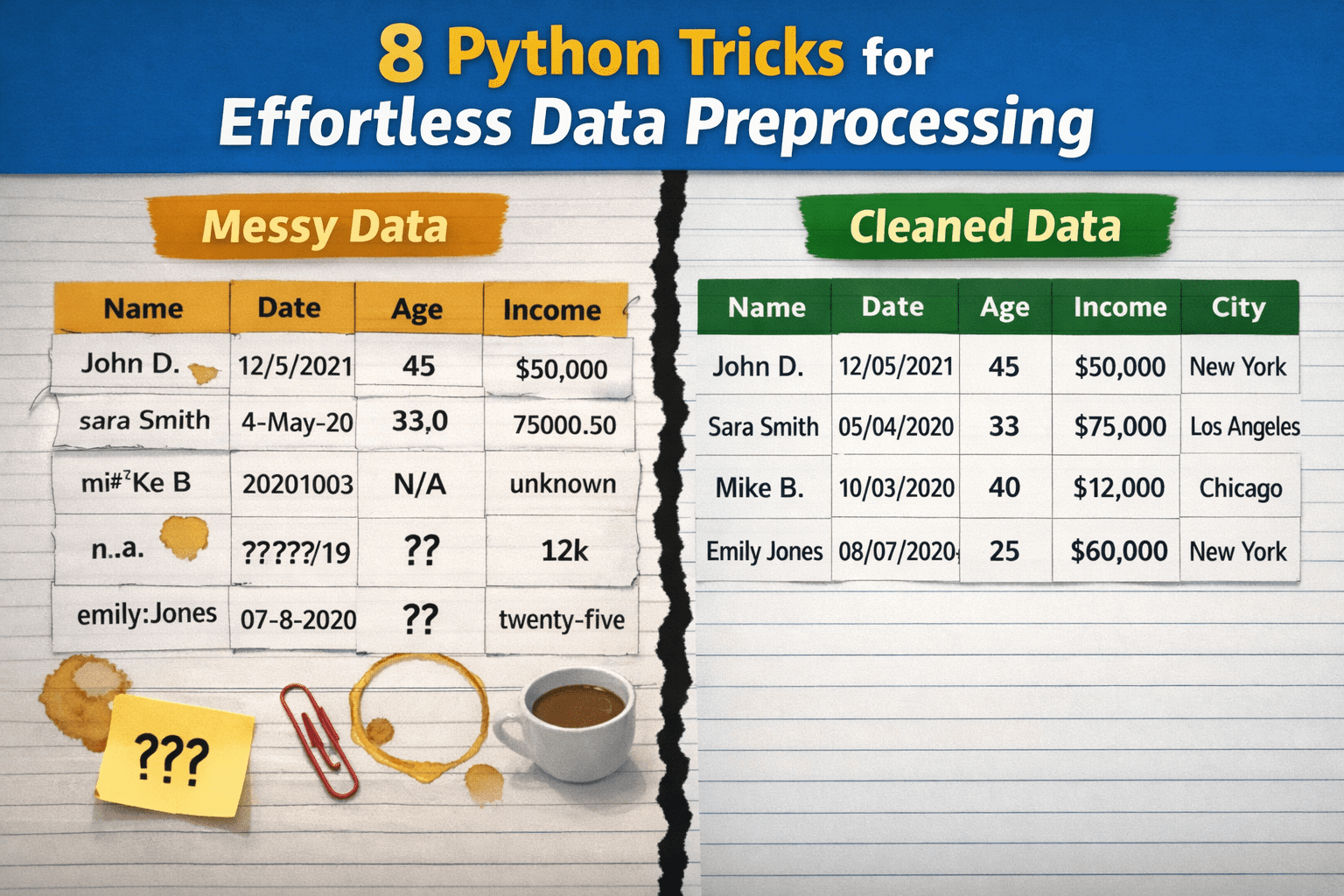
Введение
Предобработка данных существенно влияет на проекты в data science и машинном обучении, но её часто выполняют с промахами. Всё из-за ощущения, что это слишком хлопотно, занимает уйму времени или требует кучи самописного кода. В итоге данные чистят на отвал, прибегают к ненадёжным импровизированным методам, которые потом ломаются, или усложняют простые вещи.
