Краткий обзор
Самый быстрый способ затормозить проект с агентным ИИ — это применять рабочий процесс, который уже не подходит. С помощью syftr мы выявили "серебряные пули" — конфигурации для задач с низкой задержкой и высокой точностью, которые стабильно показывают хорошие результаты на различных наборах данных. Эти конфигурации превосходят случайную инициализацию и трансферное обучение на начальных этапах оптимизации. Они обеспечивают около 75% от производительности полного запуска syftr при значительно меньших затратах, что делает их отличной отправной точкой, хотя и оставляет пространство для дальнейшего улучшения.
Если вы когда-либо пытались взять агентный рабочий процесс из одного проекта и применить его в другом, то знаете, как часто это заканчивается неудачей. Длина контекста модели может оказаться недостаточной. Новый сценарий может требовать более глубокого анализа. Или требования к задержке могли измениться.
Даже если старая схема работает, она может быть избыточной — и слишком дорогой — для новой задачи. В таких ситуациях простая и быстрая настройка может быть вполне достаточной.
Мы взялись ответить на простой вопрос: Существуют ли агентные процессы, которые хорошо работают в множестве сценариев, чтобы можно было выбрать один в зависимости от приоритетов и сразу приступить к делу?
Наши исследования указывают на положительный ответ, и мы называем их "серебряными пулями".
Мы определили серебряные пули как для целей с низкой задержкой, так и для высокой точности. На ранних этапах оптимизации они стабильно опережают трансферное обучение и случайную инициализацию, избегая при этом полной стоимости запуска syftr.
В последующих разделах мы расскажем, как их нашли и как они сравниваются с другими стратегиями инициализации.
Краткий обзор парадной границы Парето
Не требуется диплом по математике, чтобы разобраться, но понимание парадной границы Парето сильно упростит восприятие остального материала.
Рисунок 1 представляет иллюстративный диаграмму рассеяния — не из наших экспериментов — с завершенными пробами оптимизации syftr. Подграфик A и подграфик B идентичны, но на B выделены первые три парадные границы: P1 (красная), P2 (зеленая) и P3 (синяя).
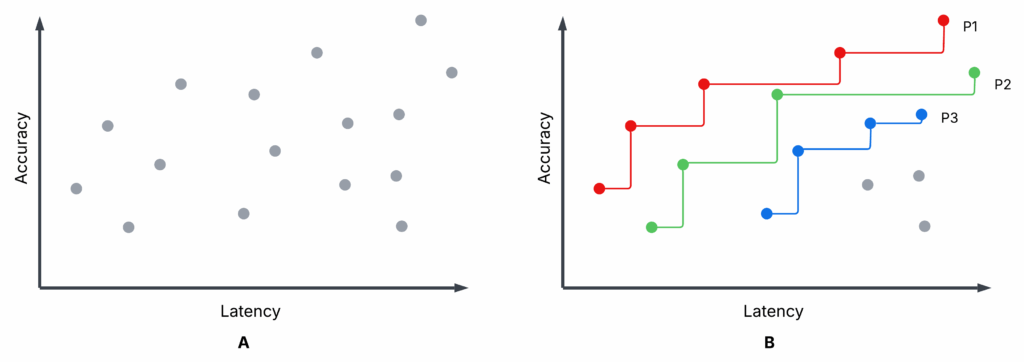
- Каждый проб: Конкретная конфигурация процесса оценивается по точности и средней задержке (выше точность, ниже задержка — лучше).
- Парадная граница (P1): Ни один другой процесс не превосходит ее по обеим метрикам одновременно. Это недоминируемые варианты.
- Непарадные процессы: По крайней мере один парадный процесс лучше их по обеим характеристикам. Они доминируемы.
- P2, P3: Если убрать P1, P2 становится следующей лучшей границей, затем P3 и так далее.
Выбор между парадными процессами может зависеть от ваших приоритетов (например, предпочтение низкой задержки максимальной точности), но нет смысла выбирать доминируемый процесс — всегда есть лучший вариант на границе.
Оптимизация агентных ИИ-процессов с помощью syftr
Во всех наших экспериментах мы применяли syftr для оптимизации агентных процессов по точности и задержке.
Этот метод позволяет:
- Выбрать наборы данных с парами вопрос–ответ (QA).
- Определить пространство поиска для параметров процесса.
- Установить цели, такие как точность и стоимость, или в нашем случае — точность и задержка.
Вкратце, syftr автоматизирует исследование конфигураций процессов в соответствии с выбранными целями.
Рисунок 2 иллюстрирует высокоуровневую архитектуру syftr.
