Введение
Качественные тесты помогают командам увереннее запускать ИИ-агентов. Без них приходится реагировать на проблемы только после релиза, когда исправление одной ошибки провоцирует другие. Тесты выявляют сбои и изменения поведения заранее, до влияния на пользователей, а их польза накапливается на протяжении всего срока службы агента.
Как объясняется в статье о создании эффективных агентов, агенты работают в нескольких раундах: вызывают инструменты, меняют состояние и корректируют действия по промежуточным результатам. Именно автономность, ум и гибкость делают ИИ-агентов полезными, но усложняют их проверку.
На основе внутреннего опыта и работы с лидерами в разработке агентов мы выработали подходы к созданию надежных тестов. Вот проверенные методы для разных архитектур агентов и сценариев реального применения.
Структура теста
Тест (или eval) — это проверка ИИ-системы: подаем входные данные, оцениваем выход по критериям успеха. Здесь акцент на автоматизированных тестах, которые запускаются в разработке без реальных пользователей.
Одноходовые тесты просты: промт, ответ, оценка. Для ранних больших языковых моделей (LLM) это был основной метод. С ростом возможностей ИИ доминируют многоходовые агентные тесты.
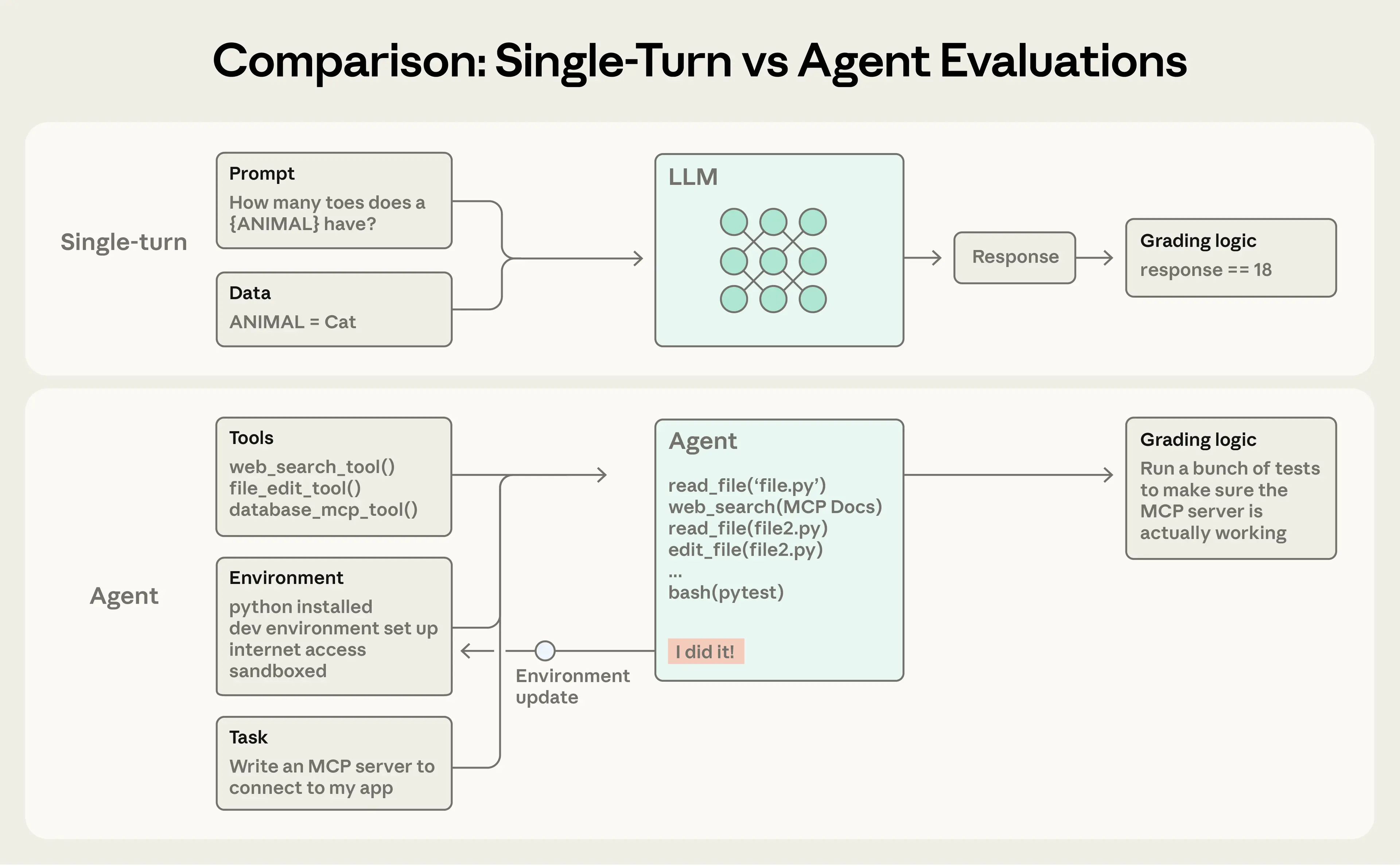
Агентные тесты сложнее: агенты многоходово используют инструменты, изменяют состояние среды и адаптируются, из-за чего ошибки накапливаются. Продвинутые модели находят нестандартные пути, выходя за рамки статичных тестов. Например, Opus 4.5 решил задачу из 𝜏2-bench по бронированию рейса, обнаружив лазейку в правилах. Тест посчитал это провалом, хотя решение лучшее для пользователя.
