Arcee AI представила Trinity-Large-Thinking — открытую модель для рассуждений, способную соперничать с Claude Opus в задачах агентов. На проект ушла примерно половина всех венчурных средств компании.
Сейчас в сфере открытых больших языковых моделей лидируют китайские команды, такие как Qwen, MiniMax и Zhipu AI. Американский стартап Arcee AI меняет расклад с Trinity-Large-Thinking — моделью под лицензией Apache 2.0 и около 400 миллиардами параметров, созданной специально для работы с агентами. Благодаря архитектуре mixture-of-experts на каждый токен активируется лишь примерно 13 миллиардов параметров, что обеспечивает быструю обработку несмотря на масштаб.
Как сообщает компания, базовую модель обучали на 2048 ускорителях Nvidia B300 в течение 33 дней. Затраты в 20 миллионов долларов составили около половины венчурных инвестиций Arcee AI. «По сути, это самая сильная открытая модель за пределами Китая, появившаяся на рынке», — отметил технический директор Lucas Atkins в блоге к релизу.
Агентные тесты удались, в общем мышлении отставание
Trinity-Large-Thinking выводит чёткий процесс размышлений в особых блоках перед ответом. Модель настроена на использование инструментов, поэтапное планирование и независимые рабочие цепочки.
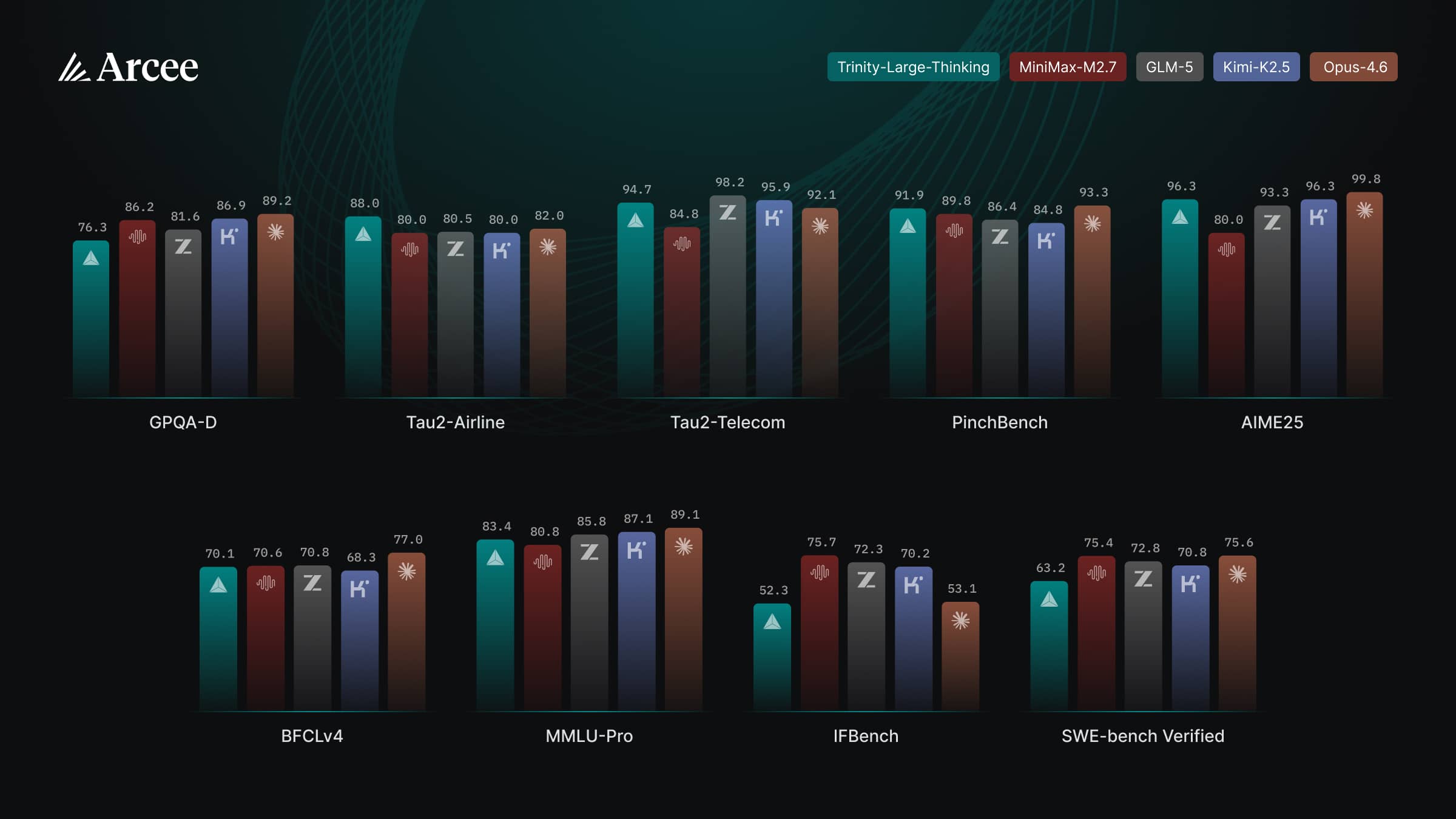
По данным карточки модели на Hugging Face, в агентных тестах показатели высокие: 88 в Tau2-Airline (лидерство), 91,9 в PinchBench (второе место, всего 1,4 балла от Claude Opus 4.6 с 93,3) и 96,3 в AIME25. С общим мышлением другая картина: GPQA-Diamond — 76,3, MMLU-Pro — 83,4, в то время как у Claude Opus 4.6 эти тесты дают 89,2 и 89,1.
