
Введение
Веб-краулинг представляет собой автоматизированный обход страниц интернета с переходом по ссылкам и сбором данных в удобном формате. Такой подход помогает извлекать обширные объемы информации с ресурсов вроде сайтов документации, публикаций, баз знаний и прочих веб-страниц.
Преобразовать собранный контент в вид, подходящий для работы ИИ-агентов, оказывается непростой задачей. Документационные сайты полны вложенных разделов, дублирующихся ссылок навигации, стандартных шаблонов и неравномерной верстки. Полученные данные требуют очистки, сортировки и хранения в форме, пригодной для ИИ-задач вроде поиска по контенту, систем вопросов-ответов или платформ на базе агентов.
Здесь мы разберем преимущества Olostep перед Scrapy и Selenium, настроим окружение для краулинга, составим скрипт для обработки сайта документации и разработаем веб-интерфейс на Gradio. Это позволит вводить URL и параметры для запуска сбора страниц без редактирования кода.
Почему Olostep лучше Scrapy и Selenium
Scrapy предлагает мощный функционал как полноценный фреймворк для скрапинга. Он дает полный контроль, но требует значительных усилий на установку и доработку.
Selenium подходит для автоматизации браузера и справляется с динамическим JavaScript-контентом, однако не заточен под краулинг документации как самостоятельный инструмент.
Olostep упрощает задачу через единый API: поиск, обход, извлечение и структурирование данных с выходом в форматах Markdown, текст, HTML или JSON, удобных для ИИ. Не нужно самостоятельно соединять модули для обнаружения, парсинга, форматирования и интеграции с ИИ.
Для документационных ресурсов это ускоряет переход от URL к готовому контенту, минимизируя время на сборку собственной системы краулинга.
Установка пакетов и настройка API-ключа
Начните с установки Python-пакетов для проекта. SDK Olostep работает на Python 3.11 и новее.
pip install olostep python-dotenv tqdmЭти библиотеки обеспечивают ключевые функции:
olostepсвязывает скрипт с API Olostep;python-dotenvзагружает ключ API из файла .env;tqdmотображает прогресс сохранения страниц.
Зарегистрируйтесь в Olostep бесплатно, зайдите в дашборд и создайте API-ключ на соответствующей странице. Документация сервиса рекомендует этот способ.
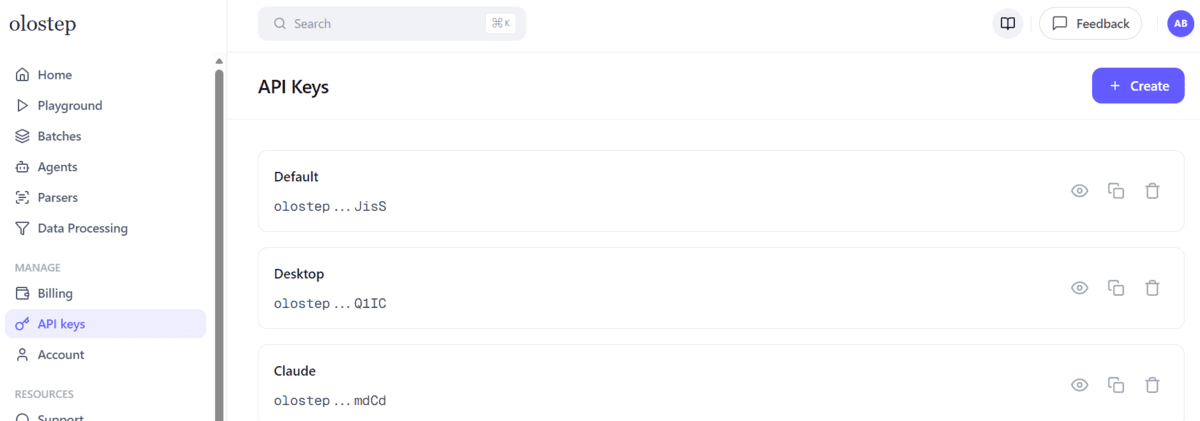
В папке проекта создайте файл .env:
OLOSTEP_API_KEY=your_real_api_key_hereТакой подход отделяет учетные данные от кода, повышая безопасность и удобство.
