
Введение
Недавно при разборе банковской выписки таблицы показались слишком громоздкими, а готовые приложения заставляют загружать конфиденциальные данные в облако. Нужен был инструмент, который разбирает расходы, находит подозрительные операции и выдает понятные выводы, не передавая информацию наружу. Так появился этот проект.
Что начиналось как хобби на выходные, превратилось в исследование обработки данных из реальной жизни, применения машинного обучения и возможностей локальных больших языковых моделей. Здесь разберут создание приложения для финансового анализа на Python с использованием vibe-кодинга. Получится освоить навыки, полезные для любых задач по данным — от логов продаж до отзывов клиентов.
В итоге станет ясно:
- Как собрать надежную цепочку подготовки данных для хаотичных CSV-файлов из практики.
- Как подбирать модели машинного обучения при дефиците обучающих примеров.
- Как строить интерактивные графики, которые решают задачи пользователей.
- Как подключить локальную языковую модель для текстовых выводов без ущерба приватности.
Задача: зачем появился этот инструмент
Большинство приложений для личных финансов имеют общий минус: данные уходят из-под контроля. Выгрузка выписок в сервисы приводит к их хранению, обработке и возможному использованию. Инструмент должен был:
- Позволять загружать и разбирать данные сразу.
- Работать полностью локально — без облака и утечек.
- Давать insights от ИИ, а не только статичные диаграммы.
Проект помог освоить ключевые умения для специалистов по данным: борьбу с разными форматами, выбор алгоритмов для малых наборов и создание ИИ-функций с защитой приватности.
Архитектура проекта
Перед кодом — обзор структуры, чтобы понять связи компонентов:
project/├── app.py # Основное приложение Streamlit├── config.py # Настройки (категории, конфиг Ollama)├── preprocessing.py # Автоопределение форматов CSV, нормализация├── ml_models.py # Классификатор транзакций + детектор аномалий Isolation Forest├── visualizations.py # Графики Plotly (круговая, столбцы, временная шкала, тепловая карта)├── llm_integration.py # Интеграция Ollama со стримингом├── requirements.txt # Зависимости├── README.md # Документация с глубокими разбором уроков└── sample_data/├── sample_bank_statement.csv└── sample_bank_format_2.csvКаждый слой разберут по порядку.
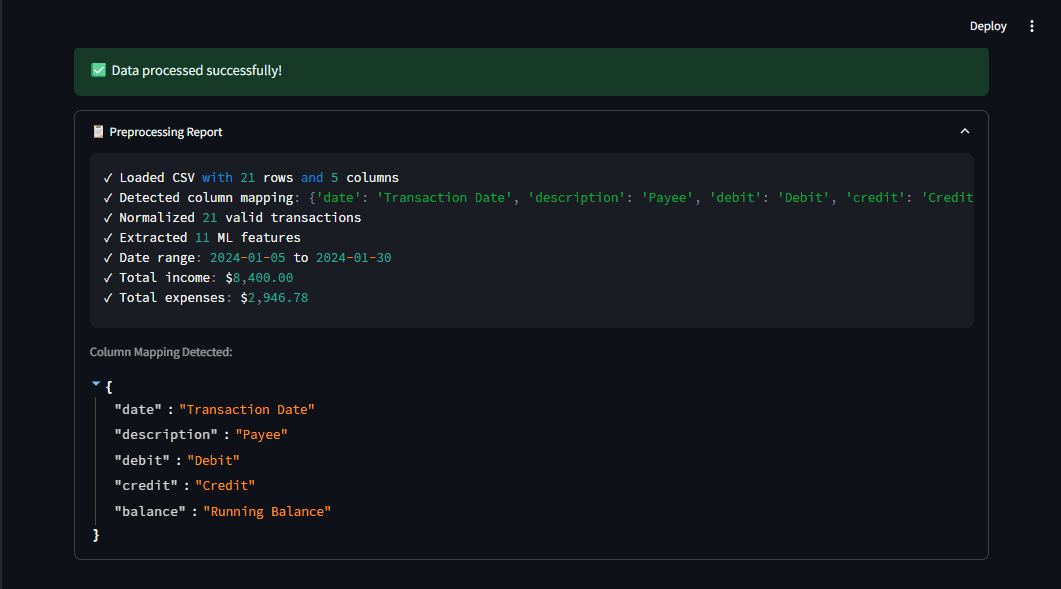
Шаг 1: Надежная цепочка подготовки данных
Первое открытие — данные из жизни всегда беспорядочны. Банки экспортируют CSV по-разному: Chase использует "Transaction Date" и "Amount", Bank of America — "Date", "Payee" плюс отдельные столбцы "Debit" и "Credit". Moniepoint и OPay имеют свои варианты.
