ИИ-агенты используют специализированные знания через так называемые навыки. Исследование с тестированием 34 тысяч реальных навыков показало: в реалистичных условиях эти дополнения почти не улучшают результаты, а слабые модели с ними работают даже хуже.
Anthropic впервые представила навыки в октябре 2025 года как модульную систему для Claude Code — агент сам определяет, какие специализированные инструкции нужны для задачи. Платформы вроде Codex от OpenAI и множество open-source-проектов быстро переняли эту идею.
Навыки — это структурированные текстовые файлы с знаниями по конкретным областям: рабочие процессы, шаблоны использования API, лучшие практики. ИИ-системы с агентами могут извлекать такие файлы во время работы и применять описанные в них процедуры. Главный вопрос: насколько полезны навыки, когда агенты сами их находят и используют?
Текущие бенчмарки рисуют слишком радужную картину
Новое исследование ученых из UC Santa Barbara, MIT CSAIL и MIT-IBM Watson AI Lab дает трезвый ответ: преимущества навыков «хрупкие» и резко сокращаются в более реалистичных условиях. В самых сложных сценариях показатели едва превышают базовый уровень без навыков.
Проблема, по словам авторов, в методах тестирования навыков до сих пор. Бенчмарк SKILLSBENCH передает агентам тщательно подобранные навыки именно под задачу — по сути, пошаговую инструкцию.
Пример из исследования: задача по определению дней наводнений на станциях USGS. Три предоставленных навыка содержат точный API для загрузки данных о уровне воды, URL с пороговыми значениями наводнений и готовые фрагменты кода для их выявления. «Эти навыки вместе почти напрямую описывают полное решение задачи», — отмечают исследователи.

В реальности агенты не получают готовых навыков и не знают, существуют ли подходящие. Им приходится рыться в больших, шумных коллекциях самостоятельно и подстраивать универсальные навыки под конкретные задачи.
34 тысячи реальных навыков на проверку
Для своего исследования ученые собрали 34 198 реальных навыков из open-source-репозиториев с permissive-лицензиями (MIT и Apache 2.0), удалив дубликаты. Навыки взяты с агрегаторов skillhub.club и skills.sh, охватывают веб-разработку, data engineering и научные вычисления.
Команда проверила шесть сценариев с нарастающей реалистичностью: от прямой передачи подобранных навыков до добавления отвлекающих, самостоятельного поиска по всей коллекции — с curated-навыками и без.
Три модели прошли полный цикл: Claude Opus 4.6 с Claude Code, Kimi K2.5 с Terminus-2, Qwen3.5-397B-A17B с Qwen Code. Каждая модель самостоятельно искала навыки и решала задачи.
Показатели падают по мере приближения к реальности
Результаты демонстрируют стабильное ухудшение у всех моделей. Claude Opus 4.6 достигла 55,4% успеха при принудительной загрузке curated-навыков. При самостоятельном выборе — 51,2%. С отвлекающими — 43,5%, при независимом поиске — 40,1%, без curated в пуле — 38,4%. Базовый уровень без навыков — 35,4%.
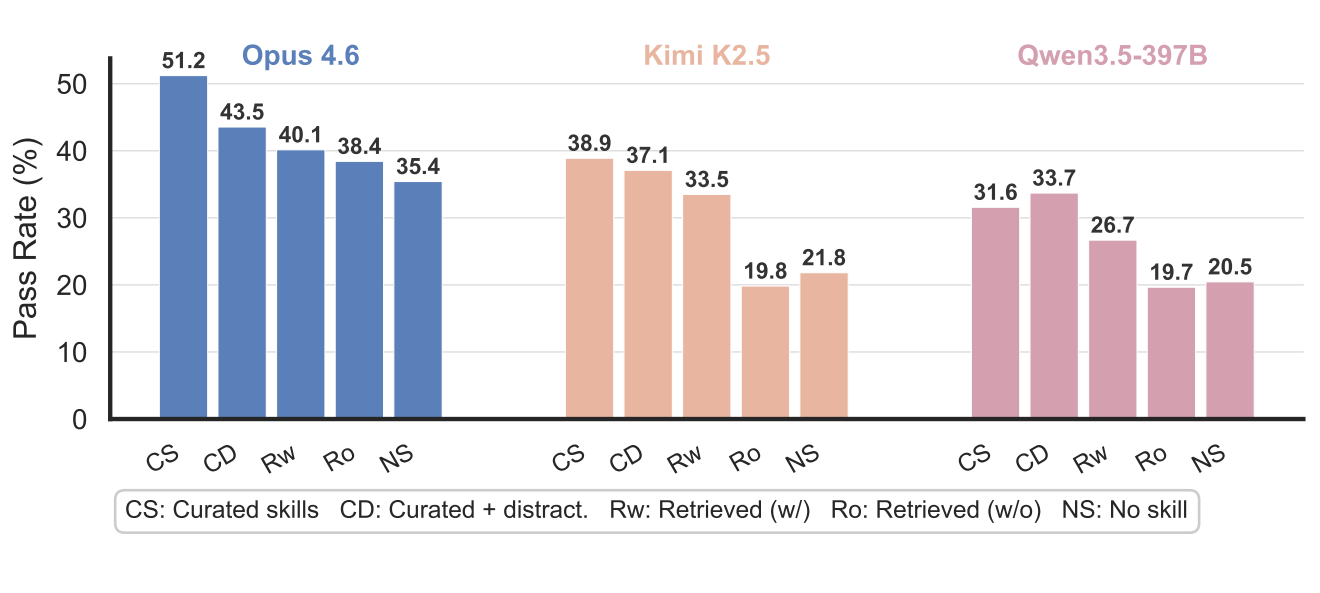
У слабых моделей картина хуже: Kimi K2.5 в самом реалистичном сценарии показала 19,8% — ниже базового уровня без навыков в 21,8%. Qwen3.5-397B — 19,7% против 20,5%. Нерелевантные навыки отвлекают слабые модели, тратя ресурсы на бесполезные инструкции.
