Введение в агентный ИИ
Известная цитата гласит, что любая достаточно развитая технология неотличима от волшебства. Именно так ощущаются многие современные фреймворки искусственного интеллекта. Инструменты вроде GitHub Copilot, Claude Desktop, OpenAI Operator и Perplexity Comet автоматизируют повседневные операции, которые всего пять лет назад казались невозможными для автоматизации. Еще более впечатляюще то, что с помощью нескольких строк кода можно создать собственные продвинутые инструменты ИИ: они просматривают файлы, исследуют интернет, переходят по ссылкам и даже совершают покупки. Это действительно напоминает волшебство.
Хотя вера в специалистов по данным, способных решать задачи как волшебники, вполне обоснованна, магия здесь ни при чем. Понимание механики создания таких систем и процессов под капотом вызывает восторг и оказывается полезным. Поэтому планируется серия публикаций о концепциях проектирования агентного ИИ, которые помогут разобраться в работе этих волшебных инструментов.
Для глубокого осмысления будет создана система с несколькими агентами ИИ с нуля. Откажемся от фреймворков типа CrewAI или smolagents и будем взаимодействовать напрямую с API базовых моделей. По ходу дела разберем ключевые паттерны агентного дизайна: рефлексию, использование инструментов, планирование и конфигурации с несколькими агентами. Затем все это объединим в полноценную систему с несколькими агентами ИИ, способную отвечать на сложные вопросы.

Большие языковые модели применяют иной метод. При получении вопроса такая модель по умолчанию генерирует ответ поблочно, не имея возможности просмотреть результат и исправить ошибки. Однако в настройке агентного ИИ можно внедрить петли обратной связи для моделей, либо попросив саму модель оценить и доработать свой ответ, либо предоставив внешнюю обратную связь, например, результаты выполнения SQL-запроса. Именно в этом суть рефлексии. Концепция кажется простой, но приводит к заметно лучшим исходам.
Существует обширный массив исследований, подтверждающих преимущества рефлексии:
- «Self-Refine: Iterative Refinement with Self-Feedback» от Madaan et al. (2023) продемонстрировало рост производительности примерно на 20 процентных пунктов по различным задачам, от генерации диалоговых ответов до математического вывода.

- В «Reflexion: Language Agents with Verbal Reinforcement Learning» от Shinn et al. (2023) авторы достигли 91% точности pass@1 на бенчмарке HumanEval для кодирования, обогнав предыдущий рекорд GPT-4 с 80%. Кроме того, Reflexion существенно превзошел базовые методы на бенчмарке HotPotQA (набор вопросов-ответов на основе Википедии, требующий разбора контента и рассуждений по нескольким документам).

- «CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing» от Gou et al. (2024) акцентирует влияние внешней обратной связи, позволяя моделям использовать внешние инструменты для проверки и корректировки выводов. Этот подход обеспечил улучшение точности на 10–30 процентных пунктов по задачам от свободных вопросов до математических проблем.
Рефлексия особенно ценна в агентных системах, поскольку позволяет корректировать курс на множестве этапов процесса:
- При поступлении вопроса от пользователя модель может применить рефлексию для оценки выполнимости запроса.
- При формировании начального плана рефлексия поможет удостовериться в его логичности и способности достичь цели.
- После каждого шага выполнения или вызова инструмента агент оценивает, идет ли все по плану, и стоит ли вносить корректировки.
- По завершении плана агент рефлексирует, чтобы подтвердить достижение цели и решение задачи.
Очевидно, что рефлексия повышает точность. Тем не менее, есть компромиссы, требующие внимания. Рефлексия может потребовать нескольких дополнительных вызовов модели и, возможно, других систем, что увеличивает задержку и затраты. В коммерческих сценариях нужно взвешивать, оправдывают ли улучшения качества дополнительные расходы и замедления в пользовательском потоке.
