
Введение
Ежедневно службы поддержки фиксируют тысячи разговоров с клиентами. В этих аудиофайлах скрыты ценные данные: насколько довольны покупатели, какие жалобы возникают чаще всего, как меняется эмоциональный фон во время беседы.
Ручной разбор таких записей — трудоёмкий процесс. Но современные технологии ИИ позволяют автоматизировать транскрипцию звонков, распознавание эмоций и выделение ключевых тем — и всё это без интернета, на базе открытых инструментов.
В этой статье разберём полный проект анализатора настроения клиентов. Вы узнаете, как:
- Преобразовывать аудио в текст с помощью Whisper.
- Определять настроение (положительное, отрицательное, нейтральное) и эмоции (раздражение, удовлетворение, срочность).
- Автоматически находить темы с использованием BERTopic.
- Визуализировать результаты в интерактивной панели.
Главное преимущество — вся обработка происходит на вашем устройстве. Конфиденциальные данные клиентов остаются в безопасности.
Зачем локальный ИИ для данных клиентов
Облачные сервисы вроде API от OpenAI дают мощные возможности, но создают риски: утечка личных данных из звонков, растущие расходы по тарифам за вызовы API при больших объёмах и зависимость от сети с лимитами. Локальная работа упрощает соблюдение правил хранения данных.
Этот гид по распознаванию речи с помощью ИИ держит всё на локальном железе. Модели загружаются один раз и функционируют без сети.
Требования
Перед началом убедитесь, что у вас есть:
- Python 3.9 или новее.
- FFmpeg для работы с аудио.
- Базовые знания Python и машинного обучения.
- Около 2 ГБ на диске для моделей ИИ.
Настройка проекта
Склонируйте репозиторий и подготовьте окружение:
git clone https://github.com/zenUnicorn/Customer-Sentiment-analyzer.gitСоздайте виртуальное окружение:
python -m venv venvАктивация на Windows:
.\venv\Scripts\ActivateАктивация на Mac/Linux:
source venv/bin/activateУстановите зависимости:
pip install -r requirements.txtПри первом запуске скачиваются модели ИИ (всего ~1,5 ГБ). Далее всё идёт оффлайн.
Распознавание речи с Whisper
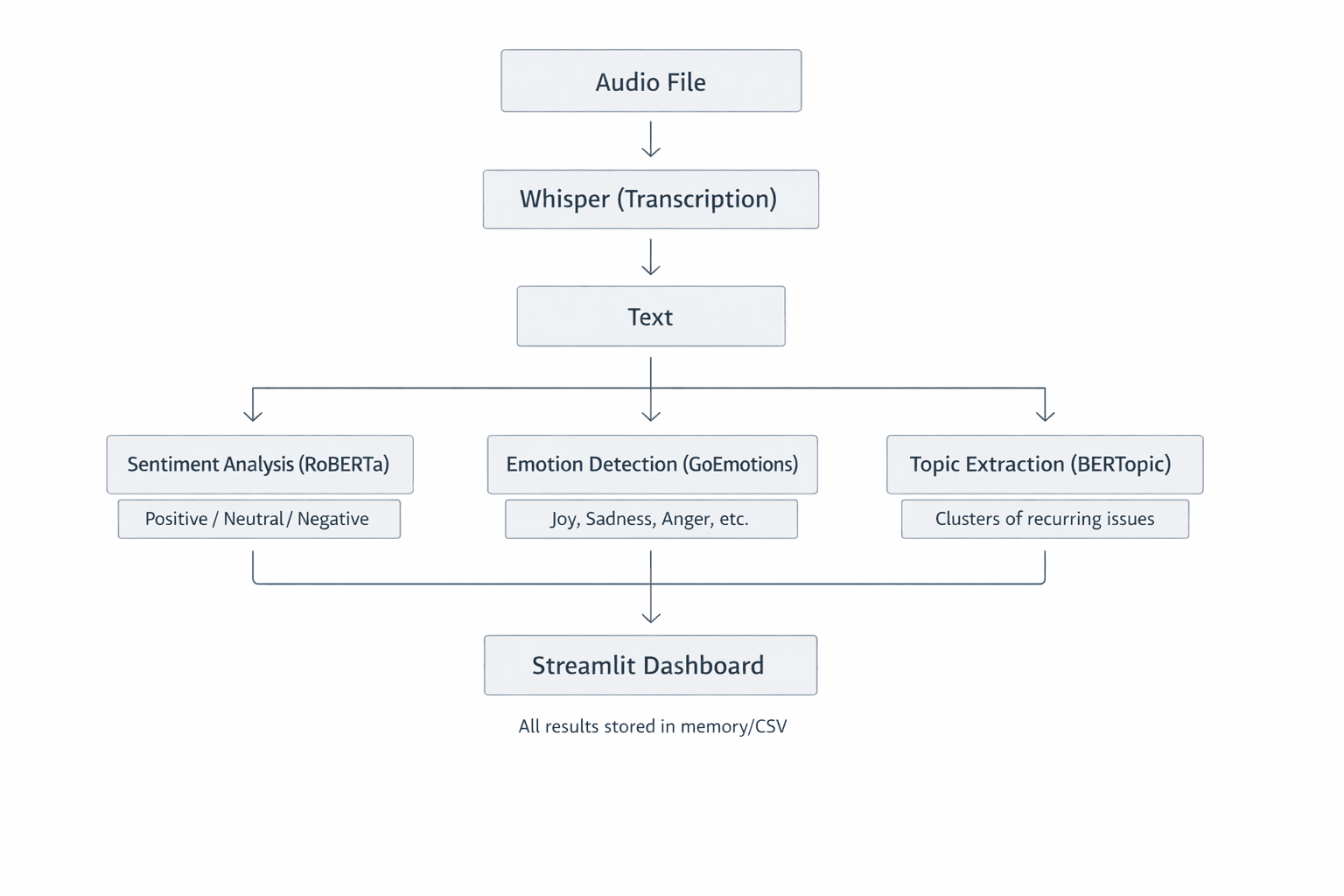
