Руководители команд по data science или количественным исследованиям в компаниях сейчас живут как будто в двух разных мирах.
В одном из них бушует взрыв GenAI: чатботы генерируют код и изображения, а руководители компаний не могут налюбоваться, как большие языковые модели изменят всё вокруг. В другом — рутинная работа: анализ оттока клиентов, прогнозы спроса и поиск мошенничества на основе структурированных табличных данных.
Долгое время эти миры казались полностью изолированными. Можно даже подумать, что хайп вокруг GenAI улетел вперед, оставив традиционную работу с бизнес-данными на обочине.
Но это лишь иллюзия, и она быстро рассеивается.
От чатботов к прогнозам: GenAI осваивает табличные данные и временные ряды
Скептик вы или энтузиаст, но наверняка уже общались с трансформерными моделями для черновиков писем или диффузионными — для создания картинок. Пока внимание было приковано к тексту и изображениям, те же архитектуры незаметно осваивали другой язык: числа, время и закономерности в таблицах.
Пример — SAP-RPT-1 на базе трансформера и LaTable как диффузионная модель; обе предназначены для предсказаний на табличных данных.
Появляются фундаментальные модели для data science.
Это не просто улучшения знакомых предикторов. Речь о смене парадигмы. Как LLM справляются с переводом без специальной тренировки, так и эти модели берут последовательность данных — продажи или логи серверов — и выдают прогнозы, минуя привычный долгий процесс обучения.
Темпы развития поражают. С начала 2025 года вышло не меньше 14 ключевых фундаментальных моделей для табличных данных и временных рядов. Среди них заметные работы от команд, создавших Chronos-2, TiRex, Moirai-2, TabPFN-2.5 и TempoPFN (с SDE для генерации данных) — это лишь несколько передовых примеров.
Модели превратились в фабрики по производству моделей
Раньше модели машинного обучения считали статическими: один раз обучили на истории данных и запустили для предсказаний.
Такая картина устарела. Современные модели всё чаще выступают не просто предикторами, а системами, которые на лету создают новые представления, заточенные под конкретный случай.
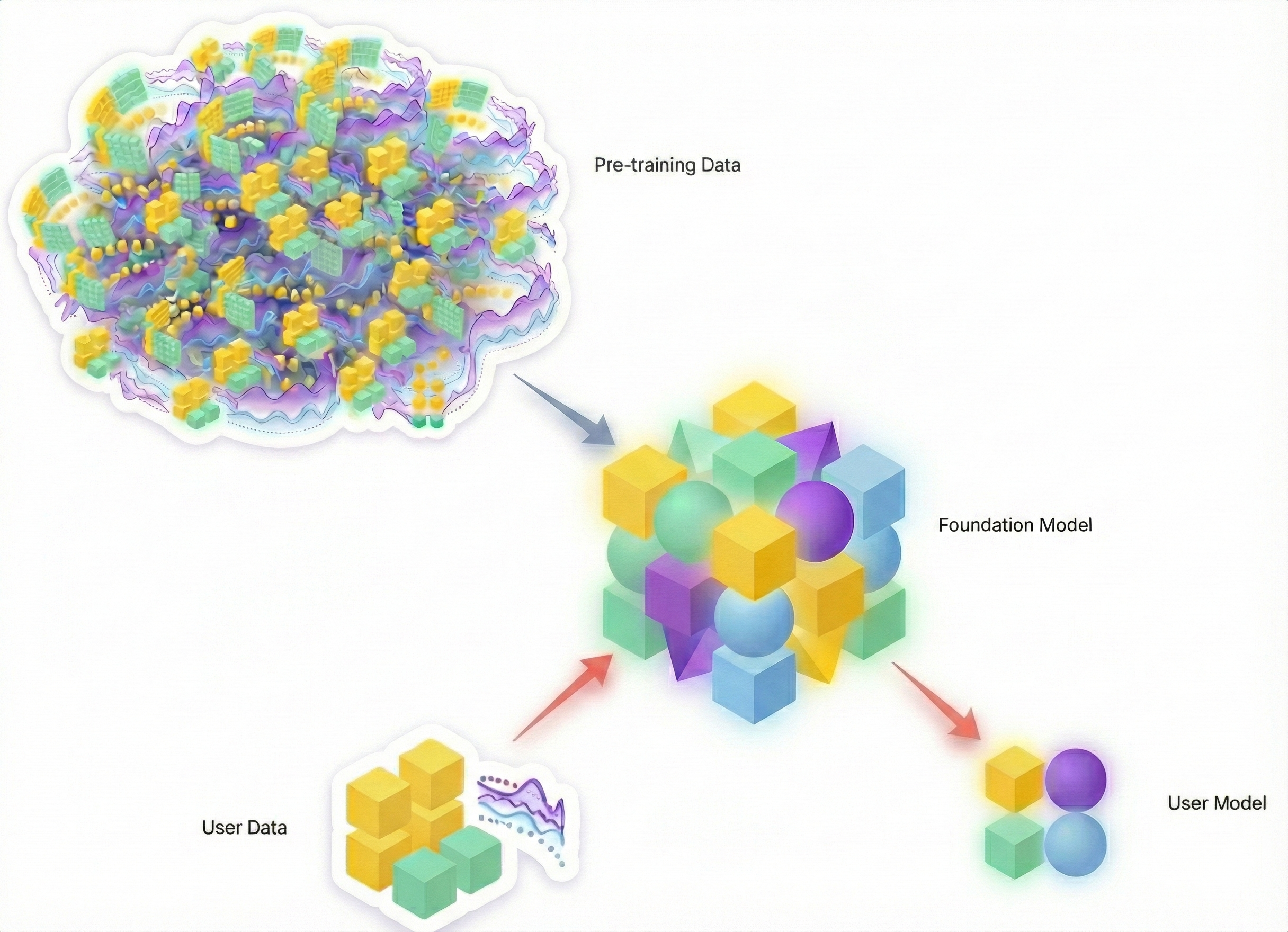
Впереди время, когда не просто запрашивают одно предсказание, а просят фундаментальную модель сгенерировать персонализированное статистическое представление — по сути, мини-модель — под текущую задачу.
