Введение
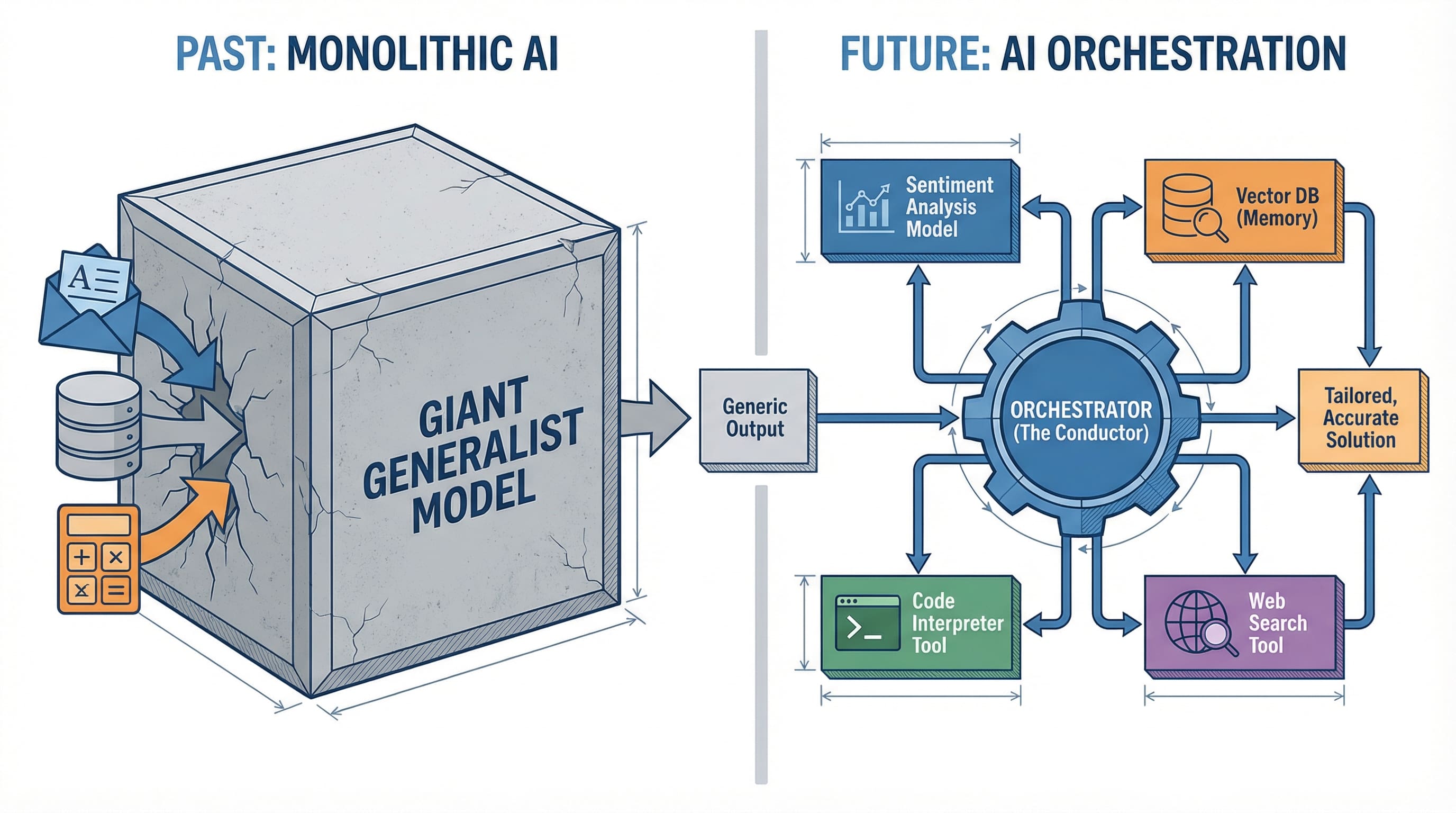
За последние два года индустрия ИИ сосредоточилась на создании языковых моделей огромных размеров. GPT-4, Claude, Gemini — каждая из них позиционировалась как универсальное решение для любых задач ИИ. Пока компании соперничали за самый большой "мозг", в реальных проектах развернулась незаметная революция. Разработчики больше не выбирают одну лучшую модель, а ищут способы объединить несколько в единую систему.
Так появился подход оркестрации ИИ, который полностью меняет процесс создания умных приложений.
Почему универсальная модель не подходит
Идея единой сверхмощной модели ИИ звучит заманчиво. Один вызов API, один ответ, один счет. Но практика показывает гораздо большую сложность.
Возьмем приложение для клиентской поддержки. Здесь требуется анализ настроения для оценки эмоций клиента, поиск знаний для нахождения нужных данных, генерация ответов для составления сообщений и проверка качества для гарантии точности. GPT-4 в принципе справится со всем, но каждое задание требует особой настройки. Модель, заточенная под анализ настроения, использует иные архитектурные решения, чем та, что оптимизирована для генерации текста.