Цепочка подготовки обязана справляться с этим автоматически.
Автоопределение соответствий столбцов
Система на основе шаблонов распознает столбцы независимо от названий. Регулярные выражения сопоставляют их со стандартными полями.
import re
COLUMN_PATTERNS = {
"date": [r"date", r"trans.*date", r"posting.*date"],
"description": [r"description", r"memo", r"payee", r"merchant"],
"amount": [r"^amount$", r"transaction.*amount"],
"debit": [r"debit", r"withdrawal", r"expense"],
"credit": [r"credit", r"deposit", r"income"],
}
def detect_column_mapping(df):
mapping = {}
for field, patterns in COLUMN_PATTERNS.items():
for col in df.columns:
for pattern in patterns:
if re.search(pattern, col.lower()):
mapping[field] = col
break
return mappingСуть в адаптации к вариациям, а не к фиксированным форматам. Подходит для любых CSV с типичными финансовыми терминами.
Нормализация к единой схеме
После распознавания все приводят к общему виду. Банки с раздельными debit/credit объединяют в один столбец amount (отрицательный для трат, положительный для доходов):
if "debit" in mapping and "credit" in mapping:
debit = df[mapping["debit"]].apply(parse_amount).abs() * -1
credit = df[mapping["credit"]].apply(parse_amount).abs()
normalized["amount"] = credit + debitГлавный вывод: нормализуйте данные на старте. Это упрощает дальнейшую работу — от создания признаков до моделей и графиков.
Шаг 2: Выбор моделей машинного обучения при малом объеме данных
Вторая сложность — отсутствие больших размеченных наборов. Пользователи загружают свои выписки, так что нужны алгоритмы для небольших сэмплов с поддержкой правил.
Классификация транзакций: гибридный метод
Вместо чистого ML применили комбинацию:
- Сопоставление по правилам для ясных случаев (например, "WALMART" → продукты).
- Шаблоны для неоднозначных операций.
SPENDING_CATEGORIES = {
"groceries": ["walmart", "costco", "whole foods", "kroger"],
"dining": ["restaurant", "starbucks", "mcdonald", "doordash"],
"transportation": ["uber", "lyft", "shell", "chevron", "gas"],
# ... другие категории
}
def classify_transaction(description, amount):
for category, keywords in SPENDING_CATEGORIES.items():
if any(kw in description.lower() for kw in keywords):
return category
return "income" if amount > 0 else "other"Система запускается без обучения и легко настраивается.
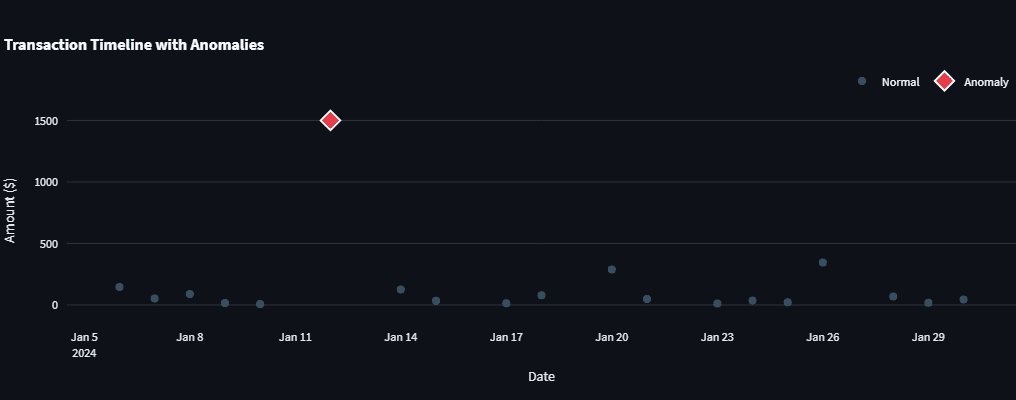
Обнаружение аномалий: преимущества Isolation Forest
Для подозрительных трат требовался алгоритм, который:
- Работает на малых наборах (не глубокое обучение).