Далее — 8 приёмов на Python, чтобы сырые данные превратились в готовый к анализу набор без лишних усилий.
Сначала подключим нужные библиотеки и создадим маленький датасет с типичными проблемами для демонстрации:
import pandas as pd
import numpy as np
# Маленький датасет с искусственным беспорядком
df = pd.DataFrame({
" User Name ": [" Alice ", "bob", "Bob", "alice", None],
"Age": ["25", "30", "?", "120", "28"],
"Income$": ["50000", "60000", None, "1000000", "55000"],
"Join Date": ["2023-01-01", "01/15/2023", "not a date", None, "2023-02-01"],
"City": ["New York", "new york ", "NYC", "New York", "nyc"],
})
1. Нормализация имён столбцов одной строкой
Этот приём в одну команду приводит все имена столбцов к единому виду. Здесь пробелы меняются на подчёркивания, а буквы — на строчные. Так избегаем ошибок в следующих шагах и правим опечатки. Перебирать столбцы по одному не придётся!
df.columns = df.columns.str.strip().str.lower().str.replace(" ", "_")
2. Удаление пробелов из строк повсеместно
Иногда нужно просто убрать лишние пробелы в начале и конце строковых значений по всему датасету, не трогая числа. Этот метод делает именно это для всех столбцов с текстом, остальные оставляет в покое.
df = df.apply(lambda s: s.str.strip() if s.dtype == "object" else s)
3. Безопасное преобразование числовых столбцов
Если формат чисел в столбце неидеален, лучше явно перевести их в числа. Так строчки, похожие на цифры, станут настоящими числами. Одна строка заменяет try-except и ручную чистку.
df["age"] = pd.to_numeric(df["age"], errors="coerce")
df["income$"] = pd.to_numeric(df["income$"], errors="coerce")
Обычный df['columna'].astype(float) может упасть на некорректных значениях.
4. Парсинг дат с errors='coerce'
Похожий подход для дат: валидные значения конвертируются, остальные — в NaT (Not a Time). Параметр errors='coerce' заставляет Pandas не падать на ошибках, а просто ставить пропуски.
df["join_date"] = pd.to_datetime(df["join_date"], errors="coerce")
5. Заполнение пропусков умными значениями
Вместо удаления строк с пропусками можно заполнить их медианой для чисел или модой для категорий. Этот однострочник гибкий — меняйте агрегат по вкусу. Индекс [0] берёт первое значение при ничьей мод.
df["age"] = df["age"].fillna(df["age"].median())
df["city"] = df["city"].fillna(df["city"].mode()[0])
6. Стандартизация категорий через map
В столбцах вроде городов разные варианты одного значения мешают группировкам вроде groupby(). Словарь помогает заменить их на единый вариант — здесь всё про Нью-Йорк становится "NYC".
city_map = {"new york": "NYC", "nyc": "NYC"}
df["city"] = df["city"].str.lower().map(city_map).fillna(df["city"])
7. Удаление дубликатов с выбором столбцов
Гибкий способ чистки повторов: subset=["user_name"] смотрит только на этот столбец. Так каждый уникальный пользователь остаётся один раз, без двойного учёта — всё одной командой.
df = df.drop_duplicates(subset=["user_name"])
8. Обрезка выбросов по квантилям
Вместо удаления экстремальных значений их обрезают до разумных пределов — 1% и 99% квантилей. Полезно, если выбросы от ошибок ввода. Значения внутри диапазона не меняются.
q_low, q_high = df["income$"].quantile([0.01, 0.99])
df["income$"] = df["income$"].clip(q_low, q_high)
Итоги
Эти восемь приёмов сделают пайплайны предобработки в Python быстрее, эффективнее и устойчивее.