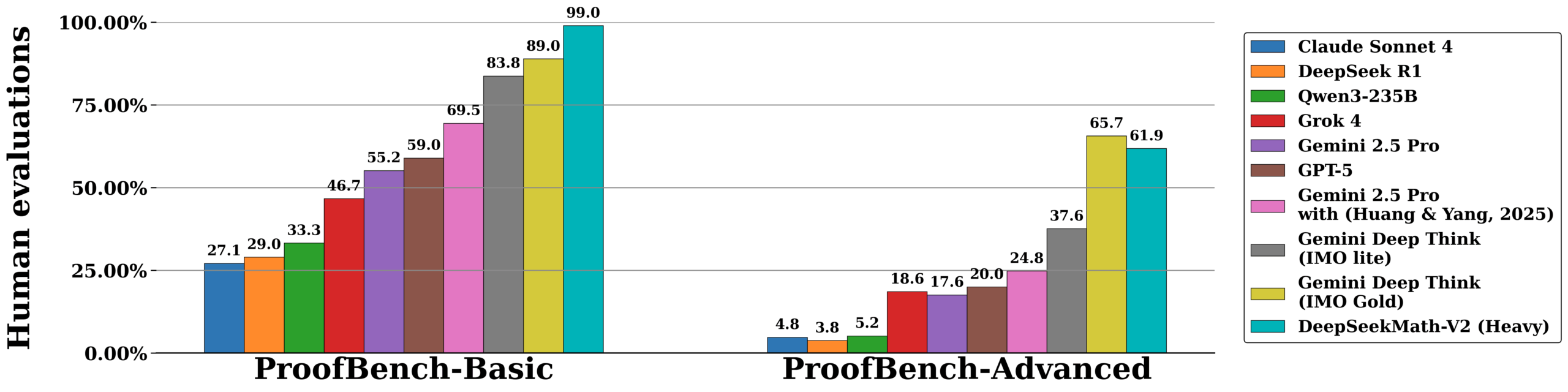
В техническом отчете Deepseek уточняет, что раньше ИИ часто выдавали верные ответы, но без правильных шагов доказательства. Чтобы это исправить, новая модель применяет многоэтапный подход. "Проверяльщик" анализирует доказательство, а "метапроверяльщик" оценивает, насколько обоснована критика. Такая схема позволяет системе в реальном времени оценивать и улучшать свои решения.
В отчете не упоминаются внешние инструменты вроде калькуляторов или интерпретаторов кода, и настройка указывает, что тесты выполнялись только с помощью естественного языка.
В основных экспериментах одна модель DeepSeekMath-V2 отвечает за создание доказательств и их проверку, а успехи объясняются способностью самой модели анализировать и дорабатывать решения, без привлечения специализированного математического ПО.
Для сложных задач система увеличивает вычисления во время тестирования, генерируя и проверяя множество вариантов доказательств параллельно, чтобы добиться уверенности в итоговом ответе. По сути, модель построена на базе Deepseek-V3.2-Exp-Base.

Сближение с американскими лабораториями
Выпуск модели следует за похожими анонсами от OpenAI и Google DeepMind, чьи пока неопубликованные модели тоже завоевали золотые медали на IMO — достижения, которые раньше казались недостижимыми для больших языковых моделей. Важно, что эти системы преуспели благодаря общим навыкам рассуждения, а не специальным доработкам под математические конкурсы.
Если эти прорывы подтвердятся, то языковые модели приближаются к этапу, когда смогут решать запутанные абстрактные задачи, которые всегда считались прерогативой человека. Однако детали этих моделей остаются загадкой. Недавно исследователь OpenAI намекнул, что в ближайшие месяцы выйдет еще более мощная версия их математической модели.
Решение Deepseek поделиться техническими подробностями резко отличается от скрытности OpenAI и Google. Пока американские лидеры прячут архитектуру, Deepseek открыто показывает карты, подтверждая, что не отстает от топовых лабораторий отрасли.
Такая открытость служит еще и ударом по западной экосистеме ИИ — тактику Deepseek уже успешно применял в начале года. Стратегия окупается: как пишет The Economist, многие американские стартапы ИИ теперь предпочитают китайские открытые модели крупным поставщикам из США, чтобы сэкономить.
Но соперничество имеет и другую сторону. По мере роста способностей моделей их создание превращается в острую политическую тему, что может только укрепить позиции американских лабораторий. Активно двигая границы, Deepseek в итоге помогает OpenAI и конкурентам обосновывать темпы и масштаб своих разработок.