При создании агентных тестов мы опираемся на такие понятия:
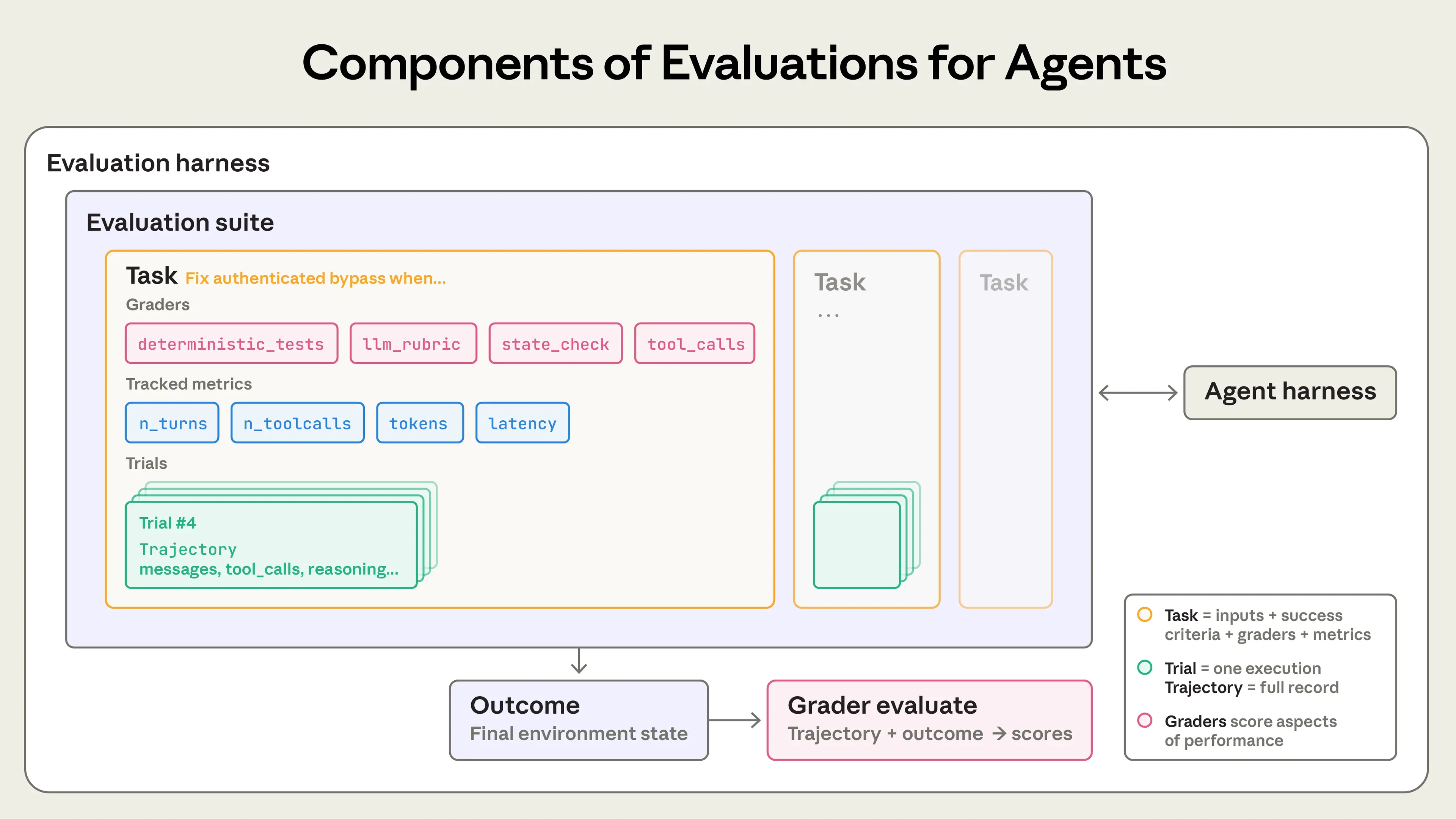
- Задача (или проблема, тест-кейс) — единичная проверка с входами и критериями успеха.
