Perplexity запускает BrowseSafe для защиты AI-агентов в браузере
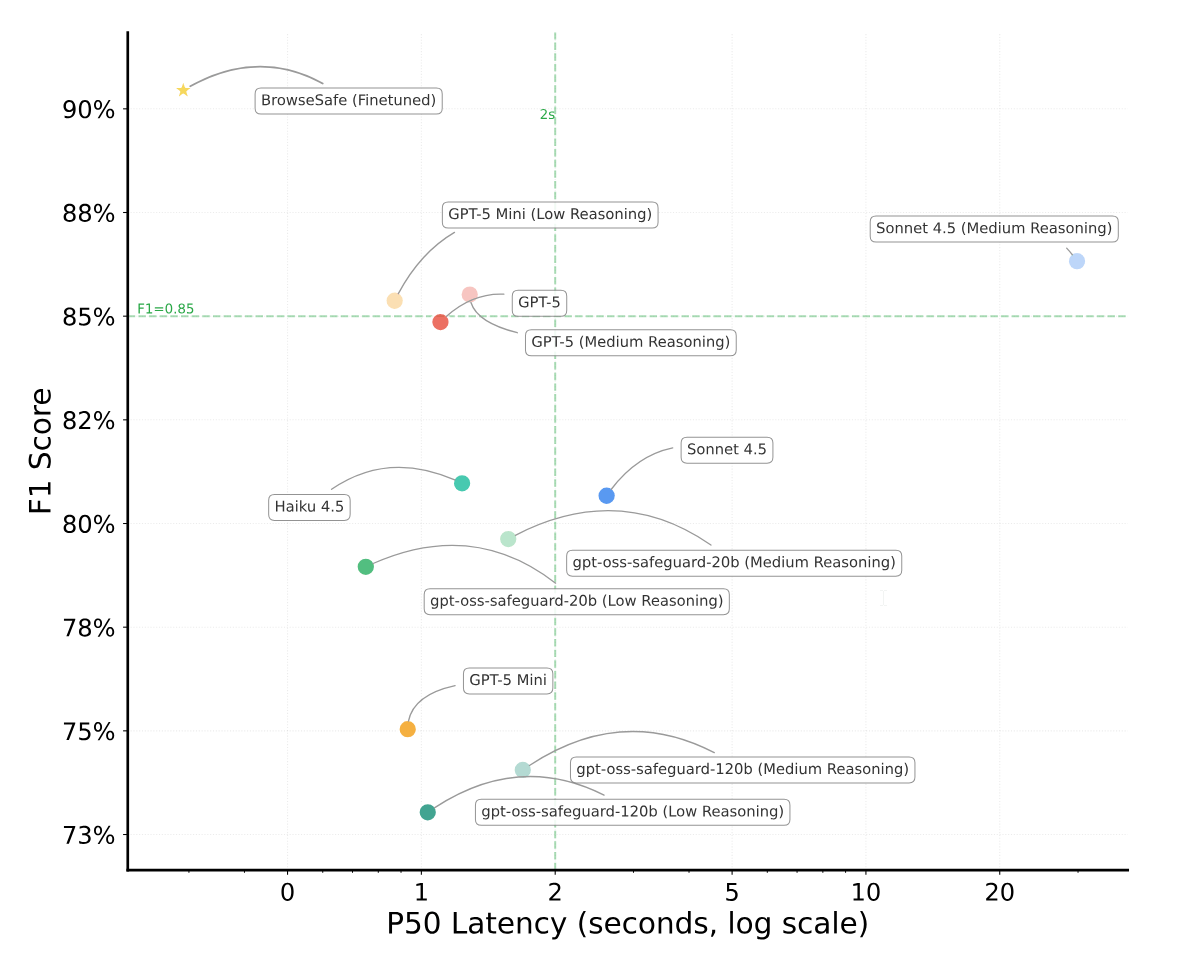
Perplexity представила систему безопасности для AI-агентов в браузере, которая должна защищать их от вредоносного веб-контента. По данным компании, система под названием BrowseSafe фиксирует 91 процент атак типа prompt injection.
Такой уровень обнаружения выше, чем у существующих решений. Для сравнения, более компактные модели вроде PromptGuard-2 распознают около 35 процентов атак, а крупные передовые модели уровня GPT-5 достигают примерно 85 процентов. При этом BrowseSafe, по словам Perplexity, работает достаточно быстро, чтобы использоваться в режиме реального времени.
Агенты в браузере открывают новые дыры в безопасности
В начале года Perplexity выпустила браузер Comet с встроенными AI-агентами. Эти агенты видят сайты так же, как и человек, и могут выполнять действия в авторизованных сессиях — например, в почтовых сервисах, интернет-банкинге или корпоративных веб-приложениях.
Такой уровень доступа формирует, по формулировке Perplexity, "неизученную поверхность атаки". Злоумышленники могут прятать вредоносные инструкции прямо в содержимом страниц, заставляя агента выполнять чужую волю: например, пересылать конфиденциальные данные на сторонние адреса.