Прогресс не в создании модели, которая сделает всё. Ключ в координации узких специалистов.
Это напоминает переход от монолитных приложений к микросервисам. Не потому, что отдельный микросервис лучше, а благодаря тому, что слаженная работа специализированных сервисов обеспечивает лучшую поддержку, масштабируемость и эффективность. ИИ сейчас переживает свой момент микросервисов.
Трёхслойная архитектура
Чтобы разобраться в современных приложениях ИИ, нужно смотреть на них послойно. Архитектура, проверенная в реальных внедрениях, получилась удивительно единообразной.
Модельный слой
Модельный слой — это база. Сюда входят большие языковые модели вроде GPT-4, Claude, локальные такие как Llama или узкоспециализированные для зрения, кода или анализа. Каждая модель предлагает свои сильные стороны: рассуждения, генерацию, классификацию или преобразования. Главное открытие — отказ от выбора одной модели в пользу сборки коллекции.
Слой инструментов
Слой инструментов обеспечивает действия. Языковые модели умеют думать, но сами по себе ничего не делают. Им нужны инструменты для взаимодействия с внешним миром. Сюда относятся поиск в вебе, запросы к базам данных, вызовы API, среды для выполнения кода и файловые системы. Когда Claude "ищет в интернете" или ChatGPT "запускает Python-код", они задействуют именно эти инструменты. Протокол контекста модели (MCP), который Anthropic выпустил недавно, стандартизирует подключение моделей к инструментам, делая этот слой проще в использовании.
Слой оркестрации
Слой оркестрации управляет всем процессом. Здесь сосредоточен настоящий интеллект системы. Оркестратор решает, какую модель задействовать для какой задачи, когда вызывать инструменты, как связывать операции и что делать при сбоях. Это дирижер ИИ-симфонии.
Модели — музыканты, инструменты — инструменты, а оркестрация — партитура, которая указывает, когда играть.
Фреймворки оркестрации: разбираем паттерны
Как React и Vue упростили фронтенд-разработку, так фреймворки оркестрации стандартизируют создание ИИ-систем. Но сначала разберем архитектурные паттерны, которые они воплощают. Инструменты меняются, паттерны остаются.
Паттерн цепочки (последовательная логика)
Паттерн цепочки — базовый для оркестрации. Это конвейер данных, где результат одного шага подается на вход следующему. Вопрос пользователя, поиск контекста, генерация ответа, проверка результата. Всё идет по порядку, оркестратор передает данные между этапами. LangChain ввел этот паттерн и построил вокруг него фреймворк для создания переиспользуемых цепочек.
Плюс цепочек в простоте: легко проследить поток, отлаживать поэтапно и оптимизировать отдельные части. Минус — жесткость. Цепочки не меняются по ходу дела. Если на втором шаге выяснится, что вопрос неразрешим, система всё равно пройдет третий и четвертый. Но для предсказуемых процессов с четкими этапами цепочки идеальны.
Паттерн RAG (логика поиска прежде всего)
Паттерн RAG родился из проблемы галлюцинаций языковых моделей при нехватке данных. Решение простое: сначала найти релевантную информацию, потом сгенерировать ответ на её основе.
Архитектурно RAG — это внедрение контекста вовремя. Разделение вычислений (LLM) и памяти (векторное хранилище). Модель статична, не учится новому. Вместо этого в её "оперативку" — окно промта — подставляется нужный контекст. Не переучиваем мозг, а даем точные данные именно тогда, когда они требуются.
Принцип работает так: запрос, поиск в базе знаний, ранжирование по релевантности, внедрение в контекст, генерация ответа. Это превращает задачу генерации в поиск плюс синтез, а поиск надежнее генерации.
RAG стал вечным паттерном благодаря разделению обязанностей. Модель отвечает за рассуждения и синтез, векторное хранилище — за память и отзыв, оркестратор — за момент внедрения. LlamaIndex заточил свой фреймворк под оптимизацию RAG: разбиение документов, генерацию эмбеддингов, хранение векторов и ранжирование поиска. RAG на практике реализуется даже на no-code-инструментах.
Паттерн мультиагентов (логика делегирования)
Паттерн мультиагентов — вершина оркестрации. Вместо одной цепочки или поиска создаются специализированные агенты, которые передают задачи друг другу. Агент-"планировщик" разбирает сложные задания. "Исследователи" собирают данные. "Аналитики" их обрабатывают. "Писатели" формируют вывод. "Критики" проверяют качество.
CrewAI воплощает этот паттерн, хотя идея старше инструмента. Суть в том, что сложный интеллект возникает из координации специалистов, а не от универсала, который пытается всё. Каждый агент имеет узкую роль, критерии успеха и возможность делегировать. Оркестратор следит за графом делегирования, предотвращая циклы и направляя к цели. Подробнее о принципах агентного ИИ — в основных концепциях.
Выбор паттерна зависит от задачи, а не от "лучшего". Простые процессы — цепочки. Знаниеемкие приложения — RAG. Сложные многошаговые рассуждения с разными специализациями — мультиагенты. В продакшене часто сочетают все: мультиагенты с внутренним RAG и цепочками для связи.