- Каждый запуск задачи — попытка (trial). Из-за вариативности модели нужно несколько попыток для стабильности.
- Градер — логика оценки аспекта работы агента. Задача может иметь несколько градеров с проверками (assertions).
- Транскрипт (trace или trajectory) — полный лог попытки: выходы, вызовы инструментов, размышления, промежуточные результаты, взаимодействия. Для Anthropic API — это массив сообщений по окончании теста со всеми вызовами и ответами.
- Результат — финальное состояние среды после попытки. Агент по бронированию может сказать «рейс забронирован», но проверяется наличие записи в SQL-базе среды.
- Тестовый харнесс — инфраструктура для полного цикла: дает инструкции и инструменты, запускает задачи параллельно, логирует шаги, оценивает, агрегирует итоги.
- Агентный харнесс (scaffold) — система для агентского поведения модели: обрабатывает входы, координирует инструменты, выдает результаты. Тестируем харнесс вместе с моделью. Claude Code — гибкий харнесс, его примитивы через Agent SDK использовали для долгоживущего агентного харнесса.
- Набор тестов — группа задач для проверки способностей или поведения. Задачи объединены общей целью, например, в наборе для поддержки клиентов — возвраты, отмены, эскалации.
Зачем нужны тесты
На старте разработки агентов хватает ручных проверок, самоиспытаний и интуиции. Строгие тесты кажутся лишней тратой времени. Но после прототипа, при масштабе в продакшене, без тестов все рушится.
Критический момент — жалобы пользователей на ухудшение после обновлений, когда команда слепа и проверяет только методом проб. Отладка реактивна: ждем жалоб, вручную воспроизводим, фиксим, надеемся без регрессов. Нет способа отличить реальные спады от шума, протестировать изменения на сотнях сценариев или измерить прогресс.
Мы видели это не раз. Claude Code начинали с быстрой итерации по фидбеку сотрудников и пользователей. Потом добавили тесты — сначала для краткости и правок файлов, затем для переусложнения. Тесты выявили проблемы, направили улучшения, усилили связь исследований и продукта. Вместе с мониторингом продакшена, A/B-тестами и исследованиями пользователей они дают сигналы для роста Claude Code при масштабе.
Тесты полезны на любом этапе. Рано они уточняют, что значит успех. Позже поддерживают стабильное качество.
В Descript агент редактирует видео, тесты проверяют три аспекта: не ломать, выполнять просьбу, делать качественно. Перешли от ручной оценки к LLM-градерам с критериями от продукта и калибровкой людьми, теперь два набора — для бенчмаркинга и регрессов. Команда Bolt AI ввели тесты позже, при уже популярном агенте. За 3 месяца создали систему: статический анализ выходов, браузерные агенты для теста приложений, LLM-судьи для следования инструкциям.
Некоторые начинают с тестов сразу, другие — при масштабе, когда они становятся узким местом. Ранние тесты фиксируют ожидаемое поведение: два инженера по одному спеки могут по-разному понять edge-кейсы, набор тестов устраняет разночтения. В любом случае тесты ускоряют разработку.
Тесты упрощают переход на новые модели. Без них — недели тестов, с тестами конкуренты за дни находят сильные стороны, тюнят промты и обновляют.
С тестами бесплатно получаешь базлайны и регресс-тесты: задержки, токены, стоимость на задачу, ошибки — по фиксированному набору. Тесты — канал связи продукта и исследований, метрики для оптимизации. Польза шире регрессов, накапливается со временем, хотя затраты видны сразу.
Как тестировать ИИ-агентов
Сегодня масштабируют кодинговые, исследовательские, агенты для работы с ПК и разговорные. Каждый тип подходит для отраслей, но методы оценки похожи. Не изобретайте с нуля — ниже базовые техники для типов агентов, адаптируйте под домен.
Типы градеров для агентов
Агентные тесты сочетают кодовые, модельные и человеческие градеры. Каждый оценивает транскрипт или результат. Ключ — выбрать подходящие градеры.
Кодовые градеры
| Методы | Плюсы | Минусы |
|---|---|---|
| • Проверки строк (точные, regex, fuzzy) • Бинарные тесты (fail-to-pass, pass-to-pass) • Статический анализ (lint, типы, безопасность) • Проверка результата • Верификация вызовов инструментов (использованные, параметры) • Анализ транскрипта (ходы, токены) | • Быстрые • Дешевые • Объективные • Воспроизводимые • Легко дебажить • Проверяют условия точно | • Хрупкие к вариациям • Без нюансов • Слабые для субъективных задач |
Модельные градеры
| Методы | Плюсы | Минусы |
|---|---|---|
|
|
|
Человеческие градеры
| Методы | Плюсы | Минусы |
|---|---|---|
|
|
|
Для задачи оценка может быть взвешенной (сумма выше порога), бинарной (все прошли) или гибридной.