Рефлексия в фреймворках
Поскольку ценность рефлексии для агентов ИИ не вызывает сомнений, она широко применяется в популярных фреймворках. Рассмотрим несколько примеров.
Идея рефлексии впервые была предложена в статье «ReAct: Synergizing Reasoning and Acting in Language Models» от Yao et al. (2022). ReAct — это фреймворк, сочетающий чередующиеся этапы рассуждений (рефлексия через явные трассы мыслей) и действий (релевантные операции в окружении). В нем рассуждения направляют выбор действий, а действия генерируют новые наблюдения для дальнейших рассуждений. Сам этап рассуждений объединяет рефлексию и планирование.
Фреймворк набрал популярность, поэтому появились готовые реализации, такие как:
- Фреймворк DSPy от Databricks с классом
ReAct; - В LangGraph доступна функция
create_react_agent; - Агенты для кода в библиотеке smolagents от HuggingFace также опираются на архитектуру ReAct.
Реализация рефлексии с нуля
Теперь, изучив теорию и существующие реализации, пора перейти к практике и создать собственную версию. В подходе ReAct агенты используют рефлексию на каждом шаге, интегрируя планирование. Однако для ясного понимания влияния рефлексии рассмотрим ее изолированно.
В качестве примера возьмем преобразование текста в SQL: модели передается вопрос, и ожидается возврат валидного SQL-запроса. Будем работать с набором данных о задержках рейсов и диалектом ClickHouse.
Начнем с базового подхода — прямой генерации без рефлексии. Затем применим рефлексию, попросив модель критиковать и улучшать SQL или предоставив дополнительную обратную связь. После этого измерим качество ответов, чтобы подтвердить эффективность рефлексии.
Прямая генерация
Начнем с самого простого метода — прямой генерации, где модель создает SQL для ответа на запрос пользователя.
pip install anthropicНеобходимо указать ключ API для Anthropic.
import os os.environ['ANTHROPIC_API_KEY'] = config['ANTHROPIC_API_KEY']Далее инициализируем клиент, и все готово.
import anthropic client = anthropic.Anthropic()Теперь клиент можно использовать для отправки сообщений модели. Сформируем функцию для генерации SQL на основе запроса пользователя. Системный промпт содержит базовые инструкции и детальное описание схемы данных. Также создана функция для передачи системного промпта и запроса пользователя модели.
base_sql_system_prompt = ''' You are a senior SQL developer and your task is to help generate a SQL query based on user requirements. You are working with ClickHouse database. Specify the format (Tab Separated With Names) in the SQL query output to ensure that column names are included in the output. Do not use count(*) in your queries since it's a bad practice with columnar databases, prefer using count(). Ensure that the query is syntactically correct and optimized for performance, taking into account ClickHouse specific features (i.e. that ClickHouse is a columnar database and supports functions like ARRAY JOIN, SAMPLE, etc.). Return only the SQL query without any additional explanations or comments. You will be working with flight_data table which has the following schema: Column Name | Data Type | Null % | Example Value | Description --- | --- | --- | --- | --- year | Int64 | 0.0 | 2024 | Year of flight month | Int64 | 0.0 | 1 | Month of flight (1–12) day_of_month | Int64 | 0.0 | 1 | Day of the month day_of_week | Int64 | 0.0 | 1 | Day of week (1=Monday … 7=Sunday) fl_date | datetime64[ns] | 0.0 | 2024-01-01 00:00:00 | Flight date (YYYY-MM-DD) op_unique_carrier | object | 0.0 | 9E | Unique carrier code op_carrier_fl_num | float64 | 