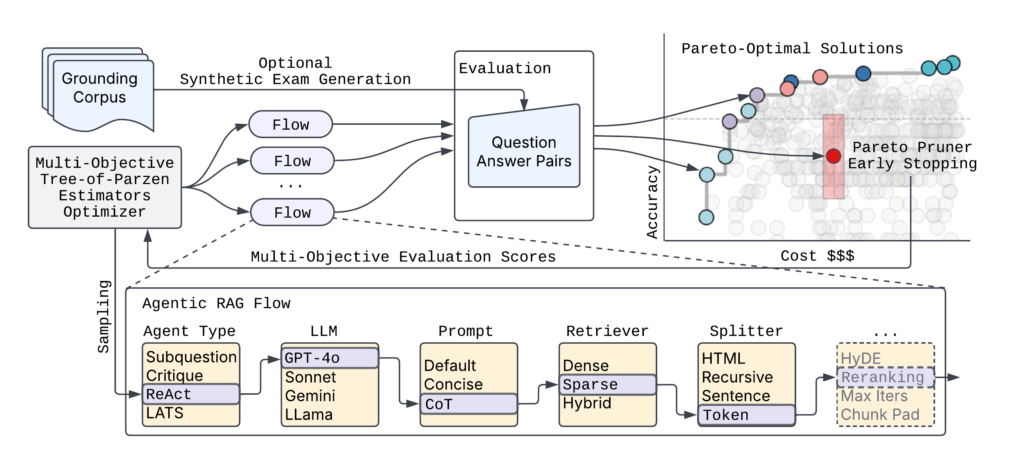
Учитывая практически бесконечное количество возможных параметризаций агентных процессов, syftr опирается на две ключевые техники:
- Многомерная байесовская оптимизация для эффективной навигации по пространству поиска.
- ParetoPruner для досрочной остановки оценки вероятно субоптимальных процессов, экономя время и вычисления, но все равно выявляя наиболее эффективные конфигурации.
Эксперименты с серебряными пулями
Наши эксперименты следовали четырехэтапному процессу (Рисунок 3).
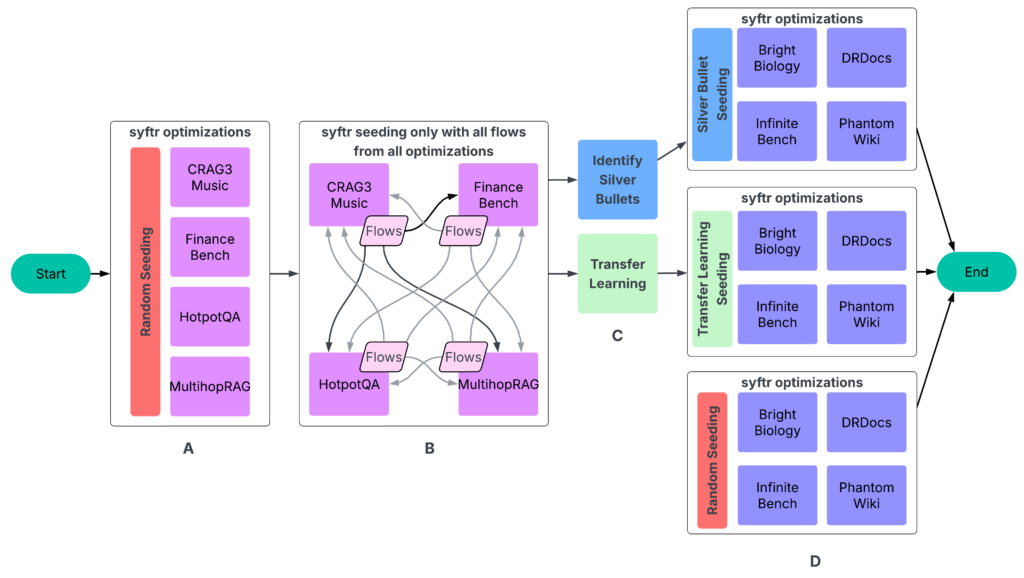
A: Запуск syftr с простой случайной выборкой для инициализации.
B: Запуск всех завершенных процессов на всех остальных экспериментах. Полученные данные поступают в следующий этап.
C: Определение серебряных пуль и проведение трансферного обучения.
D: Запуск syftr на четырех отложенных наборах данных трижды с использованием трех разных стратегий инициализации.
