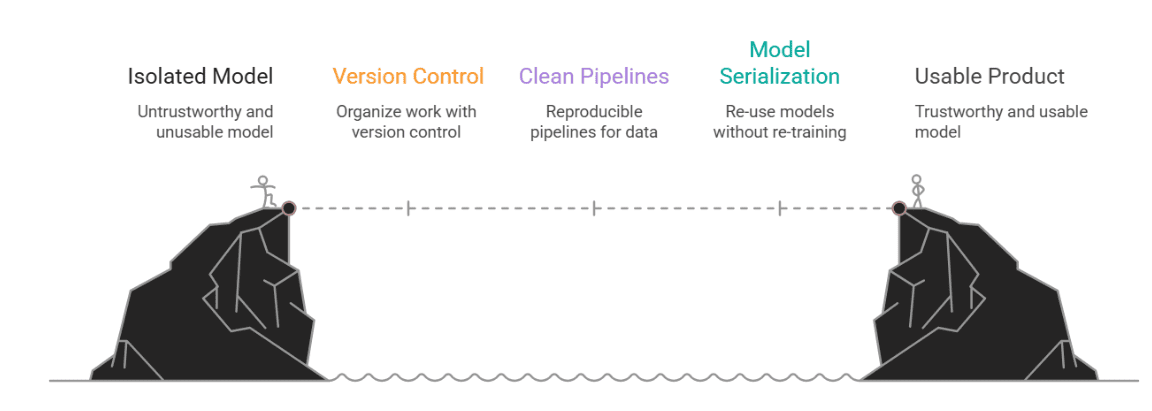
Введение
Многие занимаются проектами по data science и машинному обучению. Такие занятия помогают оттачивать навыки и демонстрировать знания. Однако они редко доходят до уровня, который требуется в реальном продакшене.
В этой статье берется проект анализа зарплат по профессиям в США и превращается в нечто пригодное для практического применения. Рассматривается простая, но надежная настройка MLOps: от контроля версий до развертывания.
Подход подойдет начинающим специалистам по данным, фрилансерам или тем, кто строит портфолио. Он позволит представить работу так, будто она вышла из профессиональной команды.
Здесь показано, как уйти от ноутбуков: настраивается структура MLOps, воспроизводимые пайплайны, артефакты моделей, локальный API, логирование и документация.

Описание задачи и данных
Проект использует национальный датасет США с ежегодными данными о зарплатах и занятости по профессиям во всех 50 штатах и территориях. Включает общую занятость, средние зарплаты, группы профессий, процентили зарплат и географические метки.

Основные цели:
- Сравнение зарплат по штатам и категориям профессий
- Проведение статистических тестов (T-тесты, Z-тесты, F-тесты)
- Построение регрессий для анализа связи занятости и зарплат
- Визуализация распределений зарплат и тенденций по профессиям
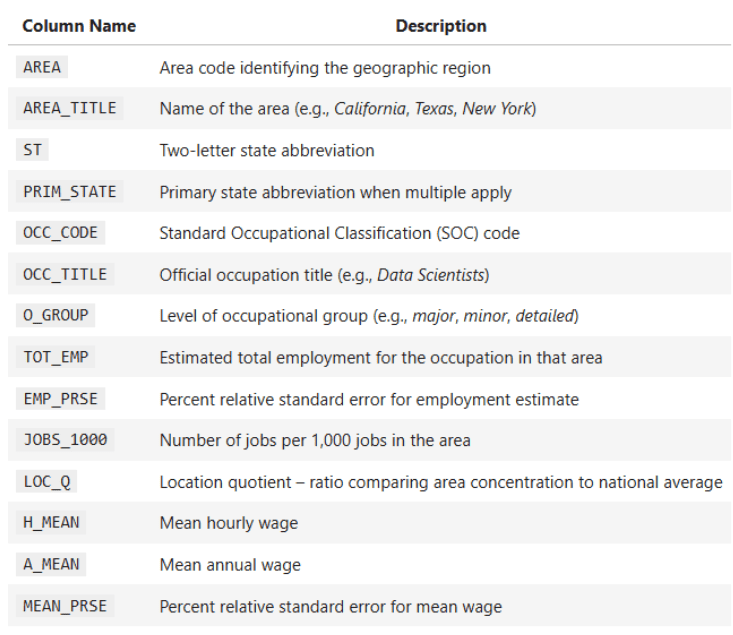
Ключевые столбцы датасета:
OCC_TITLE— название профессииTOT_EMP— общая занятостьA_MEAN— средняя годовая зарплатаPRIM_STATE— сокращение штатаO_GROUP— категория профессии (Major, Total, Detailed)
Задача — получить надежные выводы о различиях в зарплатах, распределении рабочих мест и статистических связях. Кроме того, проект структурируется так, чтобы его можно было повторно использовать и воспроизводить. Это ключевой навык для современных data scientists.