0.0 | 4814.0 | Flight number for reporting airline origin | object | 0.0 | JFK | Origin airport code origin_city_name | object | 0.0 | "New York, NY" | Origin city name origin_state_nm | object | 0.0 | New York | Origin state name dest | object | 0.0 | DTW | Destination airport code dest_city_name | object | 0.0 | "Detroit, MI" | Destination city name dest_state_nm | object | 0.0 | Michigan | Destination state name crs_dep_time | Int64 | 0.0 | 1252 | Scheduled departure time (local, hhmm) dep_time | float64 | 1.31 | 1247.0 | Actual departure time (local, hhmm) dep_delay | float64 | 1.31 | -5.0 | Departure delay in minutes (negative if early) taxi_out | float64 | 1.35 | 31.0 | Taxi out time in minutes wheels_off | float64 | 1.35 | 1318.0 | Wheels-off time (local, hhmm) wheels_on | float64 | 1.38 | 1442.0 | Wheels-on time (local, hhmm) taxi_in | float64 | 1.38 | 7.0 | Taxi in time in minutes crs_arr_time | Int64 | 0.0 | 1508 | Scheduled arrival time (local, hhmm) arr_time | float64 | 1.38 | 1449.0 | Actual arrival time (local, hhmm) arr_delay | float64 | 1.61 | -19.0 | Arrival delay in minutes (negative if early) cancelled | int64 | 0.0 | 0 | Cancelled flight indicator (0=No, 1=Yes) cancellation_code | object | 98.64 | B | Reason for cancellation (if cancelled) diverted | int64 | 0.0 | 0 | Diverted flight indicator (0=No, 1=Yes) crs_elapsed_time | float64 | 0.0 | 136.0 | Scheduled elapsed time in minutes actual_elapsed_time | float64 | 1.61 | 122.0 | Actual elapsed time in minutes air_time | float64 | 1.61 | 84.0 | Flight time in minutes distance | float64 | 0.0 | 509.0 | Distance between origin and destination (miles) carrier_delay | int64 | 0.0 | 0 | Carrier-related delay in minutes weather_delay | int64 | 0.0 | 0 | Weather-related delay in minutes nas_delay | int64 | 0.0 | 0 | National Air System delay in minutes security_delay | int64 | 0.0 | 0 | Security delay in minutes late_aircraft_delay | int64 | 0.0 | 0 | Late aircraft delay in minutes ''' def generate_direct_sql(rec): # making an LLM call message = client.messages.create( model = "claude-3-5-haiku-latest", # I chose smaller model so that it's easier for us to see the impact max_tokens = 8192, system=base_sql_system_prompt, messages = [ {'role': 'user', 'content': rec['question']} ] ) sql = message.content[0].text # cleaning the output if sql.endswith('```'): sql = sql[:-3] if sql.startswith('```sql'): sql = sql[6:] return sqlВот и все. Теперь протестируем решение для преобразования текста в SQL. Подготовлен небольшой набор из 20 пар вопрос-ответ для оценки работы системы. Пример одного из них:
{ 'question': 'What was the highest speed in mph?', 'answer': ''' select max(distance / (air_time / 60)) as max_speed from flight_data where air_time > 0 format TabSeparatedWithNames''' }Применяем функцию преобразования текста в SQL ко всем запросам из тестового набора.
# load evaluation set with open('./data/flight_data_qa_pairs.json', 'r') as f: qa_pairs = json.load(f) qa_pairs_df = pd.DataFrame(qa_pairs) tmp = [] # executing LLM for each question in our eval set for rec in tqdm.tqdm(qa_pairs_df.to_dict('records')): llm_sql = generate_direct_sql(rec) tmp.append( { 'id': rec['id'], 'llm_direct_sql': llm_sql } ) llm_direct_df = pd.DataFrame(tmp) direct_result_df = qa_pairs_df.merge(llm_direct_df, on = 'id')Получены ответы, следующий этап — оценка качества.
Оценка качества
К сожалению, в этой задаче нет единственного верного ответа, поэтому прямое сравнение SQL от модели с эталоном невозможно. Нужно разработать метод измерения качества.