Первый этап в анализаторе — преобразование устной речи из записей звонков в текст. За это отвечает Whisper — система автоматического распознавания речи от OpenAI. Разберём принцип работы, преимущества и применение в проекте.
Whisper — модель на базе Transformer с энкодером-декодером, обученная на 680 000 часов многоязычного аудио. При подаче файла она:
- Приводит звук к 16 кГц моно.
- Создаёт мел-спектрограмму — визуализацию частот во времени, как фото звука.
- Разбивает на сегменты по 30 секунд.
- Пропускает через энкодер для скрытых представлений.
- Декодирует в текстовые токены по одному слову или подслову.
Мел-спектрограмма — способ, которым машины "видят" звук: ось X — время, Y — частота, цвет — громкость. Получается точная расшифровка даже при шуме или акцентах.
Реализация в коде
Основная логика транскрипции:
import whisper
class AudioTranscriber:
def __init__(self, model_size="base"):
self.model = whisper.load_model(model_size)
def transcribe_audio(self, audio_path):
result = self.model.transcribe(
str(audio_path),
word_timestamps=True,
condition_on_previous_text=True
)
return {
"text": result["text"],
"segments": result["segments"],
"language": result["language"]
}Параметр model_size балансирует точность и скорость.
| Модель | Параметры | Скорость | Применение |
|---|---|---|---|
| tiny | 39M | Самая быстрая | Быстрые тесты |
| base | 74M | Быстрая | Разработка |
| small | 244M | Средняя | Производство |
| large | 1550M | Медленная | Максимальная точность |
Для типичных задач подойдут base или small.
Анализ настроения на Transformers
Получив текст, переходим к оценке настроения с помощью Hugging Face Transformers. Применяем модель RoBERTa от CardiffNLP twitter-roberta-base-sentiment-latest, заточенную под разговорный текст соцсетей — идеально для клиентских диалогов.
Настроение против эмоций
Анализ настроения делит текст на положительный, нейтральный или отрицательный. RoBERTa с дообучением лучше простого поиска ключевых слов, так как учитывает контекст.
Текст токенизируется и проходит Transformer. Финальный слой с softmax даёт вероятности, суммирующиеся в 1. Если положительное — 0,85, нейтральное — 0,10, отрицательное — 0,05, то общее настроение положительное.