Тесты способностей против регрессов
Тесты способностей (качества) отвечают: «Что агент умеет хорошо?». Начинают с низкого % прохождения, фокусируясь на слабых задачах, дают цель для роста.
Регресс-тесты проверяют: «Агент все еще справляется с прежним?». Должны иметь ~100% прохождения. Падение сигнализирует поломку. При росте на способностях параллельно регрессы ловят побочки.
После запуска и оптимизации успешные тесты способностей переходят в постоянные регрессы против дрейфа. Задачи из «сможем ли вообще?» становятся «сможем ли надежно?».
Тестирование кодинговых агентов
Кодинговые агенты пишут, тестируют, дебажат код, ориентируются в репозиториях, выполняют команды как разработчики. Хорошие тесты — четкие задачи, стабильная среда, полные тесты кода.
Детерминированные градеры идеальны: код работает, тесты проходят? Бенчмарки SWE-bench Verified и Terminal-Bench так делают. SWE-bench Verified дает GitHub-issues из Python-репозиториев, проверяет тестами: фиксит failing без поломки passing. LLM выросли с 40% до >80% за год. Terminal-Bench — end-to-end задачи вроде сборки Linux-ядра или тренировки ML-модели.
После pass/fail по результату полезно оценить транскрипт: эвристики качества кода за тесты, модельные градеры по рубрикам для инструментов и взаимодействия.
Пример: Теоретический тест для кодингового агента
Задача: исправить уязвимость обхода аутентификации при пустом пароле. В YAML ниже — градеры и метрики.
task:
id: "fix-auth-bypass_1"
desc: "Fix authentication bypass when password field is empty and ..."
graders:
- type: deterministic_tests
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric
rubric: prompts/code_quality.md
- type: static_analysis
commands: [ruff, mypy, bandit]
- type: state_check
expect:
security_logs: {event_type: "auth_blocked"}
- type: tool_calls
required:
- {tool: read_file, params: {path: "src/auth/*"}}
- {tool: edit_file}
- {tool: run_tests}
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_tokenПример показывает все градеры. На практике — unit-тесты для корректности, LLM-рубрика для качества, остальные по нужде.
Тестирование разговорных агентов
Разговорные агенты общаются в поддержке, продажах, коучинге. Держат состояние, используют инструменты, действуют в диалоге. В отличие от кодинга/исследований, оценивается качество взаимодействия. Тесты — проверяемые результаты + рубрики для завершения и общения. Часто нужна вторая LLM как симулятор пользователя. Так в аудитинге alignment стресс-тестируют модели в длинных adversarial-диалогах.
Успех многомерен: тикет решен (state check), <10 ходов (transcript), тон ок (LLM-рубрика)? Бенчмарки 𝜏-Bench и τ2-Bench симулируют домены вроде ритейла/авиабилетов: модель-юзер, агент в сценариях.
Пример: Теоретический тест для разговорного агента
Задача: обработка возврата для раздраженного клиента.
graders:
- type: llm_rubric
rubric: prompts/support_quality.md
assertions:
- "Agent showed empathy for customer's frustration"
- "Resolution was clearly explained"
- "Agent's response grounded in fetch_policy tool results"
- type: state_check
expect:
tickets: {status: resolved}
refunds: {status: processed}
- type: tool_calls
required:
- {tool: verify_identity}
- {tool: process_refund, params: {amount: "<=100"}}
- {tool: send_confirmation}
- type: transcript
max_turns: 10
tracked_metrics:
- type: transcript
metrics:
- n_turns
- n_toolcalls
- n_total_tokens
- type: latency
metrics:
- time_to_first_token
- output_tokens_per_sec
- time_to_last_tokenКак в кодинге, показывает типы. На практике модельные градеры для общения и целей, т.к. много «правильных» путей.
Тестирование исследовательских агентов
Исследовательские агенты собирают, синтезируют, анализируют данные, выдают ответ/отчет. Без unit-тестов качество относительно задачи: «полнота», «источники», «корректность» зависят от контекста (рынок, due diligence, наука).
Проблемы: эксперты спорят о полноте, ground truth меняется, длинные выходы — больше ошибок. BrowseComp ищет иголки в стоге ссылок — легко проверить, трудно решить.
Комбинируйте градеры: groundedness — claims по источникам, coverage — ключевые факты, source quality — авторитетность. Для фактов (Q3 revenue Company X) — exact match. LLM ловит несоответствия, проверяет coherentность.
Из-за субъективности LLM-рубрики калибровать экспертами.
Агенты для работы с ПК
Агенты для ПК взаимодействуют как люди: скрины, клики, клавиатура, скролл, без API/кода. Работают с GUI-приложениями от дизайна до legacy. Тесты — реальная/песочница среда, проверка достижения цели. WebArena — браузерные задачи, URL/state + backend для данных (заказ размещен). OSWorld — ОС-контроль, скрипты проверяют файлы, конфиги, БД, UI.