Некоторые аспекты качества можно проверить объективными критериями, но для подтверждения правильности ответа потребуется модель ИИ. Поэтому комбинируем подходы:
- Сначала объективно проверим наличие правильного формата в SQL (инструктировали использовать
TabSeparatedWithNames). - Затем выполним сгенерированный запрос и посмотрим, выдает ли ClickHouse ошибку выполнения.
- Наконец, создадим судью на базе модели ИИ, которая сравнит вывод сгенерированного запроса с эталонным ответом и определит различия.
Начнем с выполнения SQL. Функция get_clickhouse_data не выбрасывает исключение, а возвращает текст с объяснением ошибки, который можно обработать моделью позже.
CH_HOST = 'http://localhost:8123' # default address import requests import pandas as pd import tqdm # function to execute SQL query def get_clickhouse_data(query, host = CH_HOST, connection_timeout = 1500): r = requests.post(host, params = {'query': query}, timeout = connection_timeout) if r.status_code == 200: return r.text else: return 'Database returned the following error:n' + r.text # getting the results of SQL execution direct_result_df['llm_direct_output'] = direct_result_df['llm_direct_sql'].apply(get_clickhouse_data) direct_result_df['answer_output'] = direct_result_df['answer'].apply(get_clickhouse_data)Далее создаем судью на базе модели ИИ. Для этого используем подход цепочки мыслей, побуждая модель обосновать вывод перед финальным решением. Это позволяет модели обдумать проблему, повышая качество ответа.
llm_judge_system_prompt = ''' You are a senior analyst and your task is to compare two SQL query results and determine if they are equivalent. Focus only on the data returned by the queries, ignoring any formatting differences. Take into account the initial user query and information needed to answer it. For example, if user asked for the average distance, and both queries return the same average value but in one of them there's also a count of records, you should consider them equivalent, since both provide the same requested information. Answer with a JSON of the following structure: { 'reasoning': '<your reasoning here, 1-3 sentences on why you think they are equivalent or not>', 'equivalence': <true|false> } Ensure that ONLY JSON is in the output. You will be working with flight_data table which has the following schema: Column Name | Data Type | Null % | Example Value | Description --- | --- | --- | --- | --- year | Int64 | 0.0 | 2024 | Year of flight month | Int64 | 0.0 | 1 | Month of flight (1–12) day_of_month | Int64 | 0.0 | 1 | Day of the month day_of_week | Int64 | 0.0 | 1 | Day of week (1=Monday … 7=Sunday) fl_date | datetime64[ns] | 0.0 | 2024-01-01 00:00:00 | Flight date (YYYY-MM-DD) op_unique_carrier | object | 0.0 | 9E | Unique carrier code op_carrier_fl_num | float64 | 0.0 | 4814.0 | Flight number for reporting airline origin | object | 0.0 | JFK | Origin airport code origin_city_name | object | 0.0 | "New York, NY" | Origin city name origin_state_nm | object | 0.0 | New York | Origin state name dest | object | 0.0 | DTW | Destination airport code dest_city_name | object | 0.0 | "Detroit, MI" | Destination city name dest_state_nm | object | 0.0 | Michigan | Destination state name crs_dep_time | Int64 | 0.0 | 1252 | Scheduled departure time (local, hhmm) dep_time | float64 | 1.31 | 1247.0 | Actual departure time (local, hhmm) dep_delay | float64 | 1.31 | -5.0 | Departure delay in minutes (negative if early) taxi_out | float64 | 1.35 | 31.0 | Taxi out time in minutes wheels_off | float64 | 1.35 | 1318.0 | Wheels-off time (local, hhmm) wheels_on | float64 | 1.38 | 1442.0 | Wheels-on time (local, hhmm) taxi_in | float64 | 1.38 | 7.0 | Taxi in time in minutes crs_arr_time | Int64 | 0.0 | 1508 | Scheduled arrival time (local, hhmm) arr_time | float64 | 1.38 | 1449.0 | Actual arrival time (local, hhmm) arr_delay | float64 | 1.61 | -19.0 | Arrival delay in minutes (negative if early) cancelled | int64 | 0.0 | 0 | Cancelled flight indicator (0=No, 1=Yes) cancellation_code | object | 98.64 | B | Reason for cancellation (if cancelled) diverted | int64 | 0.0 | 0 | Diverted flight indicator (0=No, 1=Yes) crs_elapsed_time | float64 | 0.0 | 136.0 | Scheduled elapsed time in minutes actual_elapsed_time | float64 | 1.61 | 122.0 | Actual elapsed time in minutes air_time | float64 | 1.61 | 84.0 | Flight time in minutes distance | float64 | 0.0 | 509.0 | Distance between origin and destination (miles) carrier_delay | int64 | 0.0 | 0 | Carrier-related delay in minutes weather_delay | int64 | 0.0 | 0 | Weather-related delay in minutes nas_delay | int64 | 0.0 | 0 | National Air System delay in minutes security_delay | int64 | 0.0 | 0 | Security delay in minutes late_aircraft_delay | int64 | 0.0 | 0 | Late aircraft delay in minutes ''' llm_judge_user_prompt_template = ''' Here is the initial user query: {user_query} Here is the SQL query generated by the first analyst: SQL: {sql1} Database output: {result1} Here is the SQL query generated by the second analyst: SQL: {sql2} Database output: {result2} ''' def llm_judge(rec, field_to_check): # construct the user prompt user_prompt = llm_judge_user_prompt_template.format( user_query = rec['question'], sql1 = rec['answer'], result1 = rec['answer_output'], sql2 = rec[field_to_check + '_sql'], result2 = rec[field_to_check + '_output'] ) # make an LLM call message = client.messages.create( model = "claude-sonnet-4-5", max_tokens = 8192, temperature = 0.1, system = llm_judge_system_prompt, messages=[ {'role': 'user', 'content': user_prompt} ] ) data = message.content[0].text # Strip markdown code blocks data = data.strip() if data.startswith('```json'): data = data[7:] elif data.startswith('```'): data = data[3:] if data.endswith('```'): data = data[:-3] data = data.strip() return json.loads(data)Запускаем судью на базе модели ИИ для получения результатов.
tmp = [] for rec in tqdm.tqdm(direct_result_df.to_dict('records')): try: judgment = llm_judge(rec, 'llm_direct') except Exception as e: print(f"Error processing record {rec['id']}: {e}") continue tmp.append( { 'id': rec['id'], 'llm_judge_reasoning': judgment['reasoning'], 'llm_judge_equivalence': judgment['equivalence'] } ) judge_df = pd.DataFrame(tmp) direct_result_df = direct_result_df.merge(judge_df, on = 'id')Рассмотрим пример работы судьи на базе модели ИИ.
# user query In 2024, what percentage of time all airplanes spent in the air? # correct answer select (sum(air_time) / sum(actual_elapsed_time)) * 100 as percentage_in_air where year = 2024 from flight_data format TabSeparatedWithNames percentage_in_air 81.43582596894757 # generated by LLM answer SELECT round(sum(air_time) / (sum(air_time) + sum(taxi_out) + sum(taxi_in)) * 100, 2) as air_time_percentage FROM flight_data WHERE year = 2024 FORMAT TabSeparatedWithNames air_time_percentage 81.39 # LLM judge response { 'reasoning': 'Both queries calculate the percentage of time airplanes spent in the air, but use different denominators. The first query uses actual_elapsed_time (which includes air_time + taxi_out + taxi_in + any ground delays), while the second uses only (air_time + taxi_out + taxi_in). The second query is approach is more accurate for answering "time airplanes spent in the air" as it excludes ground delays. However, the results are very close (81.44% vs 81.39%), suggesting minimal impact. These are materially different approaches that happen to yield similar results', 'equivalence': FALSE }Обоснование выглядит убедительно, так что судье можно доверять. Теперь проверим все сгенерированные моделью запросы.
