Google начинает развертывание свежей модели синтеза речи, построенной на Gemini 3.1 Flash. Разработчики называют ее наиболее естественной и эмоциональной среди всех ранее выпущенных. Главное новшество — аудиотэги, это текстовые инструкции, которые позволяют управлять манерой, скоростью, интонацией и произношением синтезируемого голоса. Поддержка охватывает свыше 70 языков, включая диалоги с несколькими участниками.
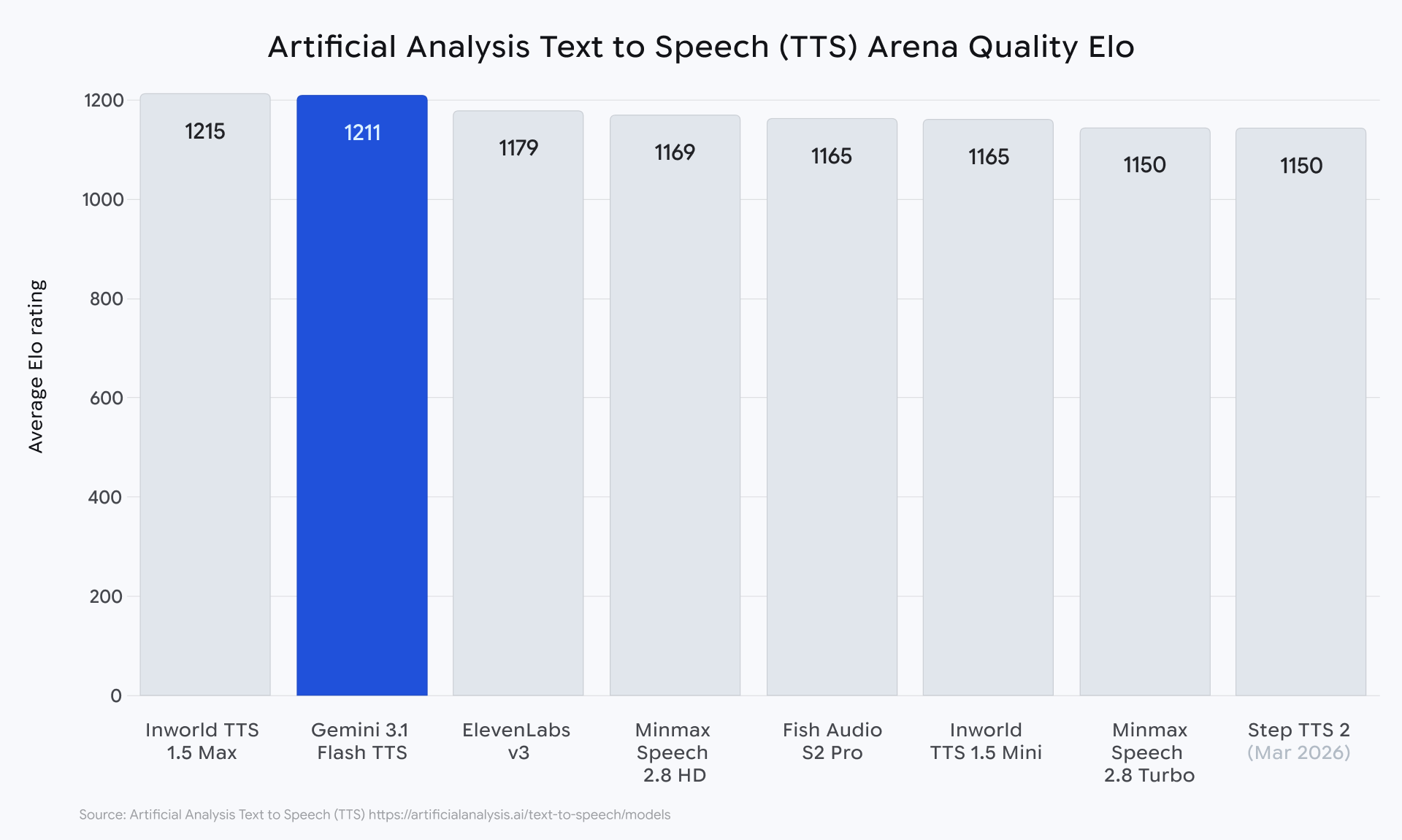
В рейтинге Artificial Analysis модель набрала Elo 1211 и лидирует по балансу качества и стоимости. Она опережает Elevenlabs v3 по общему уровню и уступает только Inworld 1.5 Max.
Gemini 3.1 Flash TTS предлагает бесплатный тариф, однако Google применяет данные для доработки своих сервисов. Платный вариант стоит $1 за миллион токенов входного текста и $20 за миллион токенов выходного аудио. Режим пакетной обработки снижает цены вдвое — до $0.50 и $10 соответственно. На платном тарифе данные не идут на улучшение продуктов.
Модель Gemini 3.1 Flash TTS открыта в режиме превью через Gemini API, Vertex AI для корпоративных клиентов и Google Vids для пользователей Workspace. Любой желающий может протестировать ее бесплатно в Google AI Studio. Вся генерируемая речь содержит водяной знак SynthID для обозначения контента от ИИ.