Разработка скрипта краулера
Теперь составим Python-скрипт, который обойдет сайт документации, извлечет каждую страницу в Markdown, очистит текст и сохранит в отдельные файлы. Создайте папку проекта и файл crawl_docs_with_olostep.py.
Добавляйте код по частям для ясности: каждая секция отвечает за свою функцию, а в итоге они образуют полный краулер.
Настройка параметров краулинга
Импортируйте библиотеки и задайте основные опции: начальный URL, лимит глубины и страниц, правила включения/исключения, папку для Markdown-файлов. Эти параметры определяют объем сбора и место хранения.
import os
import re
from pathlib import Path
from urllib.parse import urlparse
from dotenv import load_dotenv
from tqdm import tqdm
from olostep import Olostep
START_URL = "https://docs.olostep.com/"
MAX_PAGES = 10
MAX_DEPTH = 1
INCLUDE_URLS = [
"/**"
]
EXCLUDE_URLS = []
OUTPUT_DIR = Path("olostep_docs_output")
Функция для безопасных имен файлов
Для сохранения страниц нужны имена файлов без проблемных символов вроде слешей. Функция преобразует URL в подходящий вариант.
def slugify_url(url: str) -> str:
parsed = urlparse(url)
path = parsed.path.strip("/")
if not path:
path = "index"
filename = re.sub(r"[^a-zA-Z0-9/_-]+", "-", path)
filename = filename.replace("/", "__").strip("-_-")
return f"{filename or 'page'}.md"
Функции очистки и сохранения Markdown
Сначала функция удаляет лишний текст интерфейса, пустые строки и элементы вроде запросов отзывов, фокусируясь на сути документации.
def clean_markdown(markdown: str) -> str:
text = markdown.replace("\r\n", "\n").strip()
text = re.sub(r"\[\s*\u200b?\s*\]\(#.*?\)", "", text, flags=re.DOTALL)
lines = [line.rstrip() for line in text.splitlines()]
start_index = 0
for index in range(len(lines) - 1):
title = lines[index].strip()
underline = lines[index + 1].strip()
if title and underline and set(underline) == {"="}:
start_index = index
break
else:
for index, line in enumerate(lines):
if line.lstrip().startswith("# "):
start_index = index
break
lines = lines[start_index:]
for index, line in enumerate(lines):
if line.strip() == "Was this page helpful?":
lines = lines[:index]
break
cleaned_lines: list[str] = []
for line in lines:
stripped = line.strip()
if stripped in {"Copy page", "YesNo", "⌘I"}:
continue
if not stripped and cleaned_lines and not cleaned_lines[-1]:
continue
cleaned_lines.append(line)
return "\n".join(cleaned_lines).strip()
Вторая функция сохраняет очищенный Markdown в папку, добавляя URL в начало. Есть также очистка старых файлов перед новым запуском.
def save_markdown(output_dir: Path, url: str, markdown: str) -> None:
output_dir.mkdir(parents=True, exist_ok=True)
filepath = output_dir / slugify_url(url)
content = f"""---
source_url: {url}
---
{markdown}"""
filepath.write_text(content, encoding="utf-8")
def clear_output_dir(output_dir: Path) -> None:
if not output_dir.exists():
return
for filepath in output_dir.glob("*.md"):
filepath.unlink()
Основная логика краулера
Эта часть загружает ключ, инициализирует клиент Olostep, запускает краулинг, ждет завершения, получает Markdown для страниц, очищает и сохраняет.
Все функции соединяются в рабочий процесс.
def main() -> None:
load_dotenv()
api_key = os.getenv("OLOSTEP_API_KEY")
if not api_key:
raise RuntimeError("Missing OLOSTEP_API_KEY in your .env file.")
client = Olostep(api_key=api_key)
crawl = client.crawls.create(
start_url=START_URL,
max_pages=MAX_PAGES,
max_depth=MAX_DEPTH,
include_urls=INCLUDE_URLS,
exclude_urls=EXCLUDE_URLS,
include_external=False,
include_subdomain=False,
follow_robots_txt=True,
)
print(f"Started crawl: {crawl.id}")
crawl.wait_till_done(check_every_n_secs=5)
pages = list(crawl.pages())
clear_output_dir(OUTPUT_DIR)
for page in tqdm(pages, desc="Saving pages"):
try:
content = page.retrieve(["markdown"])
markdown = getattr(content, "markdown_content", None)
if markdown:
save_markdown(OUTPUT_DIR, page.url, clean_markdown(markdown))
except Exception as exc:
print(f"Failed to retrieve {page.url}: {exc}")
print(f"Done. Files saved in: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
main()
Примечание: Полный скрипт доступен в репозитории kingabzpro/web-crawl-olostep — это краулер с базовым веб-приложением на Olostep.