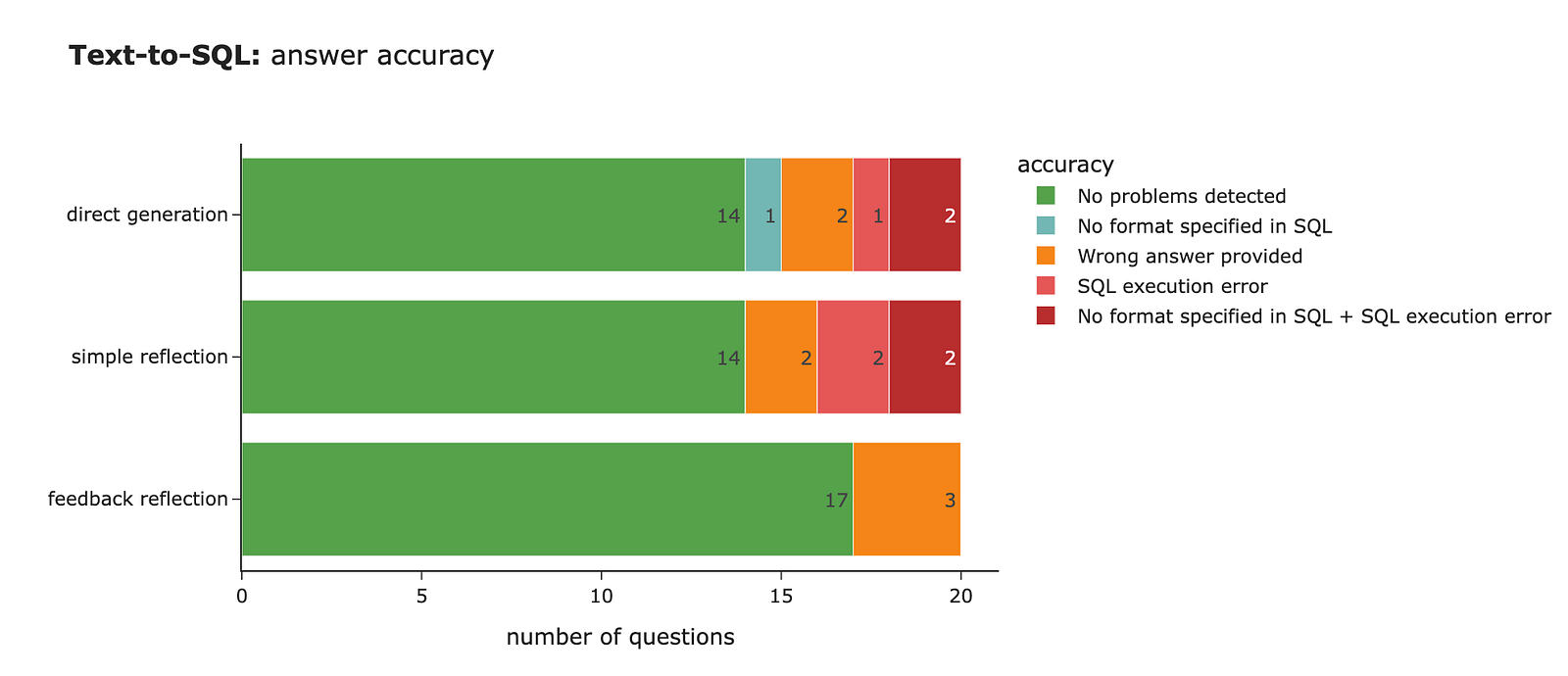
def get_llm_accuracy(sql, output, equivalence): problems = [] if 'format tabseparatedwithnames' not in sql.lower(): problems.append('No format specified in SQL') if 'Database returned the following error' in output: problems.append('SQL execution error') if not equivalence and ('SQL execution error' not in problems): problems.append('Wrong answer provided') if len(problems) == 0: return 'No problems detected' else: return ' + '.join(problems) direct_result_df['llm_direct_sql_quality_heuristics'] = direct_result_df.apply( lambda row: get_llm_accuracy(row['llm_direct_sql'], row['llm_direct_output'], row['llm_judge_equivalence']), axis=1)Модель выдала правильный ответ в 70% случаев, что неплохо. Но есть пространство для роста, поскольку часто ответ неверен или формат указан неправильно, что приводит к ошибкам выполнения SQL.

