
Введение
Если вы взялись за эту статью, то наверняка уже знакомы с основами Python и интересуетесь data science. Возможно, вы пробовали писать циклы или даже работали с библиотекой вроде Pandas. Но перед вами типичная дилемма: область огромна, и разобраться, с чего начать и что можно отложить, бывает непросто.
Этот материал как раз для таких случаев. Он помогает пробиться сквозь информационный шум и предлагает четкий план действий. В основе data science лежит задача извлекать из данных знания и выводы, которые ведут к реальным решениям и шагам. По ходу чтения вы поймете, как превращать сырые данные в полезный интеллект.
Мы разберем главный вопрос: "С чего начать изучение data science?" Также расскажем о темах, которые стоит отложить, чтобы не тратить время зря. В итоге вы получите roadmap на 2026 год — практичный, целенаправленный и ориентированный на трудоустройство.
Основная философия data science
Прежде чем углубляться в инструменты, стоит усвоить ключевой принцип, который определяет многое в data science. Речь о правиле 80/20, или принципе Парето: 80% результатов приносят 20% усилий.
В обучении это значит, что 20% знаний и инструментов хватит для 80% повседневных задач. Новички часто ошибаются, пытаясь освоить все алгоритмы, библиотеки и математические доказательства — от этого быстро устают.
Успешный специалист в data science ставит во главу угла навыки с максимальным эффектом. По опыту отрасли, формула проста: создайте 2 развернутых проекта, напишите 3 поста в LinkedIn и подавайте 50 заявок в неделю — это даст 3–5 собеседований в месяц. Так работает правило 80/20 на практике: акцент на ключевых действиях с большим отдачей.
Главное — осваивать навыки в порядке их применения на работе и подтверждать каждый проектным заданием. Такой подход отличает тех, кто собирает сертификаты, от тех, кого берут на работу.
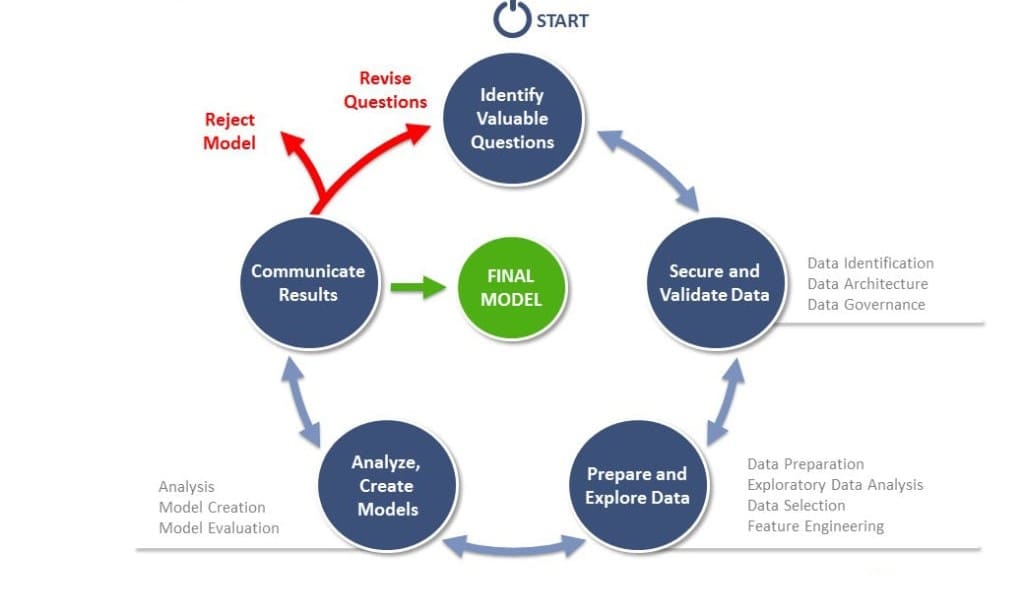
Четыре типа data science
Для надежной базы нужно понять масштаб области. Когда спрашивают "Какие бывают 4 типа data science?" или "Какие 4 столпа аналитики данных?", обычно имеют в виду четыре уровня зрелости аналитики. Эти столпы показывают, как шаг за шагом извлекать ценность из данных.
Знание их даст рамку для любой задачи.
Столп 1: Дескриптивная аналитика
Отвечает на вопрос "Что произошло?". Здесь суммируют прошлые данные, чтобы выявить тенденции. Например, подсчет среднего объема продаж за месяц или коэффициента конверсии клиентов за квартал — это дескриптивная аналитика. Она дает общую картину событий.
Столп 2: Диагностическая аналитика
Разбирает "Почему это произошло?". Здесь ищут корень проблемы. Если отток клиентов вырос, диагностика покажет, сосредоточен ли он в определенном регионе, типе продукта или сегменте аудитории.
Столп 3: Предиктивная аналитика
Прогнозирует "Что вероятно случится?". Здесь подключается машинное обучение. На основе закономерностей в прошлом строят модели для предсказаний. Классика — вероятность ухода конкретного клиента в ближайшие месяцы.
Столп 4: Прескриптивная аналитика
Советует "Что делать?". Самый сложный уровень. Использует симуляции и оптимизацию для рекомендаций. Например, укажет, какое промо-предложение лучше удержит клиента на грани ухода.
В обучении начинайте с дескриптивной аналитики и постепенно переходите к предиктивной и прескриптивной.
Ключевые навыки для начала
Теперь к сути: с чего стартовать в data science? По актуальным roadmap отрасли, первые два месяца уйдут на "навыки выживания".