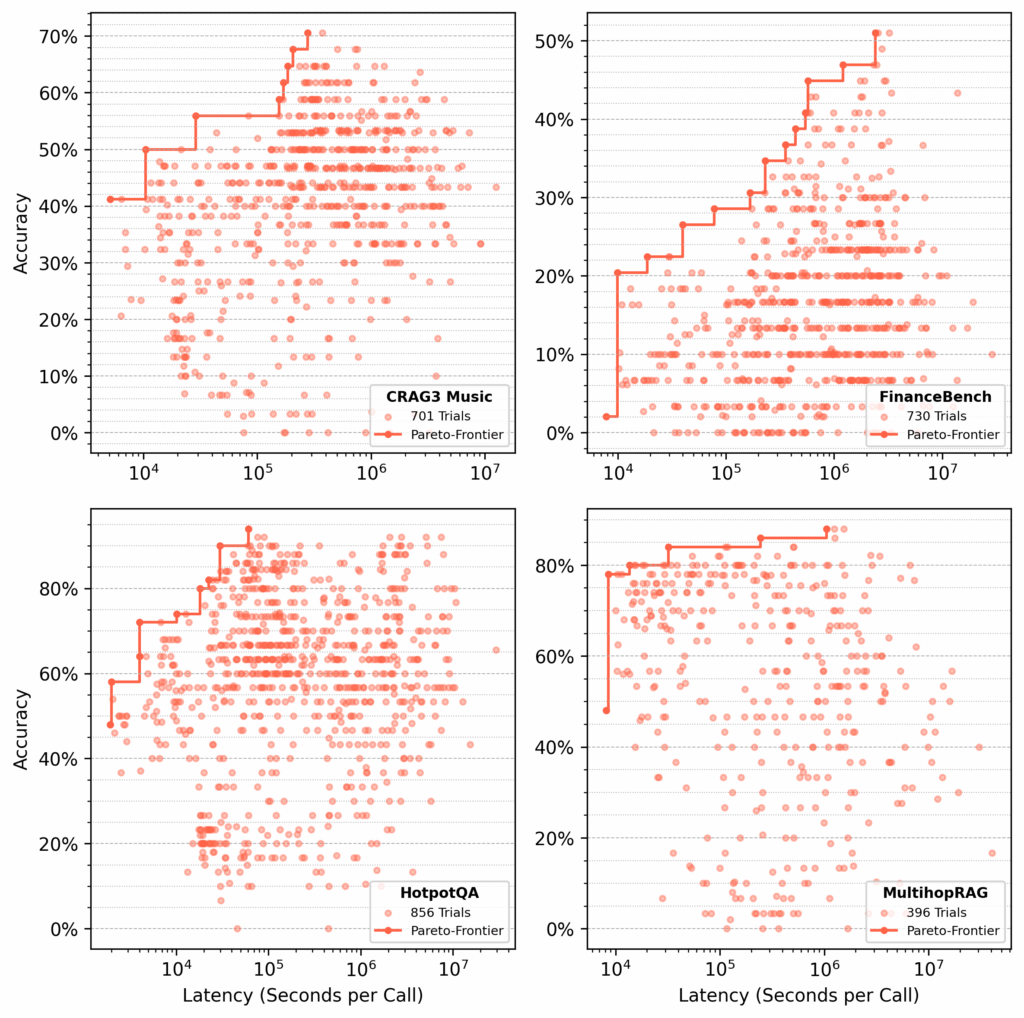
Этап 1: Оптимизация процессов для каждого набора данных
Мы провели несколько сотен проб на каждом из следующих наборов данных:
- CRAG Task 3 Music
- FinanceBench
- HotpotQA
- MultihopRAG
Для каждого набора syftr искал парадно-оптимальные процессы, оптимизируя точность и задержку (Рисунок 4).
Этап 3: Определение серебряных пуль
Получив идентичные процессы для всех обучающих наборов данных, мы смогли выделить серебряные пули — процессы, которые парадно-оптимальны в среднем по всем наборам.
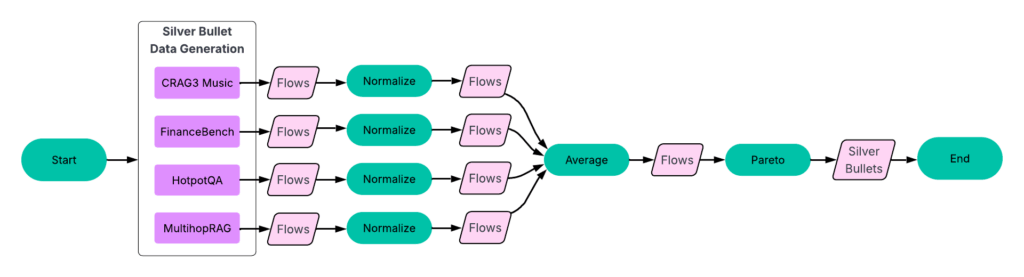
Процесс:
- Нормализация результатов по набору данных. Для каждого набора мы нормализуем оценки точности и задержки по максимальным значениям в этом наборе.
- Группировка идентичных процессов. Затем мы группируем совпадающие процессы по наборам и вычисляем средние значения точности и задержки.