Лишь 4 из 256 экспертов работают на токен
Модель построена на mixture-of-experts с 256 специализированными подсетями, из которых на токен задействуется только четыре. Таким образом, из 400 миллиардов параметров активны около 13 миллиардов на шаг вычислений — это экономит ресурсы, не снижая общую мощь. Технический отчёт показывает, что базовая модель достигает результатов на уровне GLM 4.5, хотя та активирует гораздо больше параметров за токен.
Для длинных текстов Trinity-Large-Thinking сочетает два вида слоёв внимания: локальные, охватывающие фрагмент текста, чередуются с глобальными, работающими на весь контекст. Такой подход позволяет расширять окно контекста без резкого роста нагрузки. На деле модель справляется с 512 тысячами токенов, хотя обучали на 256 тысячах. В тесте Needle-in-a-Haystack, проверяющем поиск данных в длинных текстах, при 512K она набрала 0,976.
Собственный метод балансировки спас от коллапса экспертов
На начальных этапах обучения отдельные эксперты выходили из строя. Распределение токенов по подсетям сбивалось, некоторые переставали использоваться, и прогресс останавливался. Причина крылась в стандартном методе балансировки нагрузки: он применял одну и ту же величину коррекции независимо от степени дисбаланса. С 256 экспертами это вызывало бесконечные колебания без устойчивости.
Разработчики создали SMEBU (Soft-clamped Momentum Expert Bias Updates) — подход, где коррекции пропорциональны отклонению и сглаживаются во времени. Плюс ввели сразу пять других мер стабилизации из-за нехватки времени. В итоге весь цикл обучения прошёл ровно, без единого скачка потерь. Такие скачки — частая беда больших моделей, способная сорвать весь процесс.
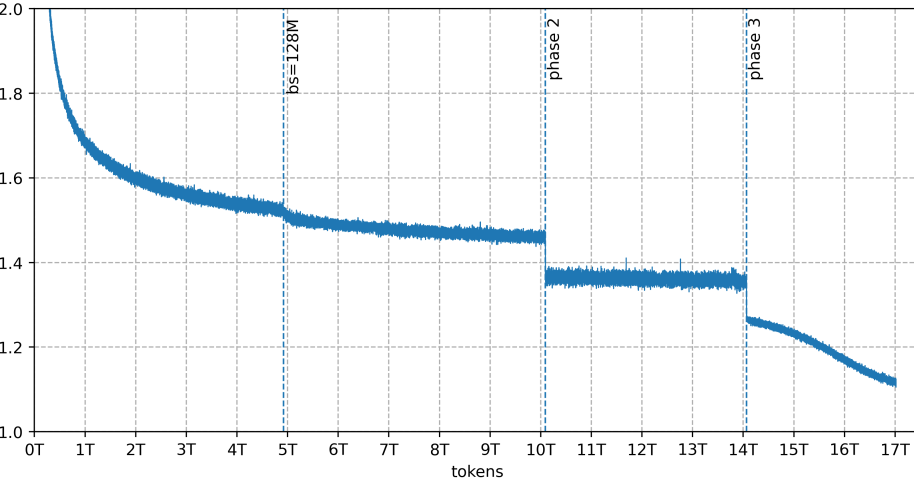
Более 8 триллионов синтетических токенов в обучении
Большая часть данных синтетическая: свыше восьми из 17 триллионов токенов создали другие ИИ, а не взяли с веба. Это 6,5 триллиона переписанного веб-текста, около триллиона многоязычных данных и примерно 800 миллиардов токенов кода. Подготовку данных взяла на себя DatologyAI. Техотчёт называет это одной из крупнейших задокументированных генераций синтетики для предобучения.
GPU-кластеры предоставил Prime Intellect. Поскольку B300 были новыми, возникали сбои, которые исправляли обновлениями прошивки.
Команда также ввела новый способ обработки данных — Random Sequential Document Buffer (RSDB). Обычно длинные документы захватывают несколько шагов подряд и искажают распределение. RSDB случайным образом перемешивает их, что, по техотчёту, сильно снижает колебания между шагами.
Быстрое принятие несмотря на сжатую дообучку
После предобучения модель прошла доработку под навыки вроде работы с инструментами и многошаговых заданий. Однако, как указано в техотчёте, этот этап сократили из-за ограничений по времени на кластере. Arcee AI считает версию предварительной и готовит более полную дообучку для обновления.
Предварительная версия работала на OpenRouter, где за два месяца обработала 3,37 триллиона токенов. Она вошла в топ открытых моделей в США на платформе, по словам Arcee AI. Версия Thinking тоже доступна на OpenRouter и совместима с фреймворками агентов OpenClaw и Hermes Agent.
Незадолго до релиза Arcee AI Google выпустил Gemma 4 — новую линейку открытых моделей под Apache 2.0, частично на базе mixture-of-experts.