Перемены уже зреют в лабораториях. Вопрос в том, почему они ещё не в ваших рабочих процессах.
Проверка на реальность: галлюцинации и простые тренды
Если вы видели в сети примеры абсурдных галлюцинаций LLM — юристы ссылаются на выдуманные дела, чатботы выдумывают историю, — мысль о таком хаосе в корпоративных прогнозах не даст уснуть.
Такие опасения имеют все основания.
Классический машинный интеллект пока остается надежным выбором
Хотя новая волна фундаментальных моделей для data science (наш термин для моделей на табличных данных и временных рядах) выглядит многообещающе, она на начальной стадии.
Да, поставщики моделей занимают верхние строчки академических тестов: все лидеры на лидерборде по прогнозам временных рядов GIFT-Eval и по табличным данным TabArena — это фундаментальные модели или их агентные обертки. Но на практике некоторые из этих "лидеров" с трудом распознают базовые тренды в сырых данных.
Они справляются со сложностями, но иногда спотыкаются о простое, где справится регрессия. Посмотрите честные ablation-исследования в статье по TabPFN v2.
Почему всё равно стоит верить: аргументы за фундаментальные модели
Несмотря на начальные проблемы, есть веские основания ожидать успеха. Мы уже говорили об их способности мгновенно реагировать на ввод — ключ для эры агентного ИИ. Главное — доступ к огромному запасу знаний из прошлого.
Кто лучше решит сложную задачу предсказания?
- Вариант A: Классическая модель, знающая только ваши данные. Каждый раз начинает с нуля, слепая к остальному миру.
- Вариант B: Фундаментальная модель, обученная на бесчисленных задачах из разных отраслей, эпох и типов данных — часто с синтетикой, — а потом адаптированная под вашу ситуацию.
Классические модели вроде XGBoost или ARIMA избегают галлюцинаций раннего GenAI, но лишены "предварительных знаний". Они не переносят опыт между областями.
Ставка, которую делает индустрия: модель с опытом мира (приорами) в итоге превзойдет изолированное обучение.
Недостающее звено: фокус на реальности, а не на лидербордах
Фундаментальные модели для data science могут стать следующим большим прорывом в ИИ. Но для этого нужно менять приоритеты. Сейчас то, что создают исследователи, и нужды бизнеса расходятся.
Крупные компании и лаборатории соревнуются в точности чисел, чтобы возглавить лидерборды перед конференциями. А сложные реальные задачи — самые трудные с научной точки зрения — остаются в тени.
Слепое пятно: взаимосвязанная сложность
Суть проблемы: ни одна из топовых фундаментальных моделей не предназначена для предсказания совместных вероятностных распределений нескольких связанных целей.
Звучит сложно, но для бизнеса это критично. В жизни переменные не изолированы.
- Городское планирование: Трафик на главной улице зависит от потока на параллельных, и наоборот.
- Цепочки поставок: Спрос на товар A часто снижает спрос на B.
- Финансы: Для риска портфеля не суммируют худшие сценарии по инструментам отдельно. Нужны совместные симуляции, учитывающие, как активы двигаются вместе.
Реальность — паутина зависимостей. Текущие модели видят её как набор изолированных задач из учебников. Пока они не научатся моделировать этот танец переменных, не вытеснят старые инструменты.
Пока ручные процессы в безопасности. Но считать разрыв постоянным — серьезная ошибка.
Сегодняшние пределы глубокого обучения завтра решат инженеры
Отсутствующие элементы вроде совместных распределений — не пределы физики, а следующие инженерные задачи.
Если 2025 чему-то научил, то тому, что "невозможные" барьеры исчезают внезапно. Когда их закроют, возможности не просто вырастут — взлетят.
Итог: точка перелома ближе, чем кажется
Хоть пробелы и есть, траектория ясна, время идет. Стена между предиктивным и генеративным ИИ рушится.
Мы движемся к эпохе, где не тренируют модели на истории, а обращаются к фундаментальным моделям с приорами тысяч отраслей. Data science станет единым полем, где результат — не число, а сгенерированная на лету персонализированная модель.
Революция не ждет идеала. Она приближается стремительно. Те, кто увидит сдвиг и начнет применять GenAI к структурированным данным заранее, задаст тон следующему десятилетию в data science. Остальные будут догонять в новой игре.