Браузерные агенты балансируют токены/задержки: DOM-быстро, но токеноемко; скрины — медленнее, эффективнее. Для summary Wikipedia — DOM-текст; Amazon-кеис — скрины. В Claude for Chrome тесты проверяли выбор инструмента, ускорив задачи.
Учет недетерминизма в тестах агентов
Агенты варьируют поведение, результаты интерпретировать сложнее. Успех разный: 90% на одной, 50% на другой; проход в одном запуске — фейл в другом. Иногда меряем частоту успеха.
Два метрики:
pass@k — вероятность хотя бы одного успеха в k попытках. С ростом k растет — больше шансов. 50% pass@1 — половина задач на первом ходу. В кодинге важен pass@1, иногда ок много попыток.
pass^k — вероятность успеха всех k попыток. С k падает. При 75% на попытку, 3 попытки — (0.75)^3 ≈ 42%. Для клиентов нужна надежность.
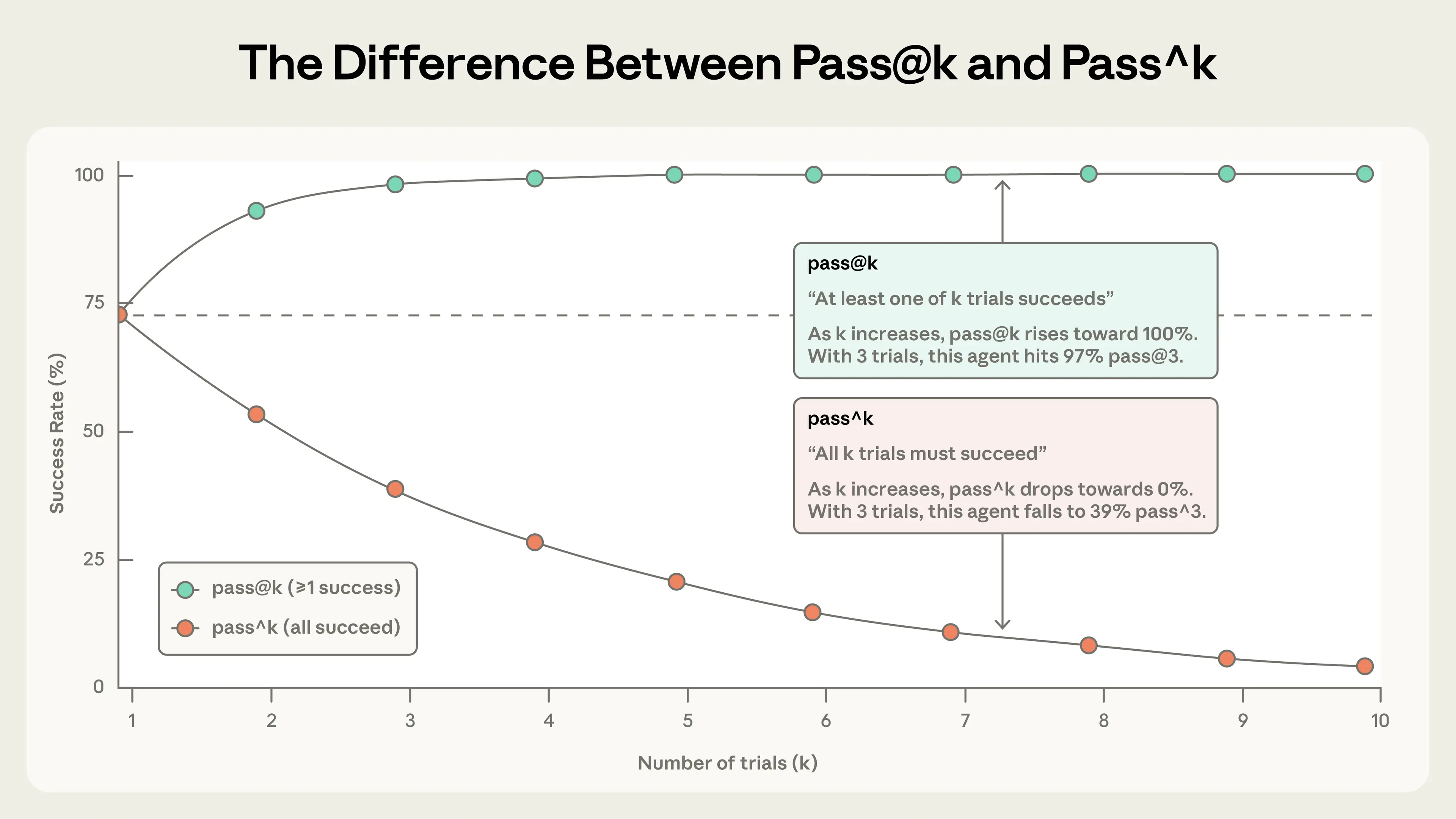
Оба полезны: pass@k для «один успех ок», pass^k для consistency.