Проверка скрипта краулинга
Запустите скрипт в терминале:
python crawl_docs_with_olostep.pyВ процессе увидите обработку и сохранение страниц в Markdown.

По окончании проверьте файлы: они содержат чистый Markdown из документации.
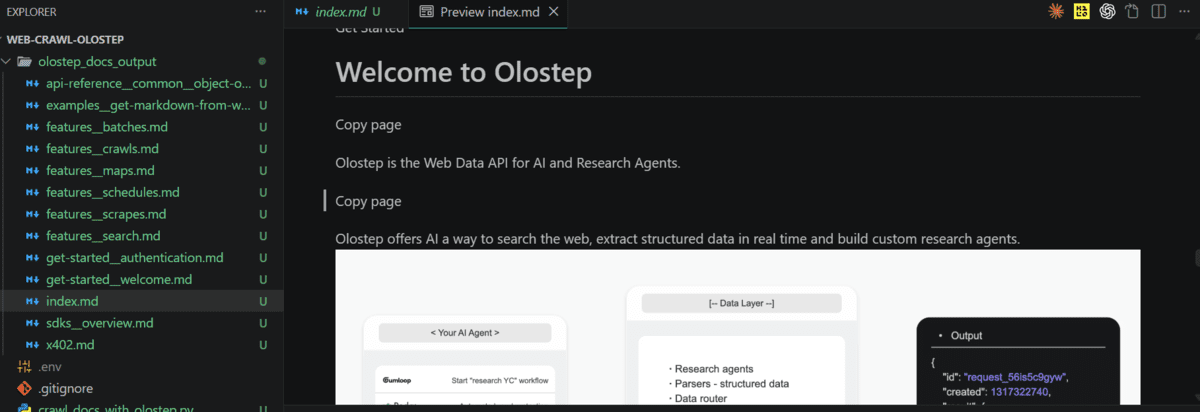
Теперь контент готов для ИИ-применений вроде поиска или агентов.
Веб-приложение для краулинга на Olostep
Построим веб-приложение поверх скрипта. Оно позволит задавать URL, параметры, запускать сбор и просматривать Markdown без правок в коде.
Код интерфейса лежит в app.py репозитория: web-crawl-olostep/app.py.
Приложение поддерживает:
- Ввод стартового URL;
- Лимит страниц;
- Глубину обхода;
- Паттерны включения/исключения;
- Запуск краулера из интерфейса;
- Сохранение в папку по URL;
- Выбор сохраненных Markdown в выпадающем списке;
- Предпросмотр Markdown;
- Очистку результатов кнопкой.
Запустите:
python app.pyGradio поднимет сервер с локальным URL вроде http://127.0.0.1:7860. Для публичной ссылки добавьте share=True в launch().
В браузере протестируйте на документации Claude Code: 50 страниц, глубина 5.