- Настроение: полярность (положительное, отрицательное, нейтральное) — "хорошо или плохо?".
- Эмоции: конкретные чувства (гнев, радость, страх) — "что именно чувствуют?".
Определяем оба для полной картины.
Реализация анализа настроения
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch.nn.functional as F
class SentimentAnalyzer:
def __init__(self):
model_name = "cardiffnlp/twitter-roberta-base-sentiment-latest"
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
def analyze(self, text):
inputs = self.tokenizer(text, return_tensors="pt", truncation=True)
outputs = self.model(**inputs)
probabilities = F.softmax(outputs.logits, dim=1)
labels = ["negative", "neutral", "positive"]
scores = {label: float(prob) for label, prob in zip(labels, probabilities[0])}
return {
"label": max(scores, key=scores.get),
"scores": scores,
"compound": scores["positive"] - scores["negative"]
}Составной compound-балл от -1 (очень отрицательное) до +1 (очень положительное) удобен для отслеживания динамики.
Почему не простые словари
Классические методы вроде VADER считают положительные и отрицательные слова. Но они игнорируют контекст:
- "Это не хорошо." Словарь видит "хорошо" как плюс.
- Transformer понимает отрицание ("не").
Transformers улавливают связи между словами, что делает их точнее для живого текста.
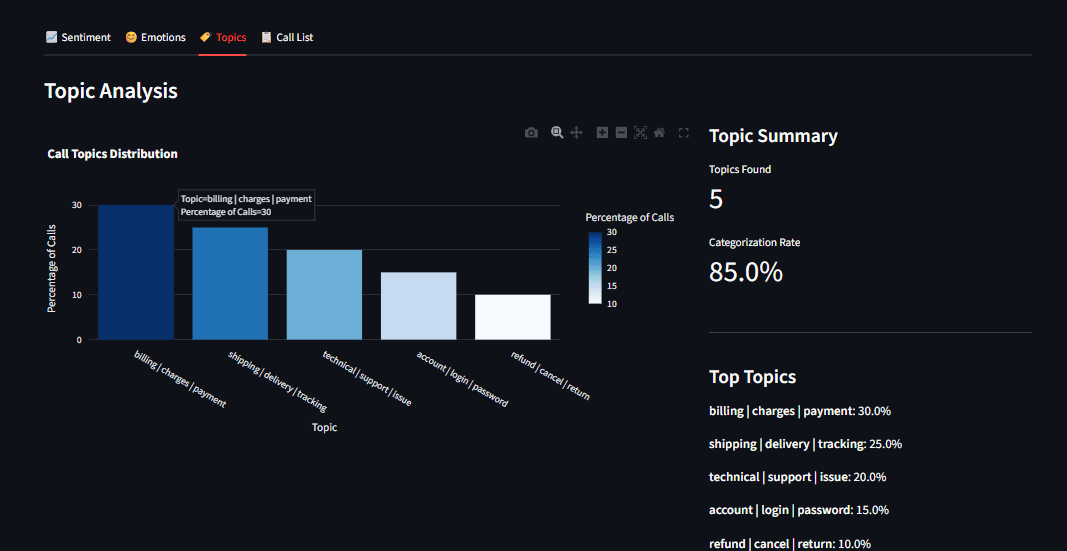
Выделение тем с BERTopic
Настроение важно, но о чём говорят клиенты? BERTopic находит темы автоматически, без предварительных списков.
Принцип работы BERTopic
- Встраивания: каждый текст в вектор через Sentence Transformers.
- Сжатие размерности: UMAP упрощает векторы.
- Кластеризация: HDBSCAN группирует похожие тексты.
- Представление тем: ключевые слова по c-TF-IDF для кластера.
Выход — темы вроде "проблемы с оплатой", "техподдержка", "отзывы о товаре". В отличие от LDA, BERTopic понимает смысл: "задержка доставки" и "поздняя отправка" в одном кластере.