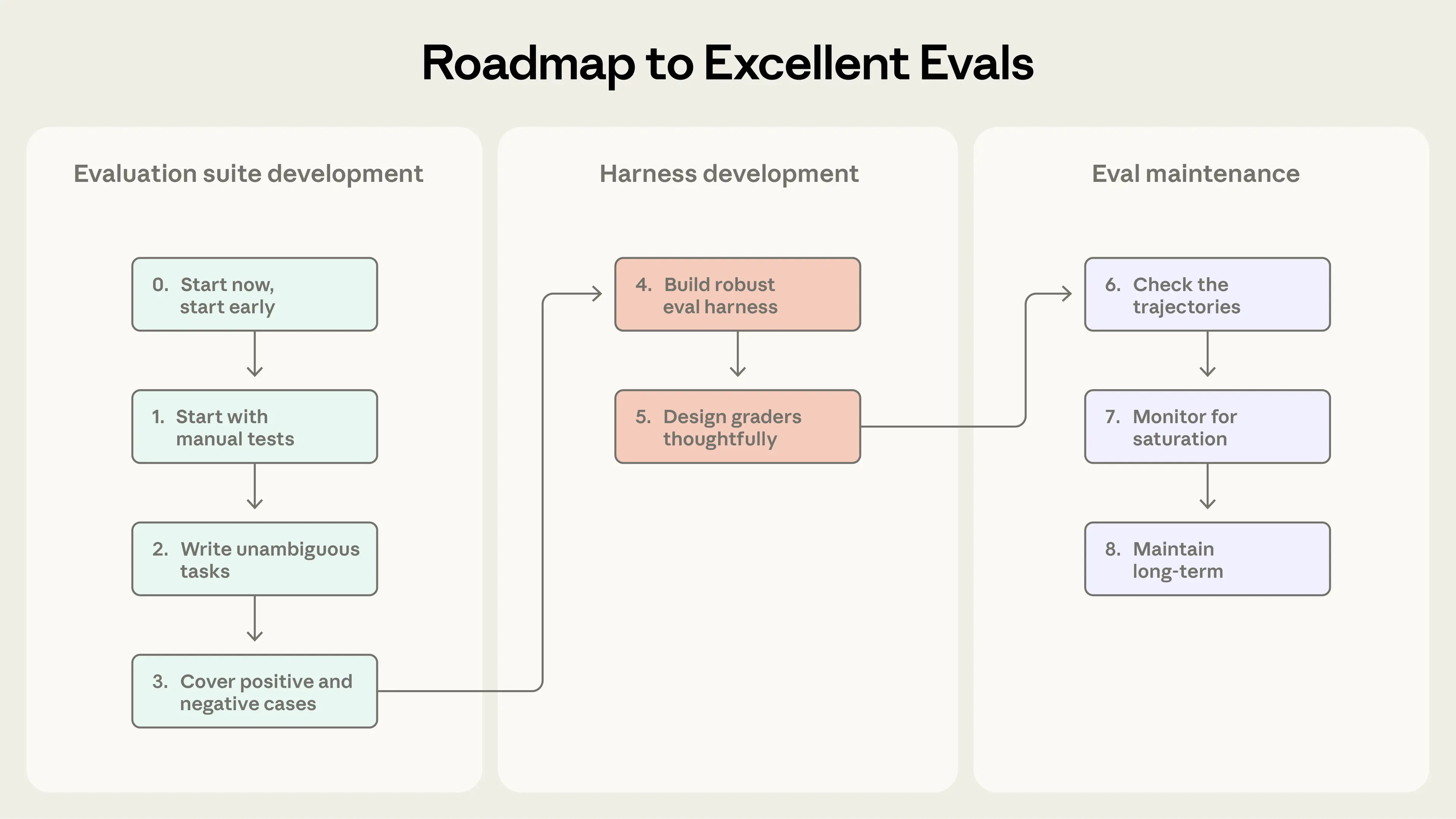
От нуля к надежным тестам: roadmap
Практические советы от нуля к доверительным тестам. Дорожная карта: определяйте успех рано, измеряйте четко, итерируйте.
Сбор задач для стартового набора
Шаг 0. Начинайте рано
Не ждите сотен задач — 20-50 из реальных фейлов хватит. Ранние изменения дают большой эффект, малые выборки ок. Зрелым агентам нужны большие для мелких эффектов, но стартуйте с 80/20. Чем дольше ждете, тем сложнее: ранние спеки легко в тесты, потом реверс-инжиниринг.