- Не зависит от распределения данных (не просто Z-score).
- Дает быстрые предсказания для интерфейса.
Isolation Forest из scikit-learn подошел идеально. Он изолирует аномалии случайными разбиениями: редкие и отличные точки требуют меньше разделов.
from sklearn.ensemble import IsolationForest
detector = IsolationForest(
contamination=0.05, # Ожидаем ~5% аномалий
random_state=42
)
detector.fit(features)
predictions = detector.predict(features) # -1 = аномалияДобавили Z-score для явных выбросов. Z-score показывает расстояние от среднего в стандартных отклонениях:
z = (x - μ) / σ
Комбинация ловит больше, чем каждый метод по отдельности.
Главный вывод: простые подходящие алгоритмы часто лучше сложных при дефиците данных.
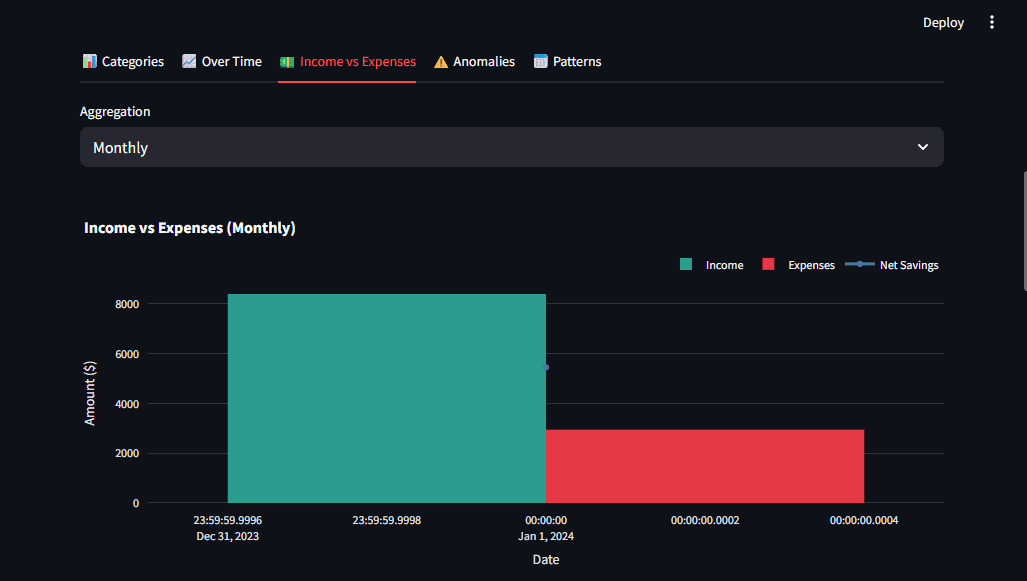
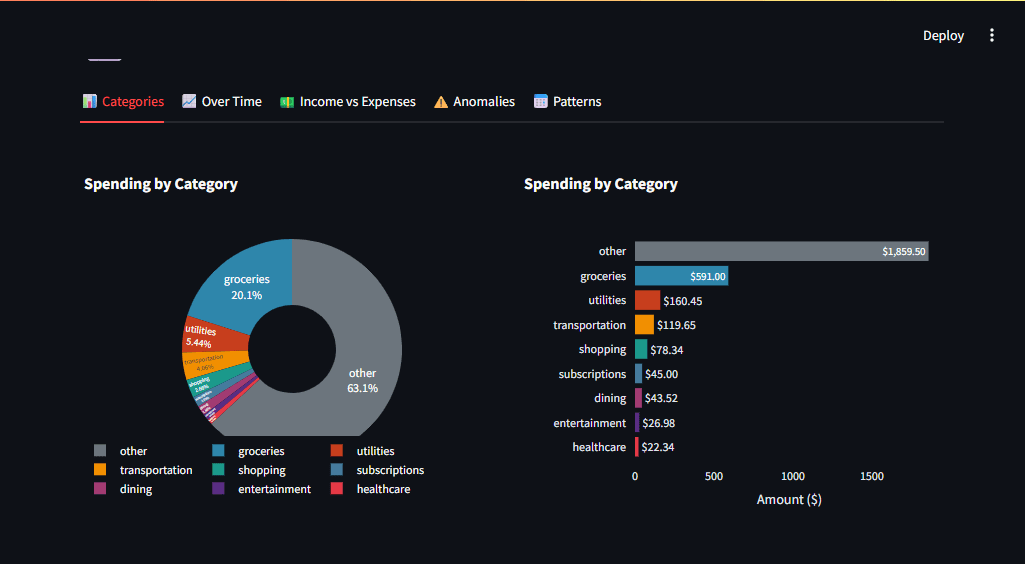
Шаг 3: Графики, которые решают вопросы
Визуализации обязаны давать ответы, а не просто отображать цифры. Plotly выбрали за интерактивность, позволяющую пользователям самим копать глубже. Принципы:
- Единая цветовая схема: красный для трат, зеленый для доходов.
- Сравнения для контекста: доходы рядом с расходами.
- Постепенное раскрытие: обзор сначала, детали по клику.
Разбивка трат — в виде пончика для чистоты:
import plotly.express as px
fig = px.pie(
category_totals,
values="Amount",
names="Category",
hole=0.4,
color_discrete_map=CATEGORY_COLORS
)Streamlit упрощает вставку через st.plotly_chart() для отзывчивой панели.
Шаг 4: Локальная большая языковая модель для текстовых выводов
Последний элемент — человекочитаемые insights. Подключили Ollama для локального запуска LLM. Почему не OpenAI или Claude?
- Приватность: банковские данные не уходят с машины.
- Экономия: безлимитные запросы, ноль затрат на API.
- Скорость: без сетевых задержек (генерация занимает секунды).