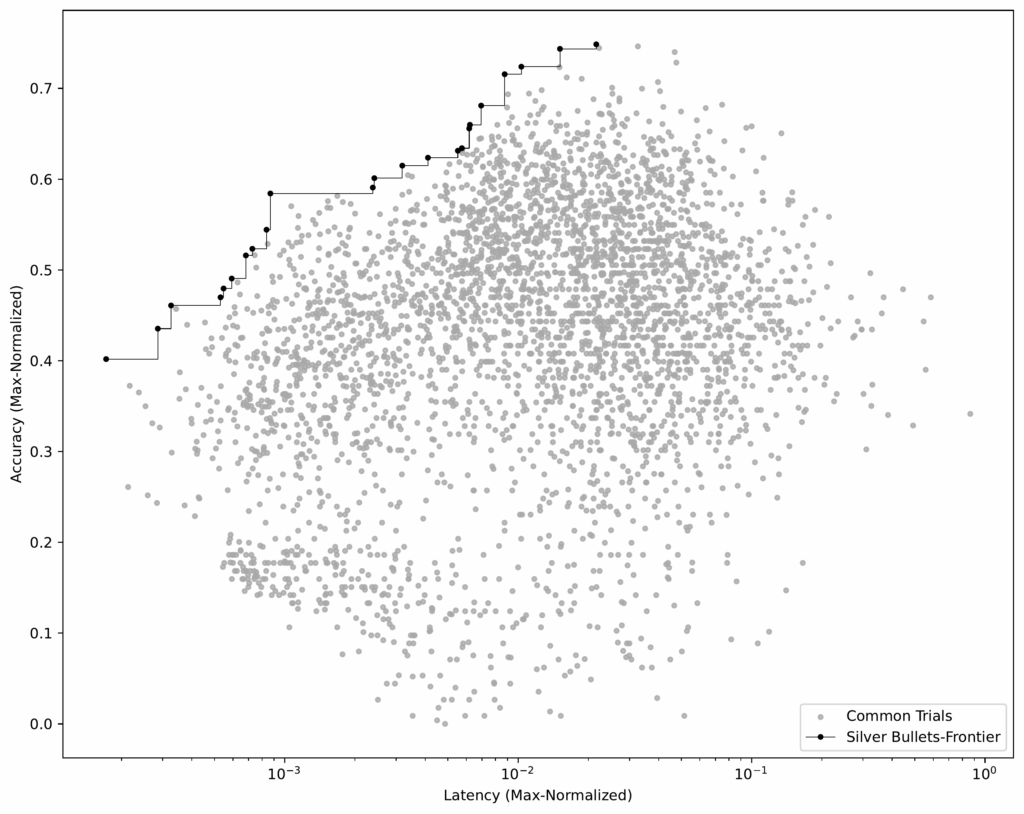
- Выделение парадной границы. Используя этот усредненный набор (см. Рисунок 6), мы выбираем процессы, формирующие парадную границу.
Эти 23 процесса — наши серебряные пули, которые хорошо работают на всех обучающих наборах данных.
Этап 4: Инициализация с трансферным обучением
В нашей оригинальной статье о syftr мы изучали трансферное обучение как способ инициализации оптимизаций. Здесь мы сравнили его напрямую с инициализацией серебряными пулями.
В этом контексте трансферное обучение подразумевает выбор конкретных высокопроизводительных процессов из исторических (обучающих) исследований и их оценку на отложенных наборах данных. Данные, используемые здесь, те же, что и для серебряных пуль (Рисунок 3).
Процесс:
- Выбор кандидатов. Из каждого обучающего набора мы взяли лучшие процессы с двух верхних парадных границ (P1 и P2).
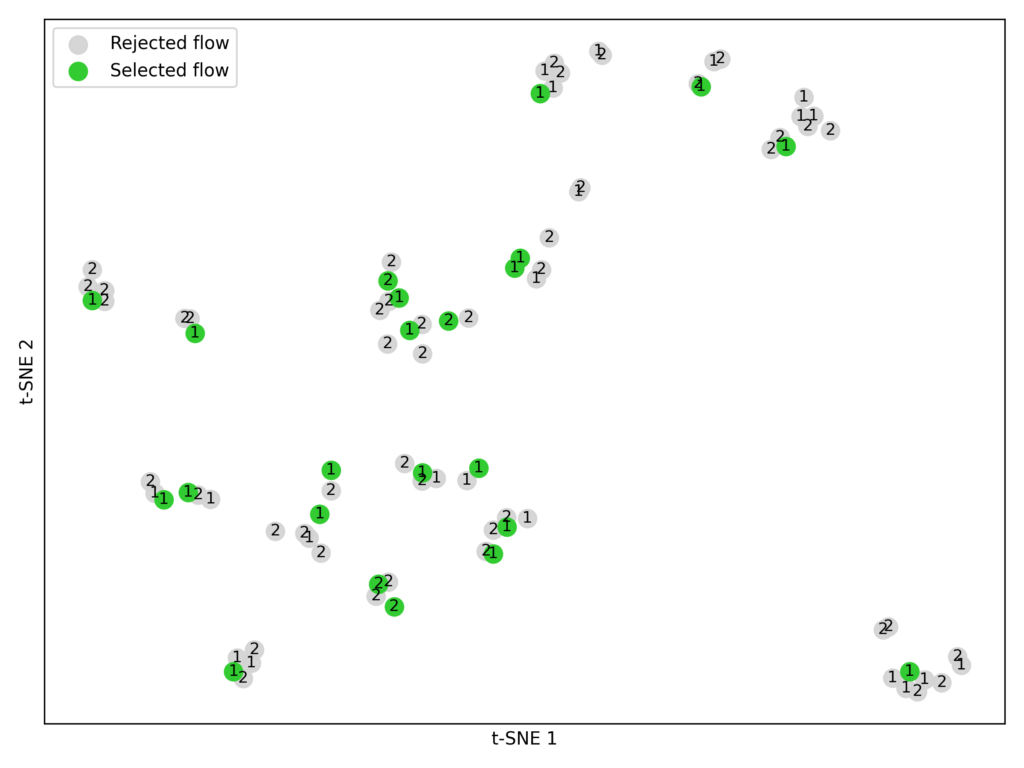
- Встраивание и кластеризация. С помощью модели встраивания BAAI/bge-large-en-v1.5 мы преобразовали параметры каждого процесса в числовые векторы. Затем применили кластеризацию K-means (K = 23) для группировки похожих процессов (Рисунок 7).