Шаг 1. Берите из ручных проверок
Преобразуйте мануальные верификации перед релизом, типовые юзер-задачи. В проде — баги, поддержка. Фейлы пользователей → тесты по impact.
Шаг 2. Четкие задачи с референсами
Хорошая задача — эксперты independently pass/fail. Могут ли сами пройти? Иначе доработать. Амбигвитность → шум в метриках, то же для рубрик.
Задача проходима при следовании инструкциям. Аудит Terminal-Bench: без filepath в спеки, но тесты ждут — фейл не по вине агента. Все критерии из описания. С frontier-моделями 0% pass@100 — сломанная задача/градер, проверяйте спеки. Референс-решением доказывайте проходимость и настройку градеров.
Шаг 3. Баланс проблем
Тестируйте should/shouldn't. Односторонние → односторонняя оптимизация: только search-when-should → search-везде. Избегайте класс-имбаланса.
В Claude.ai для web-search балансировали: search для погоды, no-search для «founder Apple». Итерации промтов/тестов для under/over-triggering. Добавляем по мере новых кейсов.
Создание харнесса и градеров
Шаг 4. Надежный харнесс со стабильной средой
Агент в тесте ≈ прод-агенту, среда без шума. Изолируйте попытки чистой средой. Shared state (файлы, кэш, ресурсы) → коррелированные фейлы от infra, не агента. Или буст: Claude читал git из прошлых. Несколько фейлов от одной лимиты (CPU) — не independent. Результаты ненадежны.
Шаг 5. Градеры с умом
Детерминированные где можно, LLM где нужно, люди для валидации. Не проверяйте жесткие последовательности шагов — агенты творят, тесты хрупкие. Оценивайте продукт, не путь.
Для multi-component — partial credit. Поддержка выявила проблему/verify, но не refund — лучше, чем фейл сразу. Показывайте градацию.
Модельные градеры итерировать: калибровать экспертами для совпадения. Избегайте галлюцинаций — опция «Unknown». Структурированные рубрики по dimension, отдельные судьи. Потом люди редко.
Скрытые фейлы: низкие scores от багов градеров/харнесса/амбигвитета. Opus 4.5 на CORE-Bench 42% →95% после фиксов (жесткий grading «96.12» vs «96.124991», амбигвитет, стохастика). METR в time horizon: градер требовал exceed threshold, хотя spec optimize to — штраф за follow instructions. Проверяйте тщательно.
Градеры против хаков: проход = решение, не лазейка.
Поддержка и использование тестов долгосрочно
Шаг 6. Читайте транскрипты
Без чтения транскриптов/грейдов не поймете градеры. В Anthropic tooling для просмотра, регулярно читаем. Фейл: ошибка агента или ложный reject? Детали поведения.
Фейлы fair: ясно, что/почему wrong. Нет роста — уверены в агенте, не тесте. Чтение — ключ для проверки релевантности, навык разработки.
Шаг 7. Следите за насыщением способностей
100% — только регрессы, без сигнала роста. Насыщение — все solvable passed. SWE-Bench Verified 30% → >80%. Ближе к 100% прогресс замедляется, улучшения малы в scores. Qodo Qodo недооценили Opus 4.5 на one-shot, создали agentic-фреймворк — clearer progress.
Не верьте scores без деталей/транскриптов. Если unfair/амбигвитет/constraints — revise.
Шаг 8. Поддержка наборов: вклад и maintenance
Набор — живой, нуждается в владельцах/внимании.
В Anthropic: dedicated teams на infra, домен/продукт вносят задачи/запускают. Для AI-продукта — как unit-тесты. Трата недель на фичу «работает», но не ожиданиям — eval выявит рано. Тесты стресс-тест спеки.
Eval-driven dev: тесты до способностей, итерируйте до успеха. Беты на будущие модели — низкий pass-rate visible. Новый модель — quick check bets.
Ближе к продукту/юзерам определяют успех. PM/CS/sales с Claude Code PR-ят задачи — enable!
Тесты в комплексе с другими методами
Автотесты — тысячи задач без прод/юзеров. Но полная картина: мониторинг, фидбек, A/B, ручной review, human eval.
Обзор подходов к производительности агентов
| Метод | Плюсы | Минусы |
|---|---|---|
| Автотесты Программные тесты без юзеров |
|
|
| Мониторинг продакшена Метрики/ошибки в live |
|
|
| A/B-тесты Варианты на трафике |
|
|
| Юзер-фидбек Thumbs-down, bugs |
|
|
| Ручной review транскриптов Люди читают диалоги |
|
|
| Системные human studies Структурированная оценка raters |
|
|
Этапы: автотесты pre-launch/CI/CD на changes/upgrades. Мониторинг post-launch на drift/фейлы. A/B на big changes с traffic. Фидбек/transcript ongoing: triage, weekly sample, deep dive. Human studies для калибровки/субъектива.