Протокол контекста модели (MCP) заслуживает отдельного внимания как будущий стандарт. Это не паттерн, а универсальный способ подключения моделей к инструментам и данным. Anthropic представил его в конце 2024 года, и он становится базой для фреймворков — как HTTP для оркестрации ИИ. С ростом MCP интерфейсы стандартизируются, любой паттерн работает с любым инструментом независимо от фреймворка.
От промта к пайплайну: роутер решает исход
Понять оркестрацию теоретически — одно. В реальных системах видно, почему она важна и какой компонент определяет успех.
Представьте ассистента для отладки кода. Монолитный подход шлет код и ошибки в GPT-4 и надеется на удачу. Оркестрированная система действует иначе, и ключ — роутер.
Роутер — это движок решений в центре системы. Он анализирует запросы и выбирает путь. Это не просто трубы. Точность роутинга определяет, превзойдет ли система монолит или растратит ресурсы зря.
Вернёмся к отладчику. При поступлении проблемы роутер определяет: синтаксическая ошибка, ошибка выполнения или логическая? Каждому типу — свой путь.

Синтаксические ошибки идут к анализатору кода — легкой модели, настроенной на нарушения разбора. Ошибки выполнения запускают отладчик для изучения состояния программы, потом данные передают модели рассуждений, понимающей контекст исполнения. Логические ошибки требуют иного: поиск похожих случаев на Stack Overflow, извлечение контекста, синтез решений моделью рассуждений.
Как роутер выбирает? Три подхода лидируют в продакшене.
Семантический роутинг опирается на сходство эмбеддингов. Запрос превращают в вектор, сравнивают с примерами путей, шлют по самому похожему. Быстро и точно для четких категорий. Отладчик использует это при обилии примеров ошибок.
Ключевой роутинг ловит явные сигналы. Если в сообщении "SyntaxError" — к парсеру. "NullPointerException" — к обработчику выполнения. Просто, быстро, надежно при четких индикаторах. Многие системы стартуют с этого.
Роутинг на базе LLM ставит маленькую быструю модель роутером. Она классифицирует запросы по обучению или промту. Гибче ключей, точнее семантики, но медленнее и дороже. GitHub Copilot и аналоги применяют вариации.
Главный вывод: успех оркестрации на 90% зависит от точности роутера, а не от моделей ниже. Идеальный ответ GPT-4 по неверному пути бесполезен. Нормальный от специалиста по правильному — решает задачу.
Это неожиданная цель оптимизации. Команды фокусируются на выборе LLM для генерации, забывая о роутере. Нужно наоборот. Простой точный роутер лучше сложного ошибочного. Продакшен-команды измеряют точность роутинга как ключевой метрикой успеха.
Роутер также обрабатывает отказы и запасные пути. Низкая уверенность семантики? Переход к ключам. Ничего не нашлось в поиске? Эскалация к LLM-роутеру. Всегда есть дефолт для неоднозначных случаев.
Вот почему оркестрированные системы бьют монолиты. Не магия, а точный роутинг, который дает специалистам задачи по профилю. Анализатор разбирает только синтаксис. Модель рассуждений — только рассуждает. Каждый в своей зоне благодаря роутеру.
Паттерн универсален: роутер спереди, специалисты сзади, оркестратор управляет потоком. Для ботов поддержки, исследовательских ассистентов или отладчиков успех зависит от роутера.
Когда применять оркестрацию, а когда хватит простоты
Не всякое ИИ-приложение требует оркестрации. Чатбот для FAQ? Одна модель. Классификатор тикетов? Одна модель. Генератор описаний товаров? Одна модель.
Оркестрация нужна при:
Нескольких возможностях, которые не тянет одна модель. Клиентская поддержка с анализом настроения, поиском знаний и генерацией ответов выигрывает от оркестрации. Простой Q&A — нет.
Внешних данных или действиях. Поиск в базах, вызовы API, выполнение кода — оркестрация управляет инструментами лучше, чем попытки заставить модель "притворяться".
Надежности за счет резерва. Продакшен цепляет быструю дешевую модель для простого и мощную дорогую для сложного. Оркестратор распределяет по сложности.
Оптимизации затрат. Всё на GPT-4 дорого. Оркестрация шлет легкие задачи на дешевые модели, тяжелые — на мощные.
Решение простое: начинайте с одной модели, пока не упретесь. Добавляйте оркестрацию, когда плюсы перекроют сложность: лучшие результаты, меньшие расходы, новые функции.
Итоги
Оркестрация ИИ показывает взросление области. Переход от "какую модель выбрать?" к "как спроектировать ИИ-систему?". Как и в любой технологии: от монолитов к распределенным, от лучшего инструмента к правильной сборке.
Фреймворки готовы. Паттерны формируются. Вопрос в том, строить ли приложения по-старому — надеясь на универсальную модель — или по-новому: координируя специалистов и инструменты в систему сильнее суммы частей.
Будущее ИИ не в идеальной модели. Оно в умении дирижировать оркестром.