
Введение
Большинство команд приходит к необходимости feature store (хранилища признаков) через боль. Модель детекции мошенничества прекрасно работает в ноутбуке и незаметно ломается в продакшене. Сотрудник поддержки отвечает шаблонно, потому что ничего не знает о пользователе. Пайплайн рекомендательной системы трижды дублирует расчет «трат за 30 дней» в разных задачах, и две из них выдают разные цифры.
Feature store — это элемент инфраструктуры, решающий эти проблемы. Признаки определяются один раз, хранятся в двух формах (одна для обучения, другая для инференса) и синхронизируются между собой. Мы построим минимальную версию с нуля на Python, используя DuckDB, Parquet, Redis и FastAPI. Затем посмотрим, как AI-приложения меняют наши сценарии использования этого компонента.
Код достаточно короткий, чтобы разобрать каждый компонент шаг за шагом.
Какие проблемы решает Feature Store
Классическая задача — расхождение между обучением и инференсом (training-serving skew): SQL, собиравший обучающую выборку, — это не тот же код, который исполняется при предсказании, и значения начинают «плыть». Эта проблема реальна, и стандартное решение — разделение на офлайн- и онлайн-хранилища.
Современная задача шире. LLM-агенты и RAG-пайплайны требуют структурированного контекста о пользователе на этапе инференса — при каждом запросе и быстрее 10 мс. У языковой модели нет памяти о том, кто перед ней. Чтобы получить персонализированный ответ, нужно внедрить в промт тарифный план пользователя, недавнюю активность и состояние аккаунта — а для этого нужна система, которая быстро и согласованно возвращает эти значения. Именно это дают онлайн-хранилище и retrieval API внутри feature store.
Поэтому строим и для того, и для другого. Одни и те же пять компонентов закрывают и кейс предиктивного машинного обучения, и кейс подачи контекста для LLM.
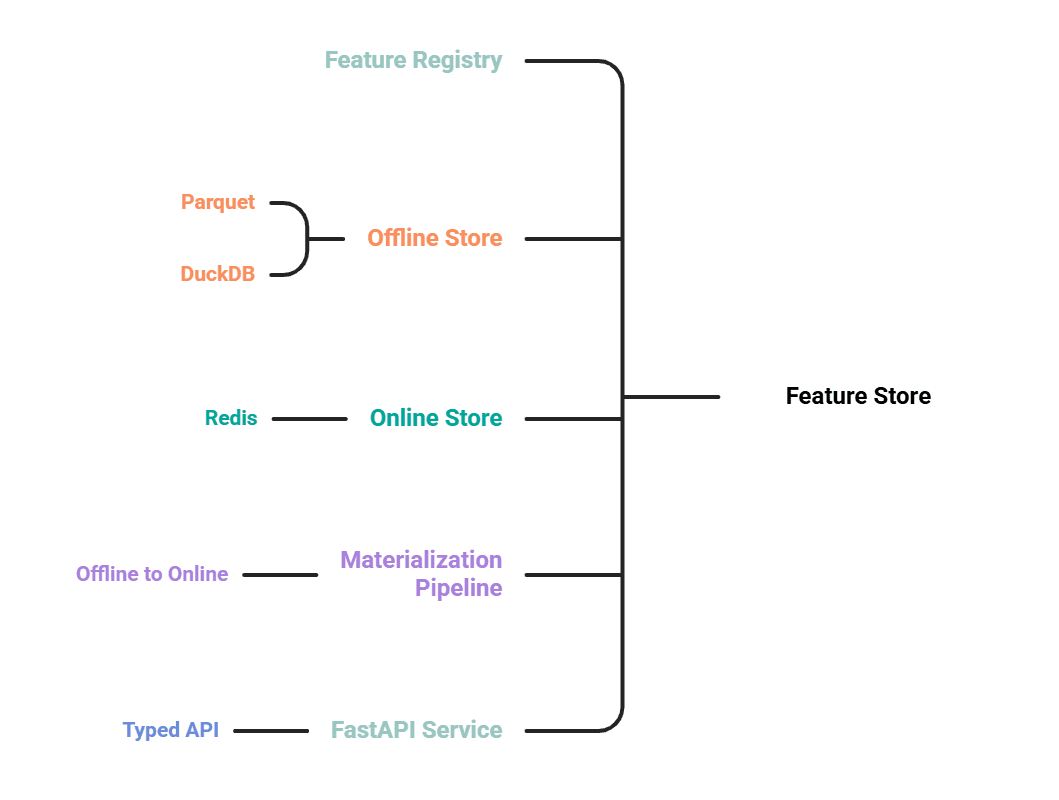
Пять компонентов
- Реестр признаков (feature registry), определяющий признаки как код.
