Описание эксперимента
Настройка гиперпараметров часто кажется простым способом резко поднять качество модели машинного обучения. Идея звучит заманчиво: немного поэкспериментировать с параметрами, запустить поиск по сетке и получить заметный прирост производительности.
Но на деле это так работает?

Мы проверили эту идею на данных об успеваемости португальских студентов, взяв четыре разных классификатора и применив тщательную статистическую проверку. Подход включал вложенную кросс-валидацию, надежные конвейеры предобработки и тесты на значимость — полный набор инструментов.
Итог? Производительность снизилась на 0.0005. Да, настройка чуть ухудшила результаты, хотя разница статистически не значима.
Это не провал. Скорее ценное наблюдение: по умолчанию параметры часто дают отличный результат. Иногда умнее прекратить настройку и переключиться на другие задачи.
Подготовка датасета

Датасет взят из проекта анализа успеваемости студентов. В нем 649 записей о студентах с 30 признаками: демография, семейный фон, социальные факторы и школьные данные. Задача — предсказать, сдаст ли студент финальный экзамен по португальскому (оценка ≥ 10).
Ключевой шаг — исключить оценки G1 и G2. Эти промежуточные баллы коррелируют с финальной G3 на 0.83–0.92. Их наличие делает предсказание слишком легким и лишает эксперимент смысла. Цель — найти предикторы успеха без опоры на предыдущие результаты по тому же предмету.
Для загрузки и подготовки данных применили библиотеку pandas:
# Load and prepare data
df = pd.read_csv('student-por.csv', sep=';')
# Create pass/fail target (grade >= 10)
PASS_THRESHOLD = 10
y = (df['G3'] >= PASS_THRESHOLD).astype(int)
# Exclude G1, G2, G3 to prevent data leakage
features_to_exclude = ['G1', 'G2', 'G3']
X = df.drop(columns=features_to_exclude)Распределение классов: 100 студентов не сдали (15.4%), 549 сдали (84.6%). Из-за дисбаланса оптимизировали по F1-score, а не по accuracy.
Выбор классификаторов
Выбрали четыре модели, представляющие разные подходы:
- логистическая регрессия: линейный базовый метод
- случайный лес: ансамблевый метод
- XGBoost: градиентный бустинг
- машина опорных векторов (SVM): подход на основе ядер

Сначала запустили модели с параметрами по умолчанию, потом настроили через поиск по сетке с 5-кратной кросс-валидацией.
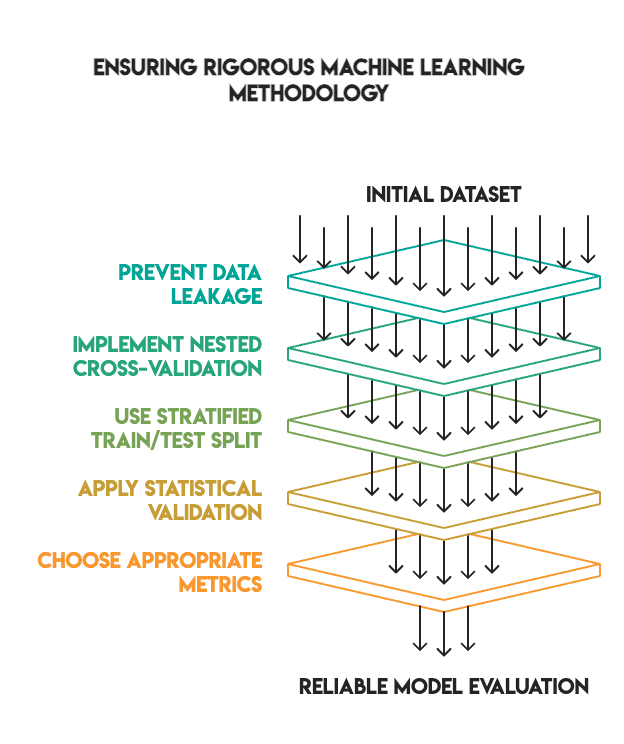
Надежная методология
Многие руководства по машинному обучению показывают крутые результаты настройки, пропуская важные проверки. Мы придерживались строгих стандартов для достоверности.
Метод включал:
- Отсутствие утечки данных: вся предобработка в конвейерах, подгонка только на обучающих данных
- Вложенная кросс-валидация: внутренний цикл для настройки, внешний — для оценки
- Правильный сплит: 80/20 со стратификацией, тестовый набор изолирован (без подглядывания)
- Статистическая проверка: тест McNemar's для значимости различий
- Выбор метрики: F1-score для дисбалансных классов вместо accuracy
Структура конвейера:
# Preprocessing pipeline - fit only on training folds
numeric_transformer = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Combine transformers
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, X.select_dtypes(include=['int64', 'float64']).columns),
('cat', categorical_transformer, X.select_dtypes(include=['object']).columns)
])
# Full pipeline with model
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model)
])Разбор результатов
После настройки результаты удивили:
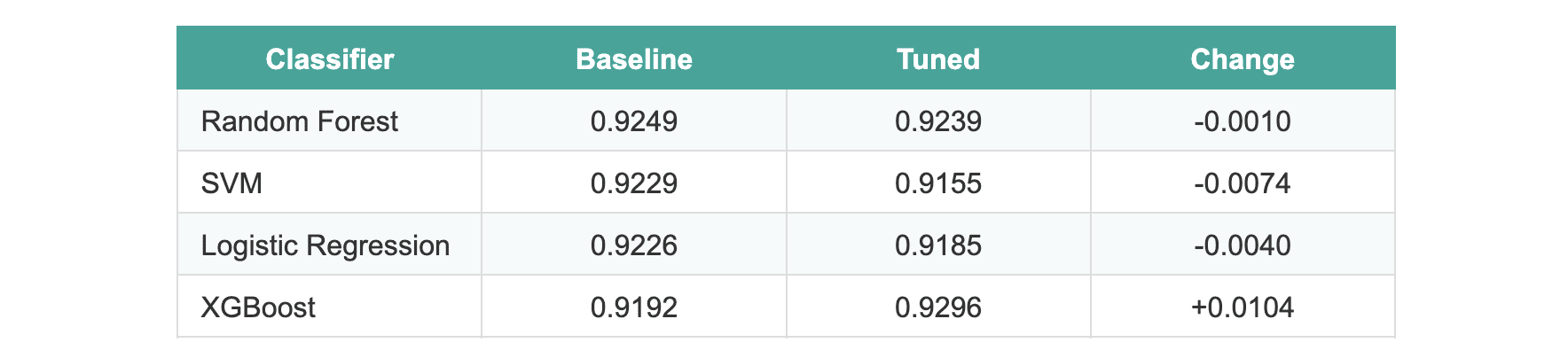
Средний прирост по всем моделям — -0.0005.
У трех моделей после настройки качество чуть упало. У XGBoost прирост около 1%, но на тестовом наборе без статистической значимости.
Провели тест McNemar's между лучшими (случайный лес и XGBoost). p-value = 1.0 — разницы нет.
Причины отсутствия улучшений