Добавление шага рефлексии
Для повышения качества решения добавим шаг рефлексии, где модель оценит и доработает свой ответ.
Для вызова рефлексии сохраним тот же системный промпт, поскольку он включает всю нужную информацию о SQL и схеме данных. Но изменим сообщение пользователя, чтобы передать исходный запрос и сгенерированный SQL, попросив модель критиковать и улучшать его.
simple_reflection_user_prompt_template = ''' Your task is to assess the SQL query generated by another analyst and propose improvements if necessary. Check whether the query is syntactically correct and optimized for performance. Pay attention to nuances in data (especially time stamps types, whether to use total elapsed time or time in the air, etc). Ensure that the query answers the initial user question accurately. As the result return the following JSON: {{ 'reasoning': '<your reasoning here, 2-4 sentences on why you made changes or not>', 'refined_sql': '<the improved SQL query here>' }} Ensure that ONLY JSON is in the output and nothing else. Ensure that the output JSON is valid. Here is the initial user query: {user_query} Here is the SQL query generated by another analyst: {sql} ''' def simple_reflection(rec) -> str: # constructing a user prompt user_prompt = simple_reflection_user_prompt_template.format( user_query=rec['question'], sql=rec['llm_direct_sql'] ) # making an LLM call message = client.messages.create( model="claude-3-5-haiku-latest", max_tokens = 8192, system=base_sql_system_prompt, messages=[ {'role': 'user', 'content': user_prompt} ] ) data = message.content[0].text # strip markdown code blocks data = data.strip() if data.startswith('```json'): data = data[7:] elif data.startswith('```'): data = data[3:] if data.endswith('```'): data = data[:-3] data = data.strip() return json.loads(data.replace('\n', ' '))Доработаем запросы с рефлексией и измерим точность. Улучшения в итоговом качестве минимальны. Точность остается на уровне 70% правильных ответов.

Рассмотрим конкретные примеры, чтобы понять, что произошло. В некоторых случаях модель исправила проблему, либо уточнив формат, либо добавив логику для обработки нулевых значений.

Однако бывают ситуации, когда модель усложняет верный исходный SQL. Первоначальный запрос совпадал с эталоном, но модель сочла нужным его 'улучшить'. Некоторые изменения разумны (учет null-значений или исключение отмененных рейсов). Но иногда она применяет семплирование ClickHouse, хотя данных немного и таблица не поддерживает его. В итоге доработанный запрос вызывает ошибку выполнения: Database returned the following error: Code: 141. DB::Exception: Storage default.flight_data doesn't support sampling. (SAMPLING_NOT_SUPPORTED).

Рефлексия с внешней обратной связью
Рефлексия не дала значительного прироста точности. Вероятно, потому что не предоставили дополнительной информации для улучшения. Попробуем поделиться внешней обратной связью: результат проверки формата и выводом базы данных (данные или сообщение об ошибке). Сформируем промпт и сгенерируем новую версию SQL.