- Офлайн-хранилище на Parquet, запросы через DuckDB — для обучения и обратного наполнения (backfill).
- Онлайн-хранилище на Redis для низко-латентных поисков при инференсе.
- Пайплайн материализации, проталкивающий свежие значения из офлайна в онлайн.
- Сервис на FastAPI, предоставляющий типизированный retrieval API.
Сквозной пример: персональный LLM-рекомендатель
Представьте стриминговый сервис. Когда пользователь открывает приложение, языковая модель генерирует короткое персональное сообщение «что посмотреть дальше». Модели нужны три факта о пользователе:
| Признак | Тип | Свежесть |
|---|---|---|
user_segment | строка | раз в сутки |
watch_count_30d | целое | раз в час |
last_genre | строка | на каждое событие |
Сущность — user_id. Мы зарегистрируем эти три признака, материализуем их и подадим модели в момент запроса.
1. Определение реестра признаков
Реестр — это место, где признаки объявляются единожды, вместе с сущностью, типом данных и источником. Используем датакласс.
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Feature:
name: str
entity: str
dtype: Literal["int", "float", "str"]
source: str # путь к Parquet-файлу или SQL-представлению
REGISTRY: dict[str, Feature] = {
"user_segment": Feature(
"user_segment", "user_id", "str", "data/user_segment.parquet"
),
"watch_count_30d": Feature(
"watch_count_30d", "user_id", "int", "data/watch_count_30d.parquet"
),
"last_genre": Feature(
"last_genre", "user_id", "str", "data/last_genre.parquet"
),
}Полный код доступен здесь.
Вывод при запуске:
Registered features:
user_segment entity=user_id dtype=str source=data/user_segment.parquet
watch_count_30d entity=user_id dtype=int source=data/watch_count_30d.parquet
last_genre entity=user_id dtype=str source=data/last_genre.parquetЭто контракт. Каждый следующий компонент читает из REGISTRY, поэтому переименование признака, смена типа данных или перенаправление на новый источник делаются в одном месте. В продакшен-системах это обычно YAML или Python-модуль в Git-репозитории, и каждое изменение проходит код-ревью.
2. Сборка офлайн-хранилища на DuckDB и Parquet
Офлайн-хранилище содержит полную историю всех значений признаков. Слой хранения — Parquet-файлы, движок запросов — DuckDB. DuckDB читает Parquet напрямую, а значит, не нужна отдельная база данных.
Ключевой фрагмент:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame,
features: list[str]
) -> pd.DataFrame:
con = duckdb.connect()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
con.execute(
f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'"
)
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()Полный код — здесь.
Результат работы:
| user_id | event_timestamp | user_segment | watch_count_30d | last_genre |
|---|---|---|---|---|
| 8a2f | 2026-05-05 12:00:00 | casual | 22 | NaN |
| b13c | 2026-05-07 20:00:00 | casual | 5 | thriller |
| 8a2f | 2026-05-07 22:00:00 | power_user | 47 | documentary |
AsOf join — это point-in-time join. Для каждой строки сущности он берет самое свежее значение признака, у которого временная метка не позже метки события. Именно это предотвращает утечку данных (leakage) — ситуацию, когда строка обучающей выборки собирается со значением признака, которого еще не существовало на момент предсказания.
Point-in-time join'ы остаются правильным решением для любой модели, которую мы планируем обучать или дообучать. Для чисто инференсного LLM-кейса эта функция может вообще не вызываться. Но офлайн-хранилище всё равно необходимо — именно оттуда берутся backfill'ы, датасеты для оценки и аудита.