Реализация в коде
Из topics.py:
from bertopic import BERTopic
class TopicExtractor:
def __init__(self):
self.model = BERTopic(
embedding_model="all-MiniLM-L6-v2",
min_topic_size=2,
verbose=True
)
def extract_topics(self, documents):
topics, probabilities = self.model.fit_transform(documents)
topic_info = self.model.get_topic_info()
topic_keywords = {
topic_id: self.model.get_topic(topic_id)[:5]
for topic_id in set(topics) if topic_id != -1
}
return {
"assignments": topics,
"keywords": topic_keywords,
"distribution": topic_info
}Примечание: для тем нужно 5–10 документов. Одиночные звонки анализируются на обученной модели.
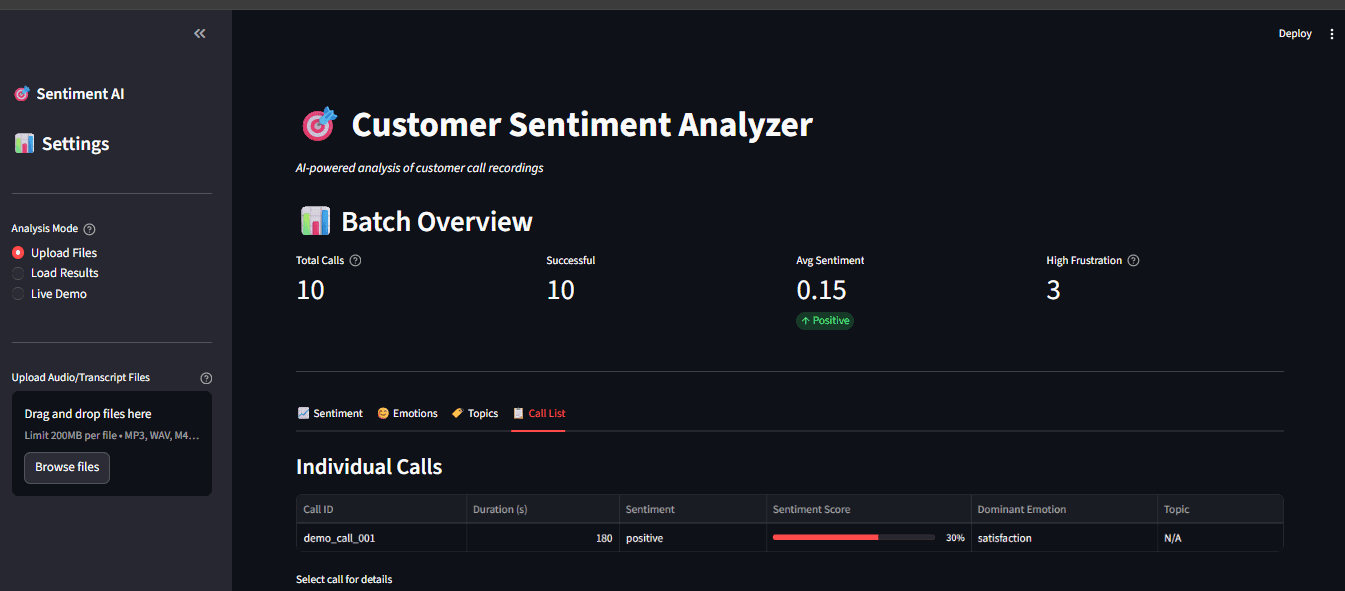
Интерактивная панель на Streamlit
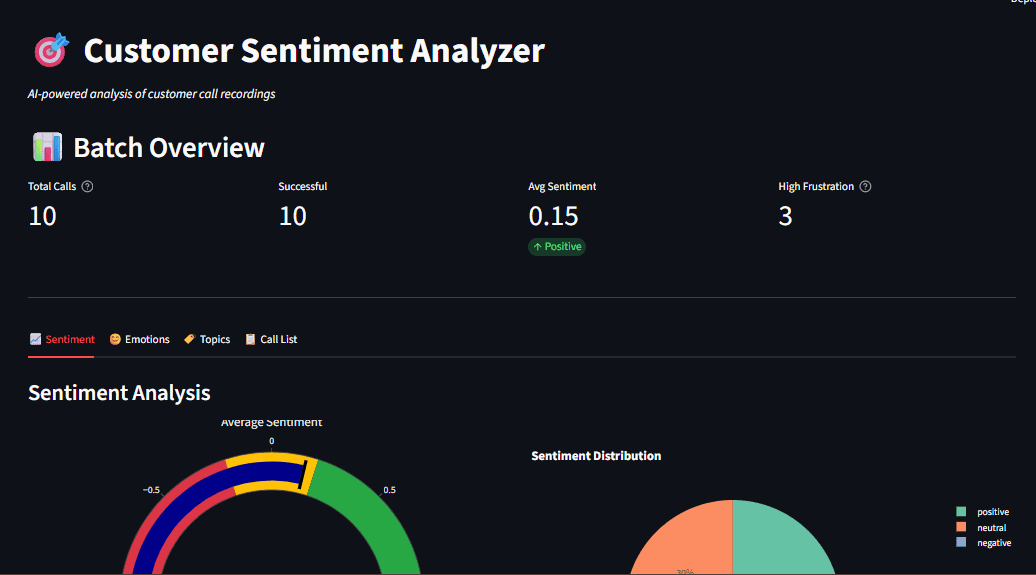
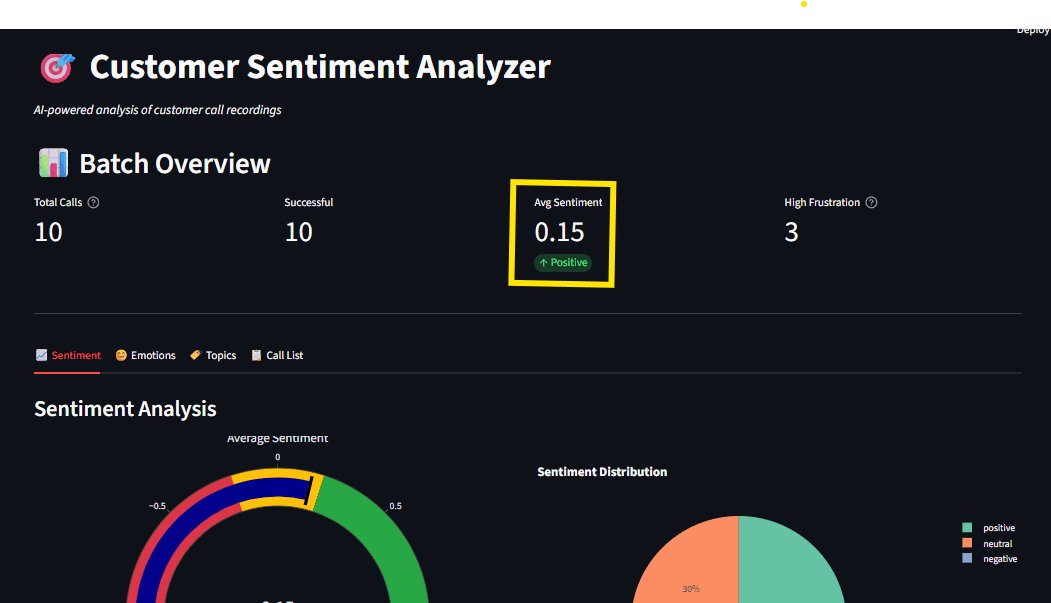
Сырые данные трудно понять. Мы создали дашборд на Streamlit (app.py), чтобы специалисты могли удобно изучать результаты. Streamlit превращает Python-скрипты в веб-приложения с минимумом усилий. Дашборд предлагает:
- Загрузку аудиофайлов.
- Обработку в реальном времени с индикаторами прогресса.
- Интерактивные графики на Plotly.
- Детальный просмотр отдельных звонков.
Структура дашборда
import streamlit as st
def main():
st.title("Customer Sentiment Analyzer")
uploaded_files = st.file_uploader(
"Upload Audio Files",
type=["mp3", "wav"],
accept_multiple_files=True
)
if uploaded_files and st.button("Analyze"):
with st.spinner("Processing..."):
results = pipeline.process_batch(uploaded_files)
# Display results
col1, col2 = st.columns(2)
with col1:
st.plotly_chart(create_sentiment_gauge(results))
with col2:
st.plotly_chart(create_emotion_radar(results))Кэширование Streamlit @st.cache_resource загружает модели один раз, обеспечивая отзывчивость.