Программирование и обработка данных
- Углубите основы Python. Поскольку вы уже знакомы с языком, сосредоточьтесь на функциях, модулях и виртуальных окружениях. Python лидирует в отрасли благодаря богатым библиотекам и масштабируемости.
- Освойте Pandas для манипуляций с данными. Это обязательно. Уверенно работайте с загрузкой (
read_csv), пропусками, объединением наборов и переформатированием черезgroupbyиpivot_table. - Разберитесь с NumPy. Начните с массивов и векторизованных операций — на них строятся многие библиотеки.
Исследование данных и визуализация
- Исследовательский анализ данных (EDA). Это разбор наборов на ключевые характеристики, часто визуально. Учитесь проверять распределения, корреляции и взаимодействия признаков.
- Визуализация через Matplotlib и Plotly. Делайте простые понятные графики. Правило: каждый график должен иметь заголовок с выводом.
SQL и чистота данных
- Изучите SQL — язык данных даже в 2026 году. Освойте
SELECT,WHERE,JOIN,GROUP BYи оконные функции. - Разберитесь с Git и чистотой данных. Используйте Git для контроля версий. Репозитории должны быть аккуратными, с README.md и инструкцией "как запустить".
Статистическая база
Новичков пугает математика. Сколько статистики нужно для data science? Хорошие новости: докторской не требуется. Достаточно трех зон.
- Дескриптивная статистика: среднее, медиана, стандартное отклонение, корреляция. Это для общей картины данных.
- Вероятность: оценка шансов. Помогает работать с неопределенностью и предсказаниями.
- Распределения: как данные разбросаны (например, нормальное). Это для выбора методов анализа.
Статистическое мышление нужно, потому что данные сами не говорят — им требуется интерпретатор, учитывающий случайность и разброс.
Python или R для data science
Один из топ-вопросов у новичков. Оба языка хороши, но по-разному.
- Python — стандарт для продакшена и масштаба. Интегрируется с большими данными вроде Spark, основной для глубокого обучения в TensorFlow. Идеален для развертывания моделей и крупных систем.
- R — исторический лидер в статистике, силен в продвинутом анализе и визуализации (ggplot2). Популярен в академии и исследованиях.
Для старта в 2026 Python — лучший выбор. R подходит для мелких задач, но слабеет на больших. С вашим опытом Python — оптимальное вложение времени.
План на 6 месяцев до трудоустройства
По подходу "Стартового набора data science 2026" — пошаговый план на основе проверенных roadmap.
База (месяцы 1–2)
- Цель: самостоятельно работать с реальными данными.
- Навыки: углубить Python (Pandas, NumPy), освоить JOIN и агрегации в SQL, Git, дескриптивную статистику.
- Проект: анализ поездок в городе. Возьмите данные по мобильности за месяц, очистите, суммируйте, ответьте на бизнес-вопрос (например, "Какие три остановки дают худшие задержки в пик?"). Опубликуйте на GitHub.
Основы машинного обучения (месяцы 3–4)
- Цель: создать и оценить предиктивную модель.
- Навыки: алгоритмы обучения с учителем (логистическая регрессия, случайный лес), разделение train/test, кросс-валидация, метрики (точность, precision, recall, ROC-AUC). Инженерия признаков — 70% работы.
- Проект: модель предсказания оттока клиентов. Цель — AUC выше 85%. Сделайте карточку модели с описанием применения и ограничений.
Развертывание (месяц 5)
- Цель: сделать модель доступной.
- Навыки: Streamlit или Gradio для веб-интерфейса. Сохранение/загрузка модели через
pickleилиjoblib. - Проект: приложение "Сопоставитель резюме и вакансий". Пользователь загружает резюме, оно оценивается по описанию работы.
Портфолио для работы (месяц 6)
- Цель: показать работодателям ценность.
- Действия:
- 3 отполированных проекта на GitHub с README.
- Резюме с цифрами первым делом (например, "Построил модель оттока с precision 85% для выявления рисков").
- Посты о проектах в LinkedIn для сети.
- Заявки на вакансии, особенно в стартапы для универсалов.
Что можно пропустить в обучении
Чтобы оптимизировать процесс, важно знать, от чего отказаться. Эта часть экономит более 300 часов типичных ошибок новичков.
Глубокое обучение — потом
Если не цель в компьютерном зрении или обработке естественного языка, отложите. Трансформеры, нейросети и обратное распространение интересны, но не нужны для 80% junior-вакансий. Сначала Scikit-learn.
Сложные математические доказательства
Понятие градиентов полезно, но доказывать их не обязательно. Библиотеки берут математику на себя. Сосредоточьтесь на практике.
Прыжки по фреймворкам
Не изучайте десяток сразу. Освойте scikit-learn. Потом XGBoost и другие пойдут легко.
Соревнования на Kaggle для новичков
Kaggle манит, но новички тратят недели на ансамбли для топ-0,01% лидерборда. Это не бизнес-задачи. Развернутый проект с четким решением ценнее ранга.
Все облачные платформы
Не углубляйтесь сразу в AWS, Azure и GCP. Облако изучайте на работе, если нужно. Сначала базовый toolkit data science.
Заключение
Вход в data science в 2026 не должен пугать. Применяя правило 80/20, сосредоточьтесь на приоритетах: Python, SQL, статистика и проекты для демонстрации. Четыре столпа аналитики станут рамкой работы, а 6-месячный план направит усилия.
Суть data science — превращать данные в действия. Этот набор не просто знания, а умение давать insights для решений. Начните с первого проекта: скачайте датасет, сделайте анализ и выложите на GitHub. Путь к тысячам моделей начинается с одной строки кода.