3. Настройка онлайн-хранилища на Redis
Онлайн-хранилище хранит только последнее значение для каждой сущности. Redis — стандартный выбор, потому что поиск по хешу занимает доли миллисекунды.
import json
import fakeredis # в продакшене используйте redis.Redis() против реального сервера
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={k: json.dumps(v) for k, v in values.items()},
)
def read_online(
entity: str, entity_id: str, features: list[str]
) -> dict:
raw = r.hmget(f"{entity}:{entity_id}", features)
return {
f: json.loads(v) if v else None
for f, v in zip(features, raw)
}Полный код — здесь.
Пример вывода:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
missing key -> {'user_segment': None}Формат ключа — entity:entity_id. Значение — хеш, в котором каждое поле соответствует одному признаку. Один вызов HMGET возвращает все запрошенные признаки за один сетевой обмен. На локальном инстансе Redis с тремя признаками операция выполняется заметно быстрее 1 мс.
4. Запуск пайплайна материализации
Материализация переносит значения из офлайн-хранилища в онлайн. В реальной системе это запускается по расписанию (Airflow, cron, стриминговая задача). Здесь это просто функция.
def materialize(features: list[str]) -> None:
by_entity: dict[str, dict] = {}
for fname in features:
f = REGISTRY[fname]
src = f.source.replace("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row[f.entity], {})[fname] = row[fname]
for entity_id, values in by_entity.items():
write_online("user_id", entity_id, values)Полный код — здесь.
Результат:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'casual', 'watch_count_30d': 5, 'last_genre': 'thriller'}Конструкция QUALIFY оставляет последнюю строку для каждой сущности. Мы группируем все признаки одного пользователя в одну запись в Redis, чтобы сократить число сетевых обменов. Запускайте пайплайн с той периодичностью, какую требует каждый признак: раз в час для watch_count_30d, почти в реальном времени для last_genre, раз в сутки для user_segment. В реальной реализации именно реестр — правильное место, чтобы закодировать эту периодичность.
5. Создание сервиса извлечения признаков на FastAPI
Сервис извлечения — это продакшен-интерфейс. Именно его вызывает LLM-приложение.
f = resp.json()["features"]
print("\nPrompt the LLM would receive:")
print(
f" System: You recommend shows for a streaming service.\n"
f" User context: segment={f['user_segment']}, "
f"watched {f['watch_count_30d']} titles in last 30 days, "
f"last genre watched: {f['last_genre']}.\n"
f" Task: suggest 3 titles in a friendly, short message."
)Полный код — здесь.
Пример ответа и формируемого промта:
POST /get-online-features -> 200
body: {'user_id': '8a2f', 'features': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
Prompt the LLM would receive:
System: You recommend shows for a streaming service.
User context: segment=power_user, watched 47 titles in last 30 days, last genre watched: documentary.
Task: suggest 3 titles in a friendly, short message.Feature store — это тот самый компонент, который превращает «пользователя 8a2f» в структурированный контекст, пригодный для использования языковой моделью.
Где заканчивается Feature Store и начинается векторная база данных
Векторная база данных (Pinecone, Weaviate, pgvector) — не feature store, хотя обе системы находятся перед моделью на этапе инференса. Они решают разные задачи поиска.
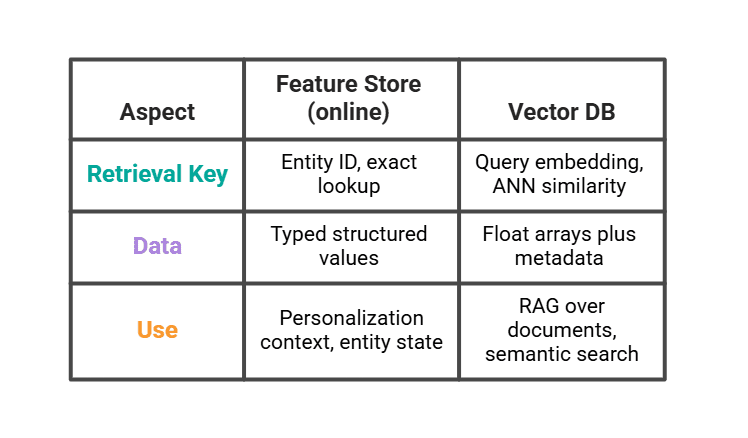
Реальный LLM-стек использует и то, и другое. Векторная база возвращает три самых похожих прошлых сеанса просмотра. Feature store отдаёт сегмент пользователя и недавние счетчики. Промт собирает всё вместе.