- Соответствие ограничениям эксперимента. Мы ограничили каждую стратегию инициализации (серебряные пули, трансферное обучение, случайная выборка) 23 процессами для честного сравнения, поскольку именно столько серебряных пуль мы выделили.
Примечание: Трансферное обучение для инициализации еще не полностью оптимизировано. Мы могли бы использовать больше парадных границ, выбрать больше процессов или попробовать другие модели встраивания.
Этап 5: Полное тестирование
На финальной фазе оценки (Этап D на Рисунке 3) мы провели около 1000 проб оптимизации на четырех тестовых наборах данных — Bright Biology, DRDocs, InfiniteBench и PhantomWiki — повторяя процесс трижды для каждой из следующих стратегий инициализации:
- Инициализация серебряными пулями
- Инициализация трансферным обучением
- Случайная выборка
Для каждой пробы GPT-4o-mini выступала в роли судьи, проверяя ответ агента на соответствие истинному ответу.
Результаты
Мы стремились ответить на вопрос:
Какая стратегия инициализации — случайная выборка, трансферное обучение или серебряные пули — дает лучший результат для нового набора данных за минимальное количество проб?
Для каждого из четырех отложенных тестовых наборов (Bright Biology, DRDocs, InfiniteBench и PhantomWiki) мы построили графики:
- Точность
- Задержка
- Стоимость
- Площадь Парето: мера близости результатов к оптимальным
На каждом графике вертикальная пунктирная линия обозначает момент завершения всех проб инициализации. После инициализации серебряные пули в среднем показали:
- 9% выше максимальную точность
- 84% ниже минимальную задержку
- 28% большую площадь Парето
по сравнению с другими стратегиями.
Bright Biology
Серебряные пули достигли наивысшей точности, наименьшей задержки и наибольшей площади Парето после инициализации. Некоторые пробы случайной инициализации не завершились. Площади Парето для всех методов росли со временем, но сужались по мере прогресса оптимизации.
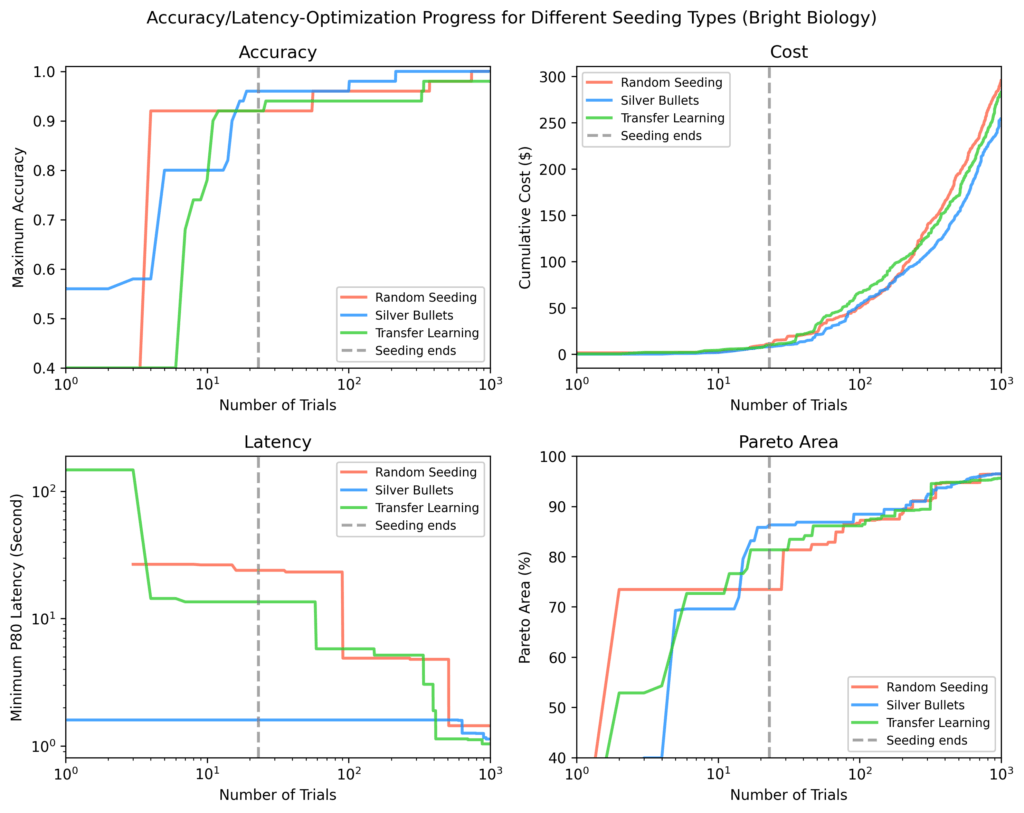
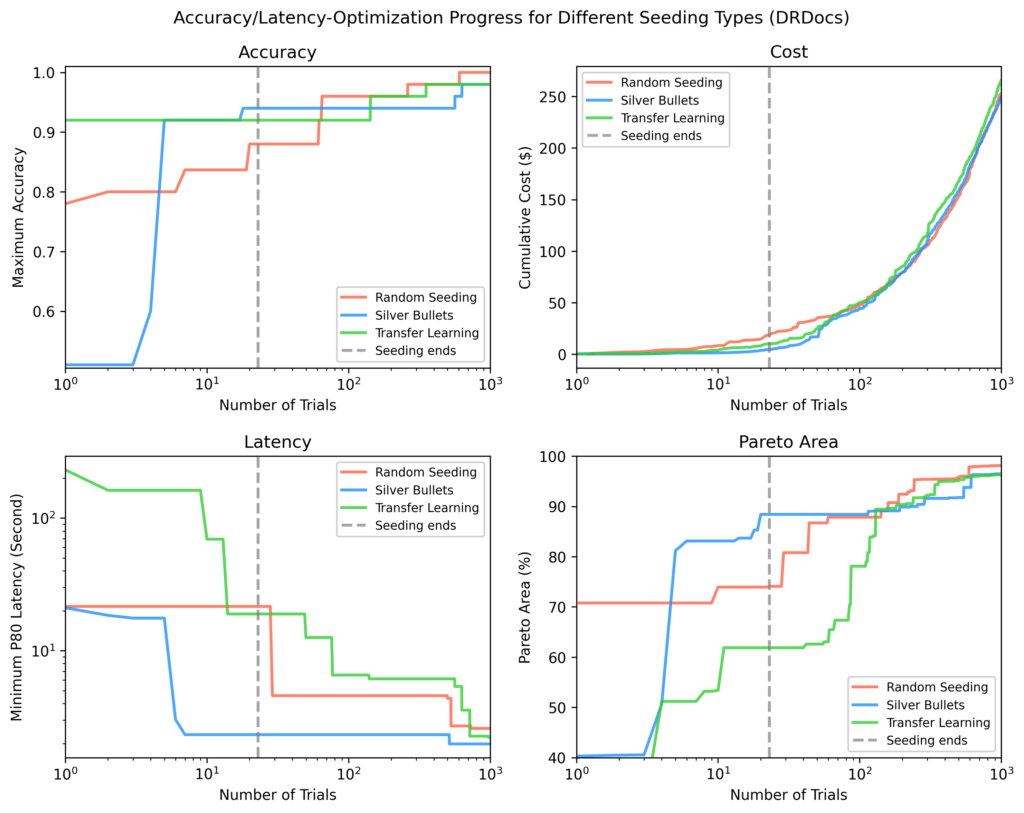
DRDocs
Аналогично Bright Biology, серебряные пули достигли 88% площади Парето после инициализации против 71% (трансферное обучение) и 62% (случайная выборка).
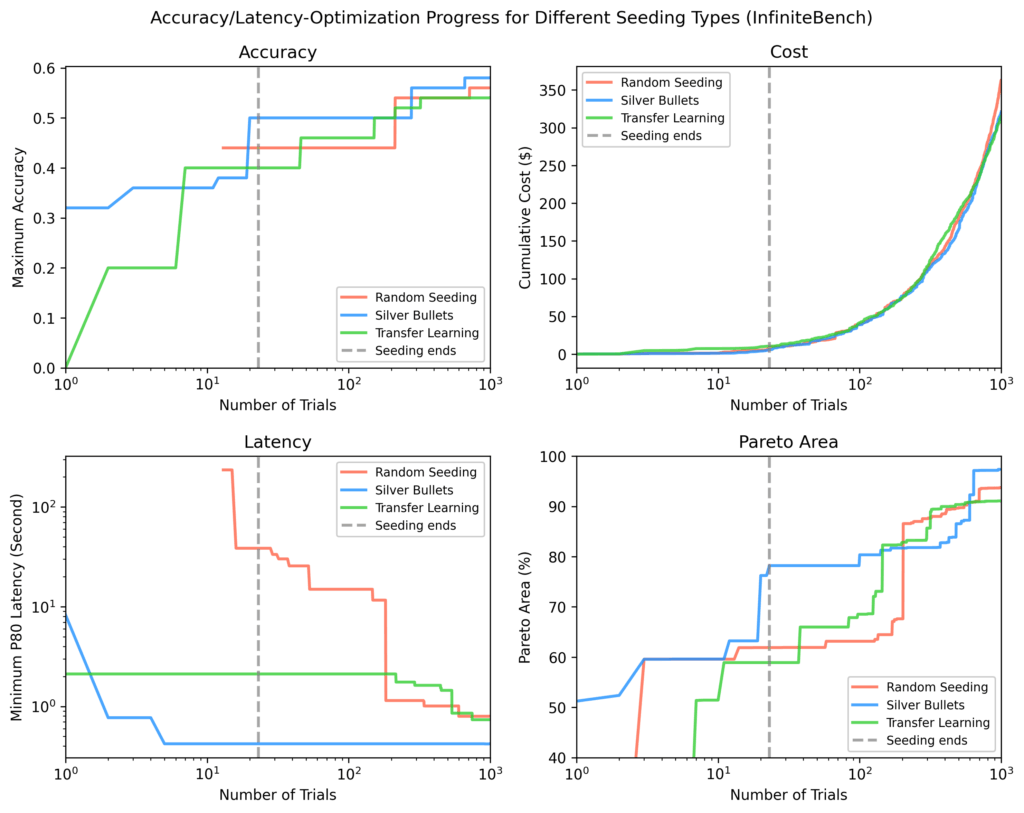
InfiniteBench
Другие методы потребовали около 100 дополнительных проб, чтобы достичь площади Парето серебряных пуль, и все равно не догнали самые быстрые процессы, найденные с серебряными пулями, к концу около 1000 проб.