Агенты слабы в выборе, поиске и адаптации
Исследователи выделили три узких места. Во-первых, проблемы на этапе выбора: даже с curated-навыками Claude загружает все только в 49% случаев. С отвлекающими — 31%. Kimi загружает чаще — 86% в curated-сценарии, что авторы связывают с особенностями среды агента. Но это не улучшает решение задач.
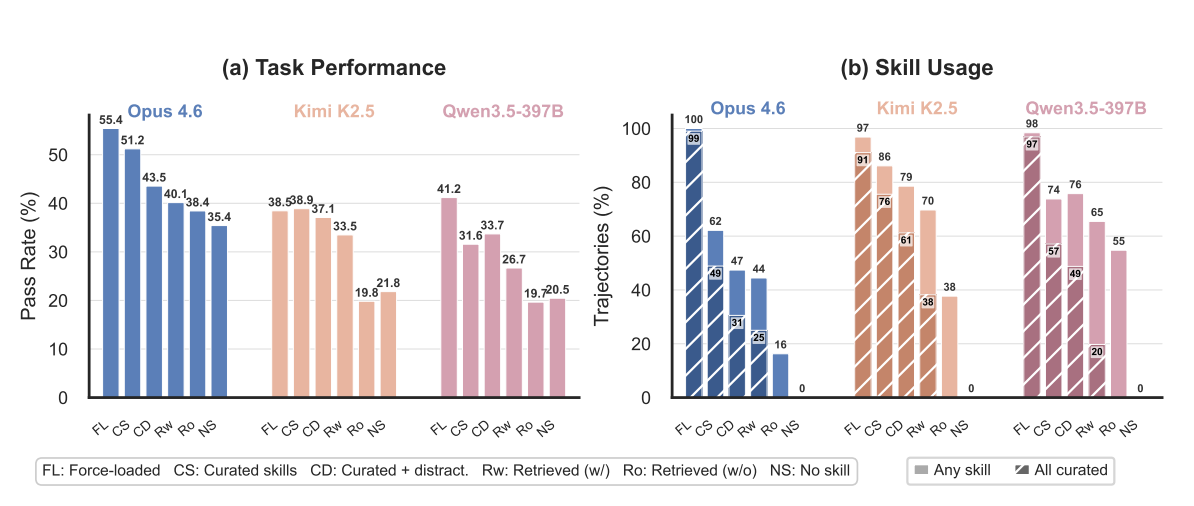
Во-вторых, самостоятельный поиск ухудшает дело: лучший метод retrieval дает Recall@5 в 65,5%. В-третьих, агенты не адаптируют универсальные навыки под задачи без tailored-вариантов.
Для поиска навыков сравнили стратегии. Лучший — «агентный гибридный поиск»: агент итеративно пишет запросы, проверяет кандидатов, корректирует подход. Он опередил семантический поиск на 18,7 п.п. по Recall@3.
Уточнение улучшает, но требует сильной основы
Чтобы сократить разрыв, протестировали два метода уточнения. В task-specific refinement агент изучает задачу, пробует решить, оценивает полезность навыков и создает новые, подогнанные. В задаче по tensor parallelism агент объединил идеи из двух навыков в третий, которого не было в исходных.
Цифры: Claude на SKILLSBENCH выросла с 40,1% до 48,2%. На общем бенчмарке Terminal-Bench 2.0 — с 61,4% до 65,5%. Подъем с 57,7% до 65,5% отражает эффект retrieval + refinement над базовым уровнем.
Task-independent refinement (оффлайн-улучшение без знания задачи) дал разрозненные плюсы. Авторы заключают: уточнение усиливает качество существующих навыков, а не создает новые знания. Оно эффективно, только если исходные навыки уже релевантны.
Ранние тесты уже указывали на проблемы навыков
Результаты согласуются с исследованием Vercel: в 56% случаев агент не извлекал доступный навык, успех с навыками равнялся базовому без документации. Простой Markdown-файл (AGENTS.md), загруженный пассивно, дал 100%, навыковая система — максимум 79%.
Текущее исследование подтверждает это системно на множестве моделей и большем масштабе: агенты часто игнорируют релевантные навыки.
Команда предлагает улучшить retrieval, оффлайн-уточнение и экосистемы навыков с учетом способностей моделей. Код исследования доступен на GitHub.