Начало с контроля версий
Даже небольшие проекты нуждаются в четкой структуре и контроле версий. Предлагается удобная и удобная для ревью структура папок.

Полезные привычки:
- Сырые данные остаются неизменными: копируйте их для обработки.
- Для больших датасетов подойдет Git LFS.
- Каждый скрипт в
src/решает одну задачу. - Частые коммиты с понятными сообщениями, например:
feat: add T-test comparison between management and production wages.
Такая организация показывает работодателям профессиональный подход.
Создание воспроизводимых пайплайнов (и отказ от хаоса в ноутбуках)
Ноутбуки хороши для исследований: меняете фильтр, перезапускаете ячейку, копируете график — и вот уже 40 ячеек без понимания, что дало финальный результат.
Чтобы проект выглядел продакшенным, логика из ноутбука упаковывается в единую функцию предобработки. Она становится каноническим местом, где данные о зарплатах по профессиям США:
- Загружаются из Excel
- Очищаются и преобразуются в числовой формат
- Нормализуются (штаты, группы профессий, коды)
- Обогащаются вспомогательными столбцами, например общим фондом оплаты
Дальше все анализы — графики, T-тесты, регрессии, корреляции, Z-тесты — используют один очищенный DataFrame.
Из ячеек ноутбука в переиспользуемую функцию
Ноутбук сейчас делает:
- Загружает файл
state_M2024_dl.xlsx - Парсит первый лист в DataFrame
- Преобразует
A_MEAN,TOT_EMPв числовой тип - Использует их для сравнения зарплат по штатам, линейной регрессии (
TOT_EMP→A_MEAN), корреляции Пирсона (Q6), Z-теста tech vs non-tech (Q7), теста Левена на дисперсию зарплат
Это превращается в функцию preprocess_wage_data, которую можно вызывать откуда угодно:
from src.preprocessing import preprocess_wage_data
df = preprocess_wage_data("data/raw/state_M2024_dl.xlsx")
Теперь ноутбук, скрипты или API используют одно определение "очищенных данных".
Что именно делает пайплайн предобработки

Для этого датасета пайплайн:
1. Загружает Excel-файл один раз.
xls = pd.ExcelFile(file_path)
df_raw = xls.parse(xls.sheet_names[0])
df_raw.head()

2. Преобразует ключевые числовые столбцы.
Столбцы, используемые в анализе:
- Занятость:
TOT_EMP,EMP_PRSE,JOBS_1000,LOC_QUOTIENT - Зарплаты:
H_MEAN,A_MEAN,MEAN_PRSE - Процентили зарплат:
H_PCT10,H_PCT25,H_MEDIAN,H_PCT75,H_PCT90,A_PCT10,A_PCT25,A_MEDIAN,A_PCT75,A_PCT90
Безопасное преобразование:
df = df_raw.copy()
numeric_cols = [
"TOT_EMP",
"EMP_PRSE",
"JOBS_1000",
"LOC_QUOTIENT",
….