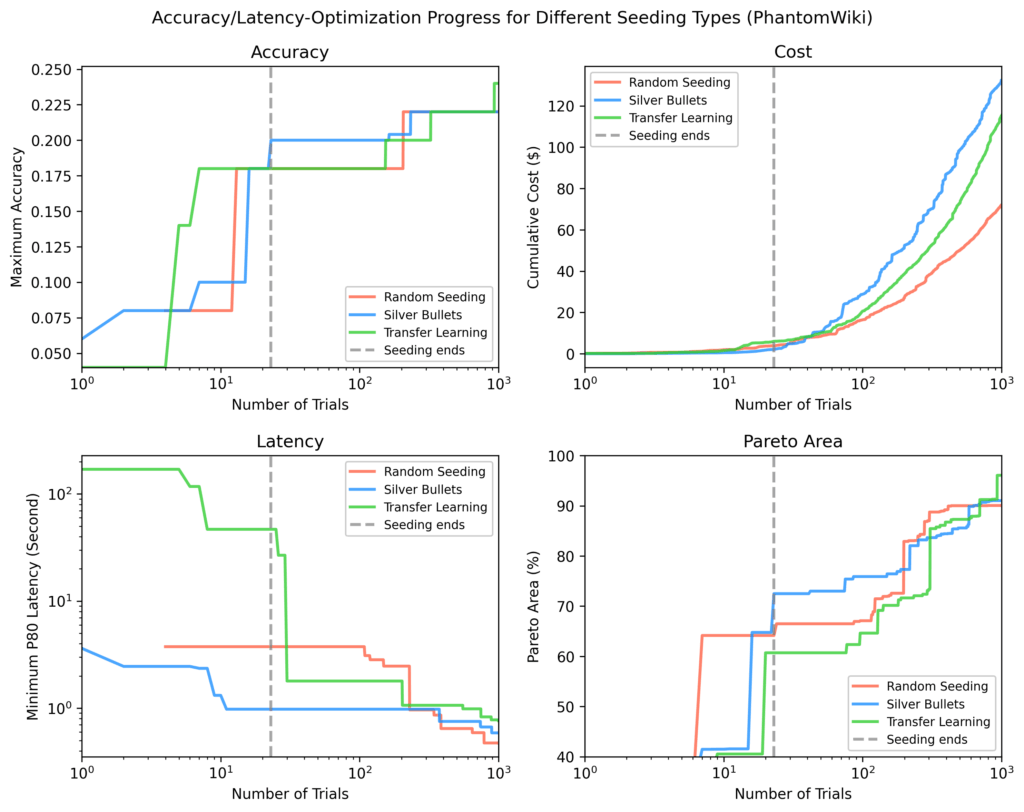
PhantomWiki
Серебряные пули снова показали лучшие результаты после инициализации. Этот набор данных продемонстрировал наибольшее расхождение в стоимости. После около 70 проб запуск с серебряными пулями временно сосредоточился на более дорогих процессах.
