
Введение
Появление больших языковых моделей вроде GPT-4, Llama и Claude перевернуло сферу искусственного интеллекта. Такие системы уверенно генерируют код, дают ответы на вопросы и обобщают содержимое документов. Дата-сайентистам открываются захватывающие перспективы, но возникает серьезный вызов: успех моделей полностью зависит от данных, на которых они работают.
Обсуждения в основном крутятся вокруг самих сетей и механизмов внимания, однако незаслуженно забывают про инженерию данных — настоящую основу успеха в эпоху LLM. Принципы работы с данными не отходят на второй план, а получают развитие.
Далее разберем эволюцию роли данных, необходимые пайплайны для этапов обучения и инференса, а также архитектуры вроде RAG, которые задают тон созданию приложений на базе ИИ.
От бизнес-аналитики к данным для ИИ
Раньше инженерия данных в основном обслуживала бизнес-аналитику. Задача состояла в переносе информации из операционных баз, например записей транзакций, в хранилища. Данные были структурированными, очищенными, организованными в таблицы для запросов вроде «Какие продажи были в прошлом квартале?».
Сегодня требования выросли: нужно обслуживать ИИ. Это значит работать с неструктурированными источниками — текстами из PDF, записями звонков клиентов, репозиториями кода на GitHub. Цель — не просто собрать такой контент, а преобразовать его, чтобы модель могла его осмыслить.
Для этого создаются специализированные пайплайны, учитывающие разные типы данных и готовящие их для трех этапов жизненного цикла LLM:
- Предобучение и дообучение: базовое обучение модели или настройка под конкретную задачу.
- Инференс и рассуждения: предоставление модели свежей информации во время запроса.
- Оценка и мониторинг: контроль точности, безопасности и отсутствия предвзятости.
Теперь рассмотрим задачи инженерии данных на каждом этапе.
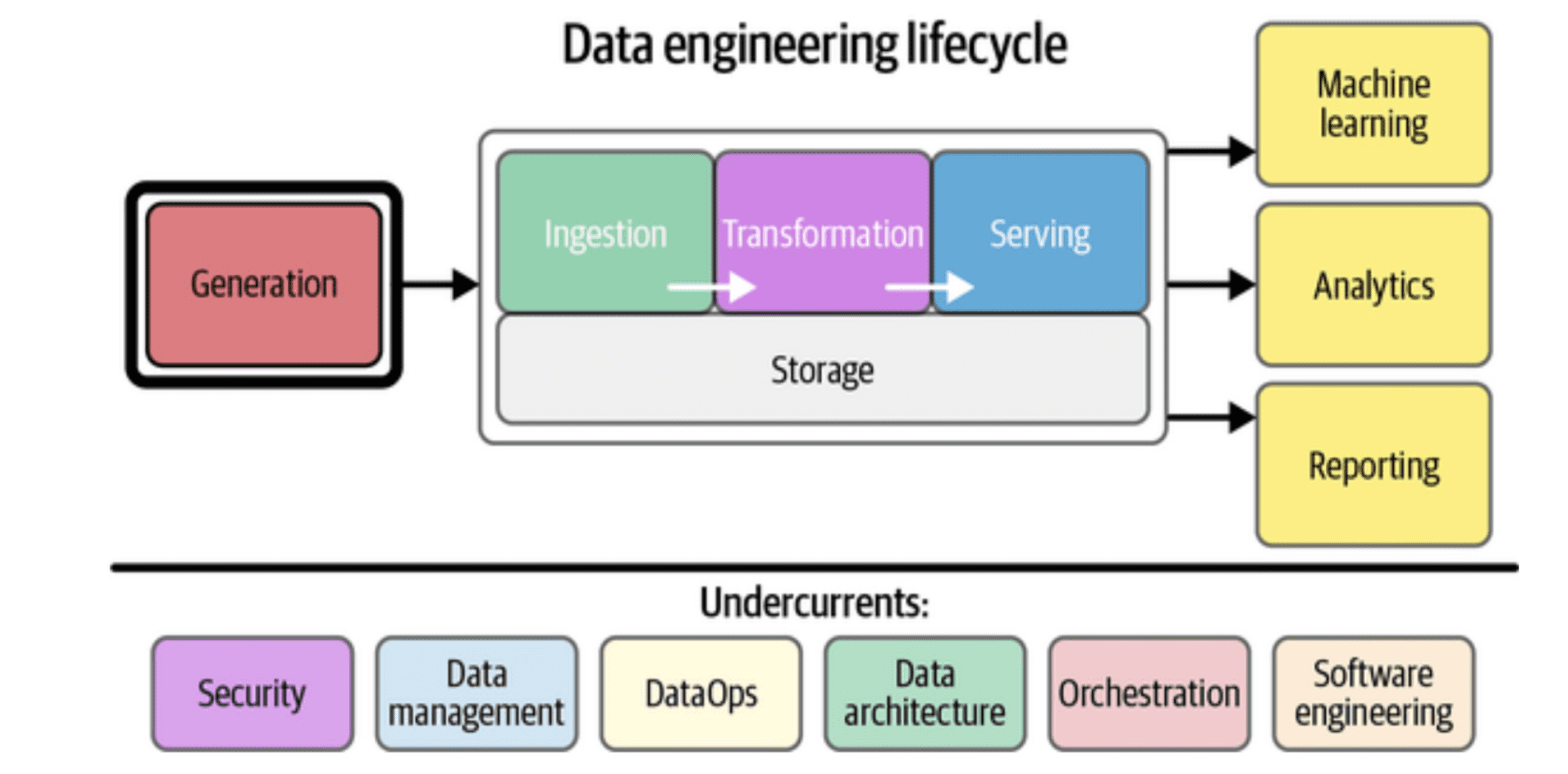
Фаза 1: Данные для обучения LLM
Чтобы модель приносила пользу, ее сначала обучают. Это масштабная работа по инженерии данных. Нужно собрать качественный массив текстов, отражающий значительную часть человеческих знаний. Разберем ключевые аспекты данных для обучения.