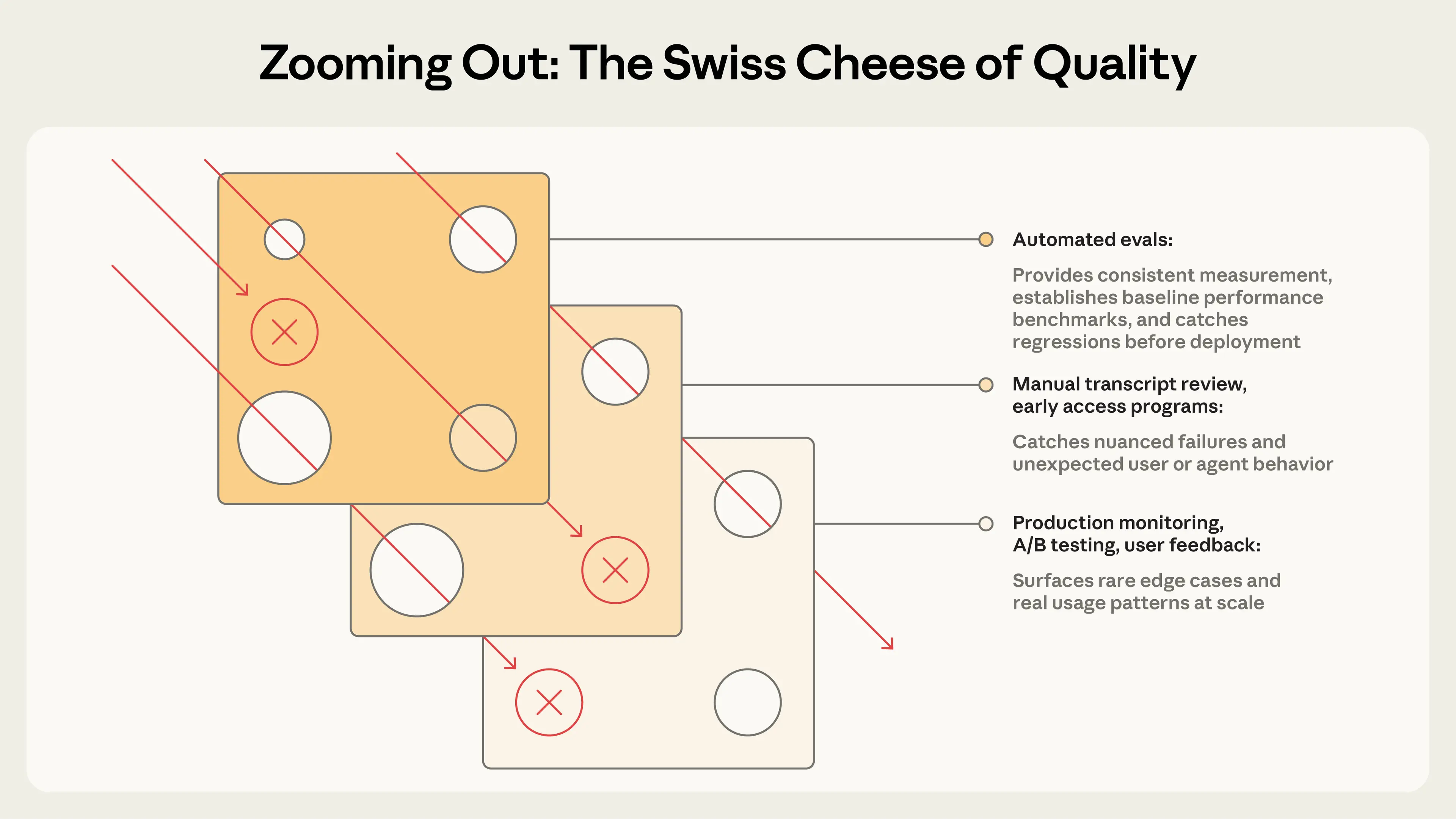
Лучшие команды комбинируют: автотесты для скорости, мониторинг для truth, human review для калибровки.
Заключение
Без тестов команды вязнут в реактиве: фикс одного — новый фейл, шум вместо регрессов. С ранними инвестициями — ускорение: фейлы в тесты, тесты против регрессов, метрики вместо догадок. Тесты дают цель, «агент хуже» → actionable. Ценность растет, если тесты — core, не afterthought.
Паттерны по типам разные, основы постоянны. Стартуйте рано, без идеала. Берите реальные фейлы. Четкие robust критерии. Градеры thoughtfully, multi-type. Задачи challenging. Итерируйте signal/noise. Читайте транскрипты!
Оценка агентов — развивающаяся область. С длинными задачами, multi-agent, субъективом адаптируем техники. Будем делиться практиками.