Серьезность проблемы стала очевидной в августе 2025 года, когда компания Brave сообщила об уязвимости безопасности в Comet. В атаке использовался метод косвенного prompt injection: команды внедрялись в текст страниц или в пользовательские комментарии. При попытке сжать или пересказать содержимое AI-помощник принимал эти скрытые инструкции за запрос пользователя. Brave показала, что с помощью такого подхода можно похищать чувствительные данные, включая адреса электронной почты и одноразовые пароли.
Perplexity считает, что существующие тестовые стенды для оценки безопасности, такие как AgentDojo, слабо отражают реальные угрозы. Часто они опираются на примитивные промты уровня "Ignore previous instructions", тогда как настоящие сайты наполнены сложным и хаотичным контентом, в котором вредоносные фрагменты легко маскируются.
Как Perplexity моделирует реальные атаки
Чтобы приблизить тестирование к реальной обстановке, Perplexity разработала бенчмарк BrowseSafe Bench, основанный на трех ключевых измерениях.
Во-первых, "тип атаки" описывает конечную цель злоумышленника — от простого перезаписывания инструкций до продвинутых сценариев социальной инженерии.
Во-вторых, "стратегия внедрения" определяет место, где будут спрятаны команды: это могут быть, например, HTML-комментарии или блоки с пользовательским контентом.
В-третьих, "лингвистический стиль" отражает, насколько явно или замаскированно сформулированы указания — от грубых, легко узнаваемых триггеров до аккуратно сформулированного текста уровня профессиональной деловой переписки.
Критически важно, что в бенчмарке присутствуют так называемые "сложные негативные" примеры. Это запутанный, но безвредный контент — например, фрагменты программного кода или технической документации, которые внешне напоминают атаку. Без таких примеров модели безопасности склонны "зазубривать" поверхностные признаки, вроде отдельных ключевых слов, и начинают массово помечать безопасный контент как опасный.
Внутри BrowseSafe используется архитектура mixture-of-experts на базе модели Qwen3-30B-A3B-Instruct-2507, оптимизированная под высокую пропускную способность и сравнительно небольшие накладные расходы. Проверка безопасности запускается параллельно с выполнением задач агентом, поэтому она не блокирует и не тормозит работу пользователя.
Многоязычные атаки и "отвлекающие" фрагменты: где модели сдаются
Оценка BrowseSafe выявила несколько неожиданных уязвимостей. Оказалось, что многоязычные атаки (когда инструкции частично или полностью написаны не на английском) снижают качество обнаружения до 76 процентов: многие модели слишком сильно опираются на англоязычные триггеры и хуже замечают угрозы на других языках.
Неожиданным результатом стало и то, что атаки, спрятанные в HTML-комментариях, обнаруживаются проще, чем инструкции, размещенные в видимых для пользователя частях страницы — например, в футере. То есть "невидимые" части кода страницы не всегда оказываются самым удобным укрытием для злоумышленников.

Еще одна проблема — даже небольшое количество нейтральных "отвлекающих" фрагментов сильно ухудшает результаты. По данным Perplexity, всего три текста, внешне похожие на промты, но не содержащие вредоносных команд, снижают точность моделей с 90 до 81 процента. Это указывает на то, что многие системы безопасности опираются на ложные корреляции и не выстраивают устойчивые, по‑настоящему осмысленные шаблоны распознавания атак.
Трехуровневая архитектура защиты BrowseSafe
Оборона в BrowseSafe строится по трехуровневой схеме.
Первый уровень — любой инструмент, работающий с веб-контентом, по умолчанию считается недостоверным источником. Все входящие данные сразу же прогоняются через быстрый классификатор, который в реальном времени решает, есть ли признаки prompt injection или других форм вмешательства.
Второй уровень включается, когда базовый классификатор не уверен в своем решении. В этом случае в дело вступает крупная frontier‑модель с развитой способностью к рассуждению: она детальнее анализирует подозрительный фрагмент, чтобы выявить новые, ранее не встречавшиеся типы атак.
Третий уровень касается обучения самой системы: пограничные случаи, по которым модели затрудняются принять решение, помечаются и затем используются для дообучения и уточнения BrowseSafe.
Perplexity открыто публикует бенчмарк BrowseSafe Bench, саму модель BrowseSafe и научную статью по проекту. Компания рассчитывает, что это поможет повысить безопасность взаимодействия AI-агентов с вебом в отрасли в целом.
Интерес к таким решениям высок: крупные игроки вроде OpenAI, Opera и Google активно встраивают AI-агентов в свои браузеры и сталкиваются с аналогичными угрозами и похожими уязвимостями.
При этом BrowseSafe по‑прежнему пропускает почти 10 процентов атак, что слишком много для задач реальной кибербезопасности. В живой среде интернета сложность только растет: появляются новые тактики и векторы атак, которые невозможно полностью заложить в тестовые наборы. К примеру, существуют изощренные техники jailbreak‑атак, маскирующихся под "безобидные" стихотворения или другие творческие форматы, что дополнительно усложняет защиту AI-агентов.