]
for col in numeric_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors="coerce")
Странные значения вроде '**' или 'N/A' станут NaN, пайплайн не сломается.
3. Нормализует текстовые идентификаторы.
Для группировки и фильтров:
PRIM_STATEв верхний регистр ("ca" → "CA")O_GROUPв нижний ("Major" → "major")OCC_CODEв строку для .str.startswith("15") в Z-тесте tech vs non-tech
4. Добавляет вспомогательные столбцы.
Общий фонд оплаты примерно через среднюю зарплату:
df["TOTAL_PAYROLL"] = df["A_MEAN"] * df["TOT_EMP"]
Соотношение зарплаты к занятости для ниш с высокой зарплатой и низкой занятостью, с защитой от деления на ноль:
df["WAGE_EMP_RATIO"] = df["A_MEAN"] / df["TOT_EMP"].replace({0: np.nan})
5. Возвращает чистый DataFrame.
Для дальнейшего кода:
- Графики топ/боттом штатов
- T-тесты (Management vs Production)
- Регрессия (
TOT_EMP→A_MEAN) - Корреляции (Q6)
- Z-тесты (Q7)
- Тест Левена
df = preprocess_wage_data("state_M2024_dl.xlsx")
Полную функцию предобработки поместите в src/preprocessing.py:
import pandas as pd
import numpy as np
def preprocess_wage_data(file_path: str = "state_M2024_dl.xlsx") -> pd.DataFrame:
"""
Load and clean the U.S. occupational wage data from Excel.
- Reads the first sheet of the Excel file.
- Ensures key numeric columns are numeric.
- Normalizes text identifiers (state, occupation group, occupation code).
- Adds helper columns used in later analysis.
"""
# Load raw Excel file
xls = pd.ExcelFile(file_path)
Остальной код функции доступен в репозитории.
Сохранение статистических моделей и артефактов
Артефакты моделей — это регрессии, матрицы корреляций, очищенные датасеты, графики.
import joblib
joblib.dump(model, "models/employment_wage_regression.pkl")
Зачем сохранять:
- Избегаете перевычислений при вызовах API или дашбордах
- Сохраняете версии для сравнений
- Разделяете анализ и инференс
Такие шаги делают проект ближе к продакшену.
Локальная работа (через API или мини-веб-интерфейс)
Не обязательно сразу Docker и Kubernetes. Для аналитики сначала хватит:
- Чистой функции предобработки
- Хорошо названных функций анализа
- Скрипта, соединяющего их
Это упрощает вызовы из ноутбука, Streamlit/Gradio или будущих FastAPI/Flask.
Превращение анализов в мини-API
Логика из ноутбука:
- T-тест: Management vs Production
- Регрессия:
TOT_EMP→A_MEAN - Корреляция Пирсона (Q6)
- Z-тест tech vs non-tech (Q7)
- Тест Левена на дисперсию зарплат
Одну из них упаковываем в функцию как endpoint API.
Пример: сравнение зарплат менеджмента и производства.
from scipy.stats import ttest_ind
import pandas as pd
def compare_management_vs_production(df: pd.DataFrame):
"""
Two-sample T-test between Management and Production occupations.
"""
# Filter for relevant occupations
mgmt = df[df["OCC_TITLE"].str.contains("Management", case=False, na=False)]
prod = df[df["OCC_TITLE"].str.contains("Production", case=False, na=False)]
# Drop missing values
mgmt_wages = mgmt["A_MEAN"].dropna()
prod_wages = prod["A_MEAN"].dropna()
# Perform two-sample T-test (Welch's t-test)
t_stat, p_value = ttest_ind(mgmt_wages, prod_wages, equal_var=False)
return t_stat, p_value
Функцию можно переиспользовать в скриптах, Streamlit или FastAPI без копирования из ноутбука.