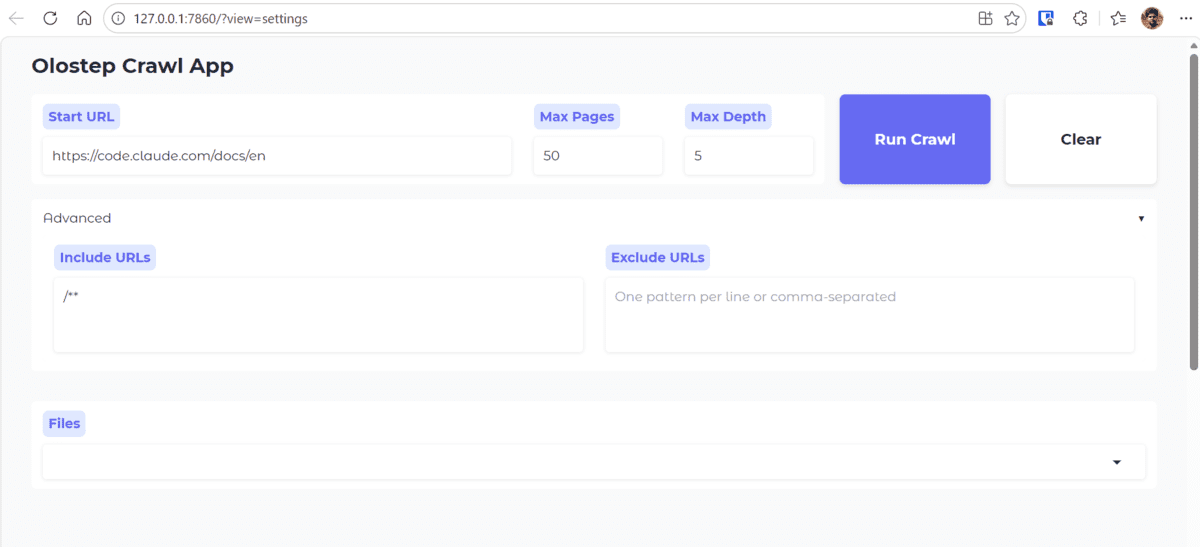
Кнопка Run Crawl передает параметры скрипту. В терминале отслеживайте прогресс.

После завершения в папке появятся 50 Markdown-файлов.
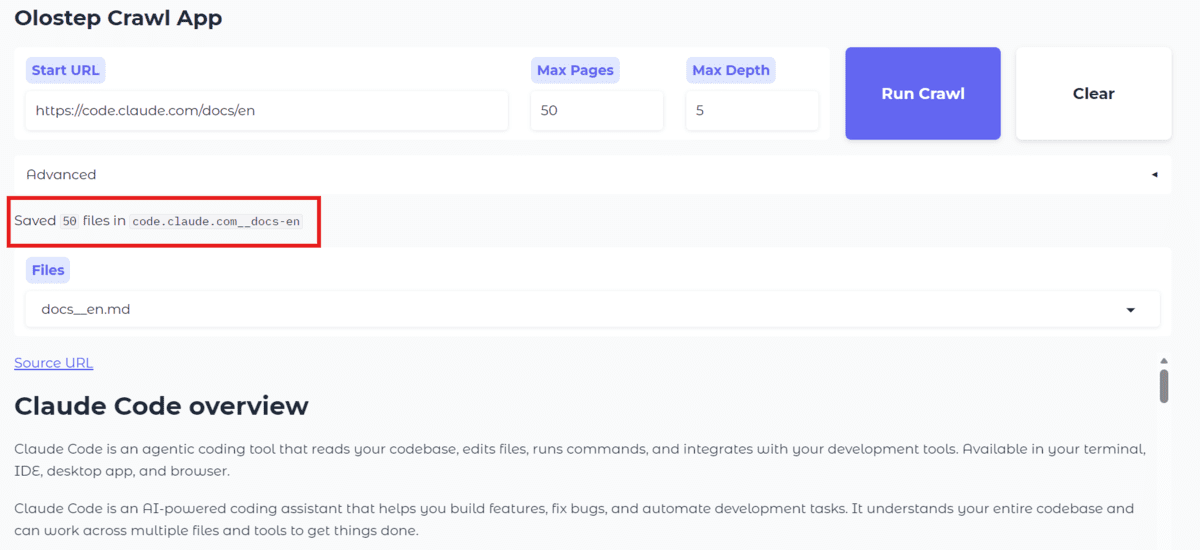
Выпадающий список обновится для предпросмотра файлов в интерфейсе.
Интерфейс упрощает тестирование сайтов и параметров, делая проект доступным без глубокого знания Python.
Итоги
Краулинг — это не просто сбор страниц, а их превращение в структурированные файлы для ИИ. Python-скрипт и Gradio-приложение решают задачу просто.
Скорость высока: 50 страниц на глубине 5 занимают около 50 секунд, без сложных пайплайнов.
Подход масштабируется: планируйте ежедневные запуски через cron или Task Scheduler, обновляя только изменения. Это экономит ресурсы.
Olostep выгоднее внутренних решений или аналогов — минимум на 50% дешевле, с убывающей стоимостью запросов при росте. Такая комбинация надежности и экономики привлекает растущие ИИ-стартапы для инфраструктуры данных.