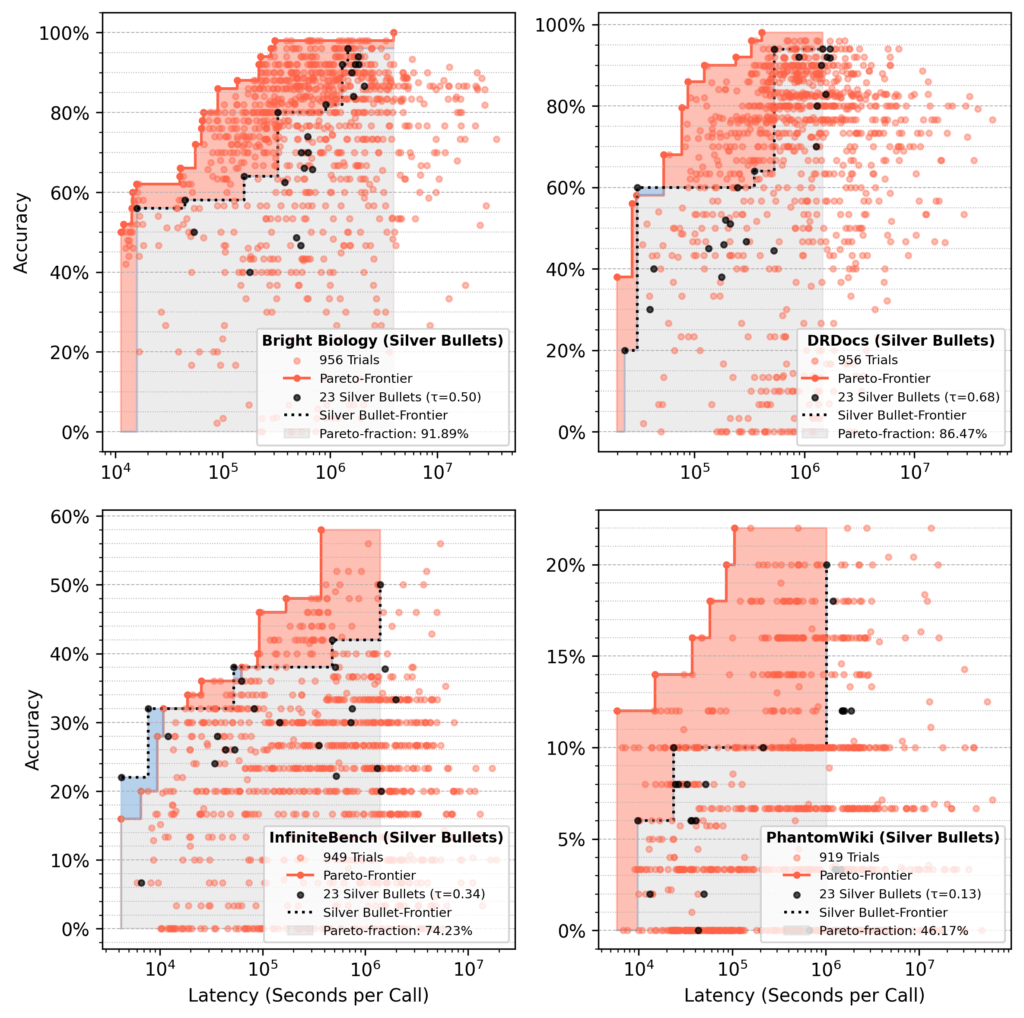
Анализ доли Парето
В запусках с инициализацией серебряными пулями 23 серебряных пули составили около 75% от финальной площади Парето после 1000 проб, в среднем.
- Красная область: Приросты от оптимизации сверх начальной производительности серебряных пуль.
- Синяя область: Серебряные пули, все еще доминирующие в конце.
Наши выводы
Инициализация серебряными пулями дает стабильно сильные результаты и даже превосходит трансферное обучение, несмотря на то что последний метод черпает из разнообразного набора исторических парадных процессов.
Для наших двух целей (точность и задержка) серебряные пули всегда стартуют с более высокой точностью и меньшей задержкой, чем процессы из других стратегий.
В долгосрочной перспективе семплер TPE снижает начальное преимущество. Через несколько сотен проб результаты всех стратегий часто сходятся, что ожидаемо, поскольку каждая в итоге должна найти оптимальные процессы.
Таким образом, существуют ли агентные процессы, которые хорошо работают в множестве сценариев? Да — но с оговорками:
- В среднем небольшой набор серебряных пуль восстанавливает около 75% площади Парето от полной оптимизации.
- Производительность варьируется по наборам данных, например 92% восстановления для Bright Biology против 46% для PhantomWiki.
Итог: серебряные пули — это недорогой и эффективный способ приблизиться к полному запуску syftr, но они не замена. Их влияние может возрасти с большим количеством обучающих наборов данных или более длительной оптимизацией обучения.
Параметризации серебряных пуль
Мы использовали следующие:
LLM
- microsoft/Phi-4-multimodal-instruct
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- Qwen/Qwen2.5
- Qwen/Qwen3-32B
- google/gemma-3-27b-it
- nvidia/Llama-3_3-Nemotron-Super-49B
Модели встраивания
- BAAI/bge-small-en-v1.5
- thenlper/gte-large
- mixedbread-ai/mxbai-embed-large-v1
- sentence-transformers/all-MiniLM-L12-v2
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- TencentBAC/Conan-embedding-v1
- Linq-AI-Research/Linq-Embed-Mistral
- Snowflake/snowflake-arctic-embed-l-v2.0
- BAAI/bge-multilingual-gemma2
Типы процессов
- vanilla RAG
- ReAct RAG agent
- Critique RAG agent
- Subquestion RAG
Вот полный список всех 23 серебряных пуль, отсортированных от низкой точности / низкой задержки к высокой точности / высокой задержке: silver_bullets.json.