Объяснения:
- Качественные параметры по умолчанию. scikit-learn и XGBoost имеют отточенные значения, работающие на разных датасетах.
- Слабый сигнал. Без G1 и G2 признаки потеряли силу предсказания. Не хватило для оптимизации.
- Малый объем данных. 649 сэмплов на фолды — мало для надежного поиска по сетке.
- Потолок качества. Базовые модели давали 92–93% F1, места для роста мало без новых фич или данных.
- Строгий подход. Без утечек и с вложенной CV надуманные улучшения исчезают.
Уроки из эксперимента
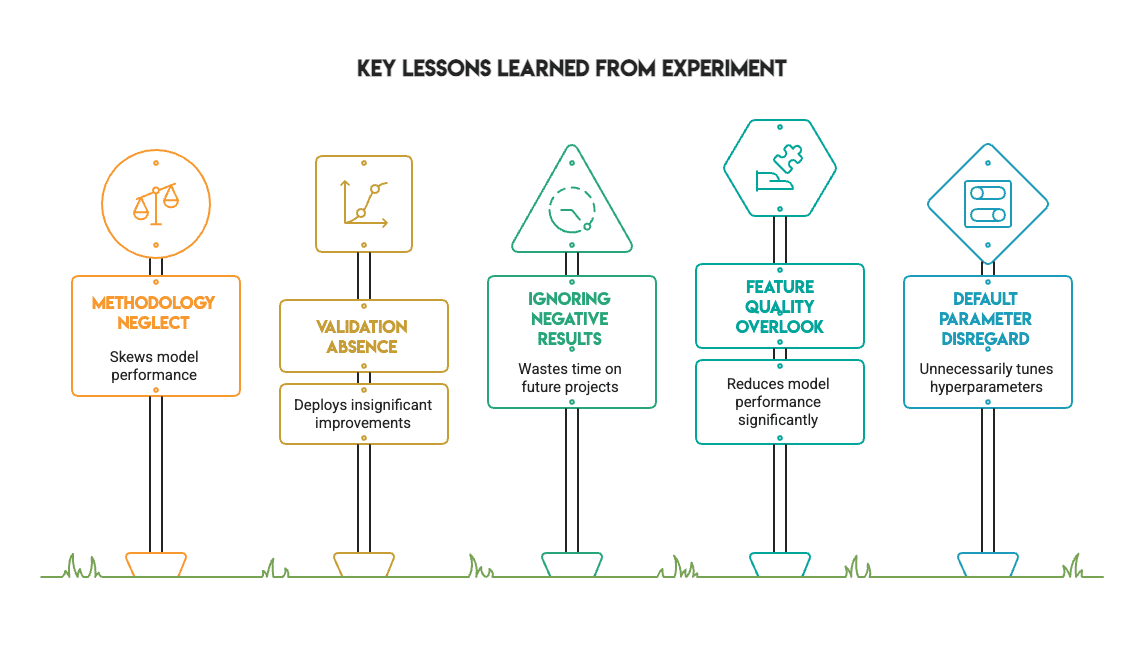
Эксперимент дает практические выводы:
- Методология важнее цифр. Устранение утечек и правильная валидация меняют картину.
- Статистика обязательна. Без теста McNemar's можно было бы принять шум за улучшение.
- Отрицательные результаты полезны. Знать, когда настройка не помогает, экономит время.
- Параметры по умолчанию недооценены. Они подходят для типичных задач.
Итоги эксперимента
Пытались поднять качество через тщательную настройку четырех моделей по всем правилам с проверками.
Результат: без значимых улучшений.

Это не неудача. Такие честные итоги помогают в реальных проектах: знать, когда остановить настройку и заняться данными, фичами или сбором новых сэмплов.
Машинное обучение — не гонка за максимальными числами. Главное — надежные модели на основе правильного процесса, а не погоня за мелочами. Самое сложное — вовремя остановиться.