Три столпа данных для обучения
При формировании датасета для предобучения или дообучения LLM инженеры данных акцентируют внимание на трех направлениях:
- Модели осваивают закономерности статистически. Для понимания нюансов грамматики и логики требуется триллионы токенов (фрагментов слов). Это подразумевает обработку петабайт данных из Common Crawl, GitHub, научных статей и веб-архивов. Огромные объемы требуют распределенных систем вроде Apache Spark.
- Модель, обученная только на юридических текстах, не сможет сочинять стихи. Для широкого применения нужны разнообразные источники. Пайплайны собирают данные из тысяч доменов, обеспечивая баланс.
- Качество — определяющий фактор. Интернет полон шума, спама, шаблонных фраз (типа меню сайтов) и ошибок. Исследование Databricks «The Secret Sauce behind 1,000x LLM Training Speedups» показало: качество данных часто важнее архитектуры модели.
- Пайплайны исключают низкокачественный контент: удаляют дубликаты (почти идентичные фразы или абзацы), отсеивают нецелевой язык, вредный материал.
- Важно отслеживать происхождение данных. Если модель выдает неожиданный результат, нужно проследить до источника. Это data lineage — инструмент для соответствия нормам и отладки.
Дата-сайентист, осознавший, что модель не лучше своих данных, на шаг ближе к созданию стабильных систем.
Фаза 2: Архитектура RAG
Обучение базовой модели — огромный труд, но большинству компаний это не нужно. Вместо этого берут готовую модель и подключают свои данные. Здесь лидирует Retrieval-Augmented Generation (RAG).
RAG решает проблему устаревания знаний: модель из 2022 года не знает событий 2023-го. Архитектура позволяет «заглядывать» в актуальную информацию.
Типичный пайплайн для RAG с LLM выглядит так:
- Внутренние документы (PDF, страницы Confluence, архивы Slack). Инженер данных организует их загрузку.
- Окно контекста LLM ограничено. Нельзя закинуть 500-страничный мануал целиком. Документы разбивают на фрагменты (по несколько абзацев).
- Каждый фрагмент превращают в числовой вектор с помощью модели эмбеддингов — последовательности чисел, кодирующей смысл текста.
- Векторы сохраняют в векторной базе данных для быстрого доступа.
На запрос пользователя процесс идет в обратную сторону:
- Запрос превращают в вектор той же моделью эмбеддингов.
- Векторная база находит семантически близкие фрагменты.
- Релевантные куски передают LLM вместе с запросом и промптом вроде «Отвечай только на основе этого контекста».
Вызовы инженерии данных
Эффективность RAG зависит от пайплайна загрузки. Плохое разбиение ломает контекст, неподходящие эмбеддинги приводят к нерелевантным результатам. Инженеры данных настраивают эти параметры и создают надежные цепочки.
Фаза 3: Современный стек данных для LLM
Для таких пайплайнов формируется новый набор инструментов, заточенный под векторный поиск и координацию LLM. Дата-сайентисту предстоит освоить этот стек.
- Векторные базы данных: основа RAG. В отличие от традиционных, ищущих по ключевым словам, они работают по смыслу.
- Фреймворки оркестрации: связывают промпты, вызовы LLM и поиск в единое приложение.
- Примеры: LangChain, LlamaIndex. Они предлагают коннекторы к векторным хранилищам и шаблоны для RAG.
- Обработка данных: классический ETL (Extract, Transform, Load) остается востребованным. Spark помогает очищать и готовить датасеты для дообучения.
Новый стек дополняет старый: хранилища вроде Snowflake или BigQuery нужны для структурированной аналитики, а векторные — для ИИ-функций.

Фаза 4: Оценка и мониторинг
Завершает картину оценка. В классическом машинном обучении хватало метрик вроде точности (кошка это или собака?). Генеративный ИИ сложнее: правильный ли абзац? Ясный? Безопасный?
Инженерия данных помогает через мониторинг LLM. Трекинг потоков данных позволяет разбираться в сбоях.
Представьте RAG-приложение с неверным ответом. Причины?
- Релевантный документ не попал в векторную базу? (Сбой загрузки)
- Документ есть, но поиск его не нашел? (Сбой поиска)
- Документ нашли, но LLM его проигнорировал и выдумал? (Сбой генерации)
Пайплайны логируют запрос, контекст и ответ. Анализ выявляет узкие места, отсеивает плохие поиски, генерирует датасеты для дообучения. Это замыкает цикл, превращая приложение в систему непрерывного улучшения.
Итоги
ИИ становится главным способом взаимодействия с данными. Для дата-сайентистов это шанс: умение очищать, структурировать и управлять данными ценится как никогда.
Контекст усложнился. Неструктурированные данные требуют той же тщательности, что и таблицы. Нужно понимать влияние обучающих данных на поведение модели. Осваивайте пайплайны для RAG.
Инженерия данных — фундамент надежных, точных и безопасных систем ИИ. Освоив эти принципы, вы строите инфраструктуру будущего.