Типичные антипаттерны
Несколько схем, которые регулярно приводят к проблемам:
- Вычисление признаков внутри модельного сервиса. Одна и та же логика оказывается и в ноутбуке для обучения, и в API — и две версии расходятся уже через квартал.
- Отношение к онлайн-хранилищу как к источнику истины. Redis теряет данные при неудачном перезапуске. Канонический источник — офлайн-хранилище, онлайн — это кеш.
- Пропуск реестра. Три команды независимо определяют
active_user, и дашборды перестают совпадать с моделью. - Обозначение векторной базы данных как «feature store». Она не умеет делать структурированные поиски по ключу сущности, а промт, которому нужно и то, и другое, всё равно окажется завязан на две системы.
- Backfill без point-in-time join'ов. Обучающая выборка выглядит отлично, модель в продакшене — сломана, а источник разрыва — утечка данных.
Сравнение с Feast, Tecton и Databricks
Наши ~200 строк делают то же самое в миниатюре.
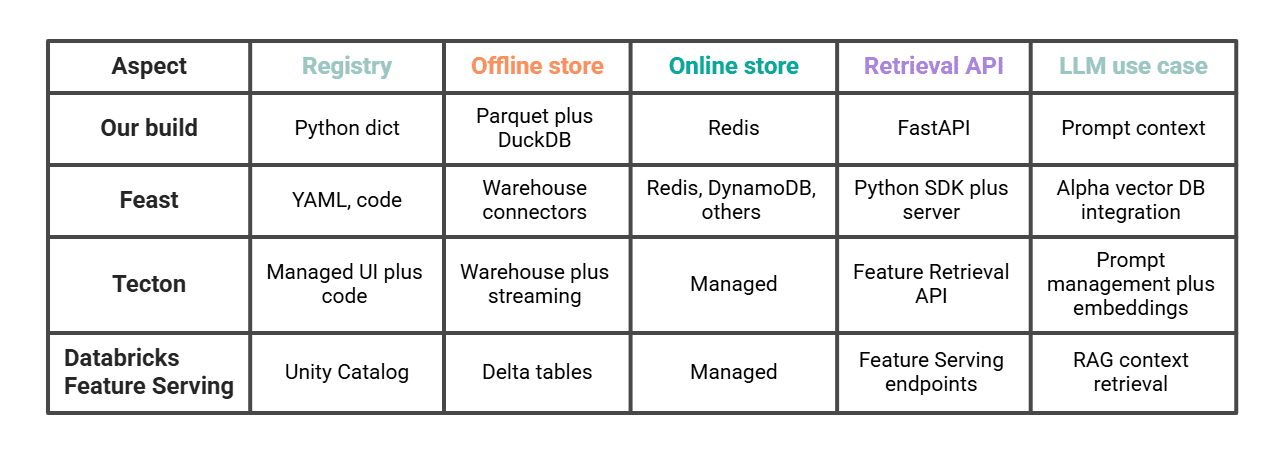
Feast — ближайший аналог, если захотим развивать тот же подход самостоятельно, на собственном хостинге. Tecton и Databricks — управляемые решения, и у них есть явные LLM-фичи (Feature Retrieval API для LLM у Tecton, Feature Serving для составных генеративных AI-систем у Databricks). Выбор между ними — по большей части вопрос того, сколько мы хотим эксплуатировать сами и живёт ли уже остальной наш стек в Databricks.
Заключение
Работоспособный feature store умещается в пять компонентов: реестр, офлайн-хранилище, онлайн-хранилище, шаг материализации и retrieval API. Собрать его один раз — значит понять, почему продакшен-системы выглядят именно так. Это также показывает, где дизайн меняется под задачи AI: именно путь онлайн-извлечения является интерфейсом, к которому обращается языковая модель; point-in-time join'ы важны, когда мы обучаем или оцениваем модель; а векторная база данных стоит рядом с feature store, а не внутри него.
Когда все эти части собраны, замена нашей минимальной версии на Feast, Tecton или Databricks — это по большей части миграция реестра. Форма системы остаётся той же.