feedback_reflection_user_prompt_template = ''' Your task is to assess the SQL query generated by another analyst and propose improvements if necessary. Check whether the query is syntactically correct and optimized for performance. Pay attention to nuances in data (especially time stamps types, whether to use total elapsed time or time in the air, etc). Ensure that the query answers the initial user question accurately. As the result return the following JSON: {{ 'reasoning': '<your reasoning here, 2-4 sentences on why you made changes or not>', 'refined_sql': '<the improved SQL query here>' }} Ensure that ONLY JSON is in the output and nothing else. Ensure that the output JSON is valid. Here is the initial user query: {user_query} Here is the SQL query generated by another analyst: {sql} Here is the database output of this query: {output} We run an automatic check on the SQL query to check whether it has fomatting issues. Here's the output: {formatting} ''' def feedback_reflection(rec) -> str: # define message for formatting if 'No format specified in SQL' in rec['llm_direct_sql_quality_heuristics']: formatting = 'SQL missing formatting. Specify "format TabSeparatedWithNames" to ensure that column names are also returned' else: formatting = 'Formatting is correct' # constructing a user prompt user_prompt = feedback_reflection_user_prompt_template.format( user_query = rec['question'], sql = rec['llm_direct_sql'], output = rec['llm_direct_output'], formatting = formatting ) # making an LLM call message = client.messages.create( model = "claude-3-5-haiku-latest", max_tokens = 8192, system = base_sql_system_prompt, messages = [ {'role': 'user', 'content': user_prompt} ] ) data = message.content[0].text # strip markdown code blocks data = data.strip() if data.startswith('```json'): data = data[7:] elif data.startswith('```'): data = data[3:] if data.endswith('```'): data = data[:-3] data = data.strip() return json.loads(data.replace('\n', ' '))После запуска измерений точности видно значительное улучшение: 17 правильных ответов (85% точности) против 14 (70% точности).
В случаях, где модель исправила ошибки, она уточнила формат, устранила проблемы выполнения SQL и даже пересмотрела бизнес-логику (например, использовала время в воздухе для расчета скорости).

Проведем анализ ошибок для изучения неудачных случаев. В таблице видно, что модель испытывала трудности с определением временных меток, неверным расчетом общего времени или использованием общего времени вместо времени в воздухе для скорости. Однако некоторые расхождения неоднозначны:
- В последнем запросе период не был явно указан, так что использование 2010–2023 года моделью разумно. Это не ошибка, а повод скорректировать оценку.
- Другой пример — определение скорости авиакомпании:
avg(distance/time)илиsum(distance)/sum(time). Оба варианта допустимы, поскольку в запросе пользователя или системном промпте метод не уточнен (при отсутствии предопределенного подхода к расчету).

В целом результат впечатляющий. Итоговая точность 85% — это существенный прирост на 15 процентных пунктов. Можно расширить до 2–3 итераций рефлексии, но важно оценить точку убывающей отдачи в конкретном сценарии, поскольку каждая итерация увеличивает затраты и задержку.
Полный код доступен на GitHub.
Итоги
Подводим черту. В этой публикации начато путешествие в мир понимания механизмов агентных систем ИИ. Для этого будет реализован инструмент преобразования текста в данные с несколькими агентами, используя только вызовы API базовых моделей. По пути разберем ключевые паттерны дизайна поэтапно: начиная с рефлексии сегодня и переходя к использованию инструментов, планированию и координации нескольких агентов.
В статье рассмотрены основы самого фундаментального паттерна — рефлексии. Она лежит в основе любого агентного процесса, поскольку модель должна отслеживать прогресс к конечной цели.
Рефлексия — относительно простой паттерн. Достаточно запросить у той же или другой модели анализ результата и попытку улучшения. Как показали практика и исследования, предоставление внешней обратной связи (результаты статических проверок или вывод базы данных) существенно повышает точность. Множество научных работ и опыт с агентом текст-в-SQL подтверждают преимущества рефлексии. Однако такие улучшения имеют цену: больше потраченных токенов и повышенная задержка из-за нескольких вызовов API.
Благодарю за внимание. Надеюсь, материал оказался полезным. Помните слова Эйнштейна: «Важно не прекращать задавать вопросы. Любопытство само по себе оправдано».
Источники
Эта публикация вдохновлена курсом «Agentic AI» от Andrew Ng на платформе DeepLearning.AI.