
Бенчмарк ProactiveBench проверяет, умеют ли мультимодальные языковые модели обращаться за помощью к пользователям, когда не хватает визуальных данных. Из 22 протестированных моделей почти ни одна не запрашивает нужную информацию, зато подход на основе обучения с подкреплением предлагает способ исправить это.
Человек, которому нужно опознать заслоненный объект, попросит убрать преграду. Мультимодальные языковые модели действуют иначе: выдумывают неверный ответ или вовсе отказываются отвечать. Новый бенчмарк ProactiveBench тщательно изучает эту проблему, проверяя, распознают ли современные ИИ-модели моменты неопределенности и просят ли помощи.
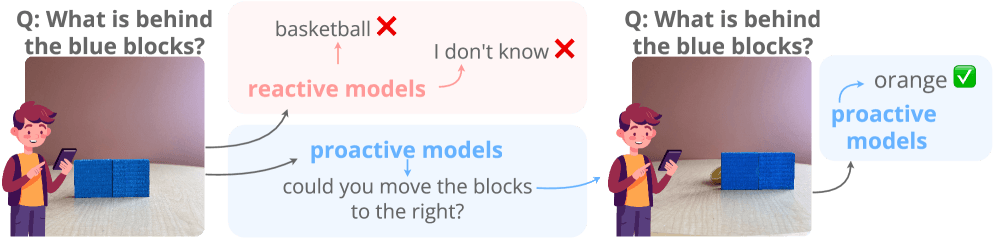
Бенчмарк использует семь существующих датасетов, превращая их в сценарии, где без подсказки от человека не обойтись. Модели должны находить скрытые объекты, очищать зашумленные снимки, разбирать наброски или требовать смену ракурса. В итоге ProactiveBench содержит свыше 108 000 изображений в 18 000 примерах. Встроенный фильтр отсекает задачи, которые модель решает с первого раза; чтобы пройти тест, ИИ обязан сам запросить дополнительные данные.

Большие модели не задают лучшие вопросы
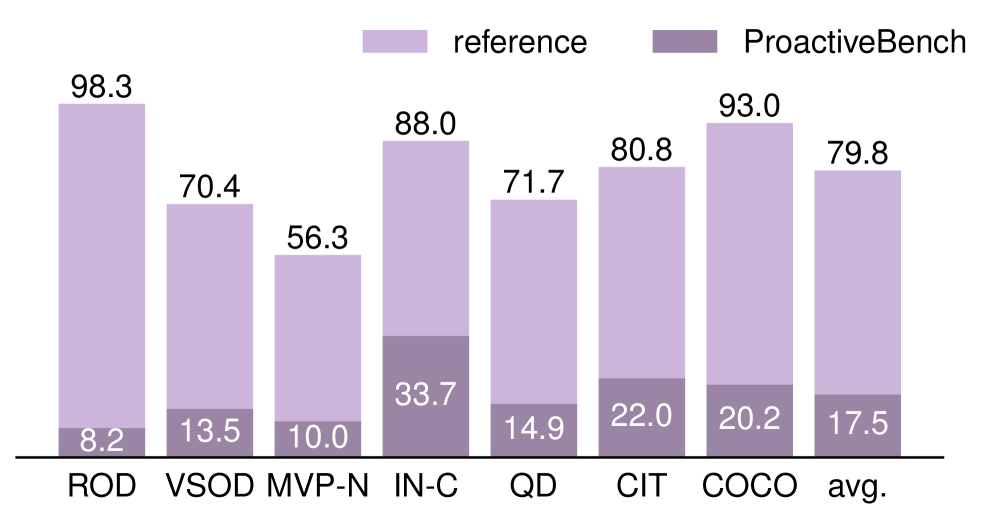
Исследователи протестировали 22 мультимодальные языковые модели, включая LLaVA-OV, Qwen2.5-VL, InternVL3, GPT-4.1, GPT-5.2 и o4-mini. В стандартных условиях с видимыми объектами средняя точность достигает 79,8%. В ProactiveBench она падает более чем на 60%.
Датасет ROD показывает разницу ярче всего. Когда объекты прячут за блоками, точность рушится с 98,3% до жалких 8,2%. Модели без проблем видят объекты на виду, но не додумываются попросить их открыть.
Размер модели не спасает. InternVL3-1B обходит InternVL3-8B с 27,1% против 12,7%. Старая LLaVA-1.5-7B лучше новой LLaVA-OV-72B — 24,8% против 13%. Базовая языковая модель тоже влияет: LLaVA-NeXT на Vicuna набирает 19,3%, на Mistral — лишь 4,5%. Закрытые модели вроде GPT-4.1 лидируют, но исследователи отмечают подозрительно высокие результаты по COCO как возможное загрязнение данными.
Похожесть на проактивность — всего лишь везение
Некоторые модели кажутся более инициативными. Чтобы проверить, ученые заменили правильные проактивные подсказки на бессмысленные, вроде «Перемотай видео» для задачи с наброском. Модели, выглядевшие проактивными, с радостью хватались за ерунду. LLaVA-NeXT Vicuna даже повысила выбор с 37% до 49% на фейковых вариантах. Вывод: видимость инициативы — это просто склонность к догадкам, а не настоящее понимание.

Подсказки в промтах или истории диалога не решают проблему. Они повышают долю проактивных ответов и точность до 25,8%, но в среднем не выходят за уровень случайности. В 16% случаев модели слепо повторяют проактивные запросы до лимита шагов. История беседы даже ухудшает дело: ИИ копирует действия из нее, не извлекая уроков.
Обучение с подкреплением учит моделей вовремя просить помощи
Но есть хорошие новости. Исследователи доказали, что проактивность можно привить. Они дообучили LLaVA-NeXT-Mistral-7B и Qwen2.5-VL-3B методом Group-Relative Policy Optimization (GRPO) на около 27 000 примерах. Главное: функция награды выше ценит верные ответы, чем просьбы о помощи, — модель запрашивает данные только в настоящей беде.
После дообучения обе модели обошли все 22 оригинальных, включая o4-mini (37,4% и 38,6% против 34,0%). Навык перенесся на новые сценарии. В ChangeIt Qwen2.5-VL-3B подскочила с 12,4% до 55,6%. Но если сбалансировать награду неверно и приравнять просьбы к ответам, модель заспамит запросами, а точность обвалится до 5,4%.
Несмотря на прогресс, разрыв с базовыми условиями велик (40,7% против 75,1%). Ученые выложили ProactiveBench в открытый доступ как старт для моделей, которые осознают пробелы и просят помощи, а не фантазируют.
ИИ-модели не понимают, чего не знают
ProactiveBench подчеркивает тенденцию из свежих исследований ИИ: мультимодальные модели плохо справляются с неопределенностью. Бенчмарк WorldVQA от Moonshot AI показал, что лидеры еле дотягивают до 50% в распознавании объектов на изображениях из-за чрезмерной уверенности.
Исследование Стэнфорда о «миражном эффекте» подтвердило: модели вроде GPT-5 и Gemini 3 Pro уверенно описывают детали и ставят диагнозы без изображений. На обычных тестах они держат 70–80% нормы за счет текстовых шаблонов и знаний, имитируя зрение.
Другие работы повторяют картину. Анализ сложности экзаменационных вопросов выявил, что языковые модели не оценивают свои пределы. Ученые из Университета Сапиенца в Риме методом «Spilled Energy» обнаружили: галлюцинации оставляют следы в вычислениях модели — математика знает об ошибке, даже если ИИ уверен в ответе.