Простая точка входа локально
Все собирается в скрипт main.py или ячейку ноутбука:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest # move these from the notebook
from analysis import compare_management_vs_production # the function above
if __name__ == "__main__":
# 1. Load and preprocess the data
df = preprocess_wage_data("state_M2024_dl.xlsx")
# 2. Run core analyses
t_stat, p_value = compare_management_vs_production(df)
print(f"T-test (Management vs Production) -> t={t_stat:.2f}, p={p_value:.4f}")
corr_q6, p_q6 = run_q6_pearson_test(df)
print(f"Pearson correlation (TOT_EMP vs A_MEAN) -> r={corr_q6:.4f}, p={p_q6:.4f}")
z_q7 = run_q7_ztest(df)
print(f"Z-test (Tech vs Non-tech median wages) -> z={z_q7:.4f}")
Это концептуально API: вход — очищенный DataFrame, операции — именованные функции, выход — числа для дашборда или REST.
Логирование всего (даже мелочей)
Логирование делает проект отлаживаемым и надежным. Даже в простом аналитическом проекте полезно фиксировать:
- Какой файл загружен
- Сколько строк осталось после предобработки
- Какие тесты запущены
- Ключевые статистики тестов
Вместо ручных print и скролла ноутбука настраивается простая конфигурация логов для скриптов и ноутбуков.
Базовая настройка логирования
Создайте папку logs/, добавьте в начало кода (в main.py или logging_config.py):
import logging
from pathlib import Path
# Make sure logs/ exists
Path("logs").mkdir(exist_ok=True)
logging.basicConfig(
filename="logs/pipeline.log",
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)
При каждом запуске обновляется logs/pipeline.log.
Логирование предобработки и анализов
Расширяем пример из предыдущего раздела:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest
from analysis import compare_management_vs_production
import logging
if __name__ == "__main__":
logging.info("Starting wage analysis pipeline.")
# 1. Preprocess data
df = preprocess_wage_data("state_M2024_dl.xlsx")
logging.info("Loaded cleaned dataset with %d rows and %d columns.", df.shape[0], df.shape[1])
# 2. T-test: Management vs Production
t_stat, p_value = compare_management_vs_production(df)
logging.info("T-test (Mgmt vs Prod) -> t=%.3f, p=%.4f", t_stat, p_value)
# 3. Pearson correlation (Q6)
corr_q6, p_q6 = run_q6_pearson_test(df)
logging.info("Pearson (TOT_EMP vs A_MEAN) -> r=%.4f, p=%.4f", corr_q6, p_q6)
# 4. Z-test (Q7)
z_q7 = run_q7_ztest(df)
logging.info("Z-test (Tech vs Non-tech median wages) -> z=%.3f", z_q7)
logging.info("Pipeline finished successfully.")
В logs/pipeline.log видна хронология: начало предобработки, размеры данных, статистики тестов.
Это типичный шаг MLOps: не просто запуск анализов, а их наблюдение.
Рассказ истории (то есть написание для людей)
Документация важна, особенно для тем вроде зарплат, профессий и региональных сравнений, интересных менеджерам.
В README или финальном ноутбуке:
- Почему анализ полезен
- Краткий обзор паттернов зарплат и занятости
- Ключевые визуализации (топ/боттом штаты, распределения зарплат, сравнения групп)
- Объяснения тестов и причин их выбора
- Интерпретации регрессий и корреляций
- Ограничения (недостающие данные по штатам, вариация выборки)
- Следующие шаги: углубленный анализ или дашборд
Хорошая документация делает проект доступным всем.
Заключение
Все это важно, потому что data science в реальности не изолировано. Модель бесполезна, если ее нельзя запустить, понять или проверить. MLOps мостит путь от эксперимента к продукту.
Статья берет типичный ноутбучный проект и добавляет структуру: контроль версий, воспроизводимые пайплайны предобработки, сериализацию моделей для переиспользования, легкий локальный API, логирование и документацию для технарей и бизнеса.