Стриминг для удобства
LLM генерирует медленно, но Streamlit показывает токены по мере поступления, сокращая ощущение ожидания. Пример с requests:
import requests
import json
def generate(self, prompt):
response = requests.post(
f"{self.base_url}/api/generate",
json={"model": "llama3.2", "prompt": prompt, "stream": True},
stream=True
)
for line in response.iter_lines():
if line:
data = json.loads(line)
yield data.get("response", "")В Streamlit — st.write_stream().
st.write_stream(llm.get_overall_insights(df))Промты для финансовых данных
Качество вывода зависит от структурированного промта с реальными цифрами:
prompt = f"""
Analyze this financial summary:
- Total Income: ${income:,.2f}
- Total Expenses: ${expenses:,.2f}
- Top Category: {top_category}
- Largest Anomaly: {anomaly_desc}
Provide 2-3 actionable recommendations based on this data."""Конкретные значения делают insights точными.
Запуск приложения
Установка проста. Нужен Python, затем:
pip install -r requirements.txt
# Опционально, для insights ИИ
ollama pull llama3.2
streamlit run app.pyЗагрузите CSV банка (формат определяется сам), и панель покажет категории, аномалии и insights от ИИ.
Итоги
Проект показал: рабочий прототип — только старт. Настоящее понимание приходит при разборе причин успеха каждого блока:
- Автоопределение столбцов нужно, потому что данные не следуют схеме. Гибкая цепочка экономит часы на ручной чистке.
- Isolation Forest подходит для малых наборов. Глубокое обучение не всегда обязательно.
- Локальные LLM важны для приватности и затрат. Их запуск стал реальностью.
Эти принципы работают за пределами финансов: для продаж, логов серверов или измерений. Надежная подготовка, практичные модели и ИИ с защитой данных пригодятся везде.