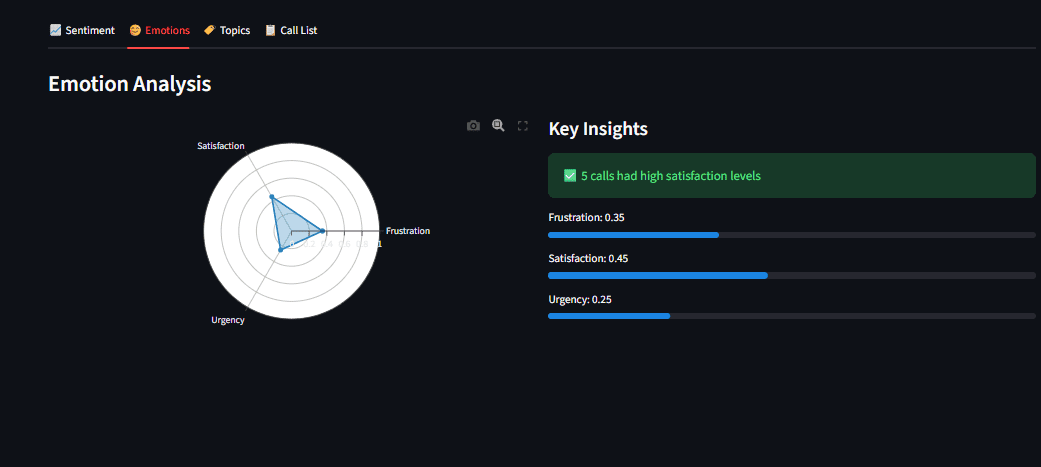
Ключевые возможности
- Загрузка аудио (или тестовые транскрипты).
- Просмотр транскрипта с выделением настроения.
- Хронология эмоций (для длинных звонков).
- Визуализация тем в интерактивных графиках Plotly.
Кэширование для скорости
Streamlit перезапускает скрипт при взаимодействиях. Чтобы не перезагружать модели, используем @st.cache_resource:
@st.cache_resource
def load_models():
return CallProcessor()
processor = load_models()Обработка в реальном времени
При загрузке файла показывается спиннер, затем результаты:
if uploaded_file:
with st.spinner("Transcribing and analyzing..."):
result = processor.process_file(uploaded_file)
st.success("Done!")
st.write(result["text"])
st.metric("Sentiment", result["sentiment"]["label"])Практические выводы
Обработка аудио: от волны к тексту
Сила Whisper — в мел-спектрограмме. Человеческий слух логарифмический: низкие частоты различимы лучше высоких. Мел-шкала имитирует это, модель "слышит" как человек. Спектрограмма — 2D-изображение (время против частоты), Transformer обрабатывает его как патч изображения. Поэтому шум не мешает — видна вся картина.
Выходы Transformer: softmax против sigmoid
- Softmax (настроение): вероятности в сумме 1, для взаимоисключающих классов — текст редко одновременно положительный и отрицательный.
- Sigmoid (эмоции): классы независимы, текст может быть радостным и удивлённым. Sigmoid допускает пересечения.
Правильная активация зависит от задачи.
Визуализация для понимания
Хороший дашборд не просто цифры — он рассказывает историю. Графики Plotly интерактивны: наведение показывает детали, зум по времени, клик по легенде скрывает серии. Это превращает аналитику в действия.
Запуск приложения
Следуйте шагам из начала. Тестируйте без аудио:
python main.py --demoЭто пропустит образцы через модели NLP и выведет в терминал.
Один файл:
python main.py --audio path/to/call.mp3Пакетная обработка:
python main.py --batch data/audio/Полная панель:
python main.py --dashboardОткройте http://localhost:8501 в браузере.
Заключение
Мы собрали полноценную систему, работающую оффлайн: транскрибирует звонки, оценивает настроение и эмоции, находит повторяющиеся темы — на открытых инструментах. Это база для:
- Команд поддержки — выявление болевых точек.
- Менеджеров продуктов — сбор отзывов массово.
- Контроля качества — мониторинг агентов.
Всё локально — конфиденциальность на первом месте, без расходов на API.