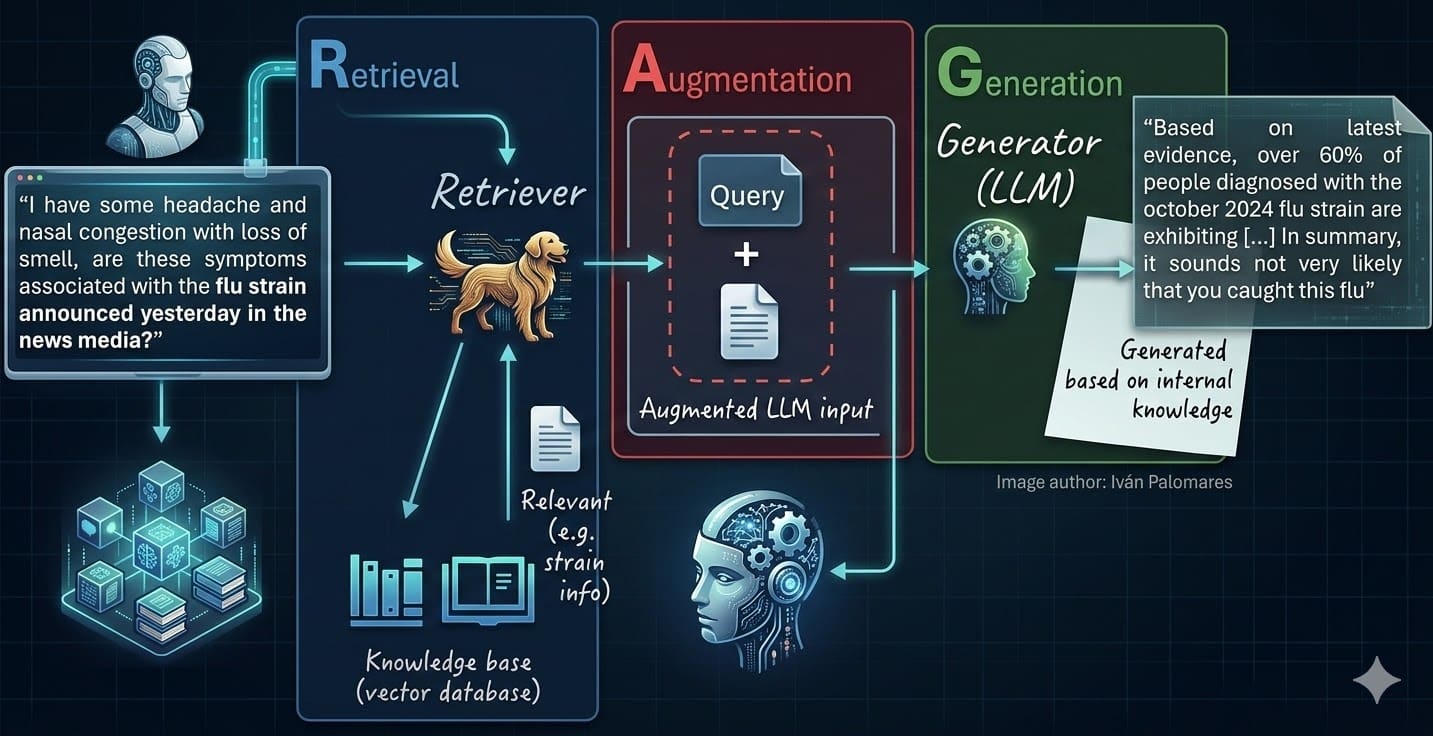
Введение
Системы генерации с дополнением поиском, или RAG, представляют собой естественное развитие изолированных больших языковых моделей, или LLM. Такие системы решают ключевые проблемы стандартных LLM: галлюцинации модели и отсутствие свежих, подходящих знаний для формирования точных ответов, опирающихся на факты, в ответ на вопросы пользователей.
Здесь собраны основные выводы из опыта работы с RAG, дополненные свежими подходами и практиками. Они помогают описать семь обязательных шагов для надежной разработки подобных систем.
Каждый шаг связан с отдельным этапом или элементом RAG-среды. Это видно по цифрам от [1] до [7] на схеме классической архитектуры RAG ниже:
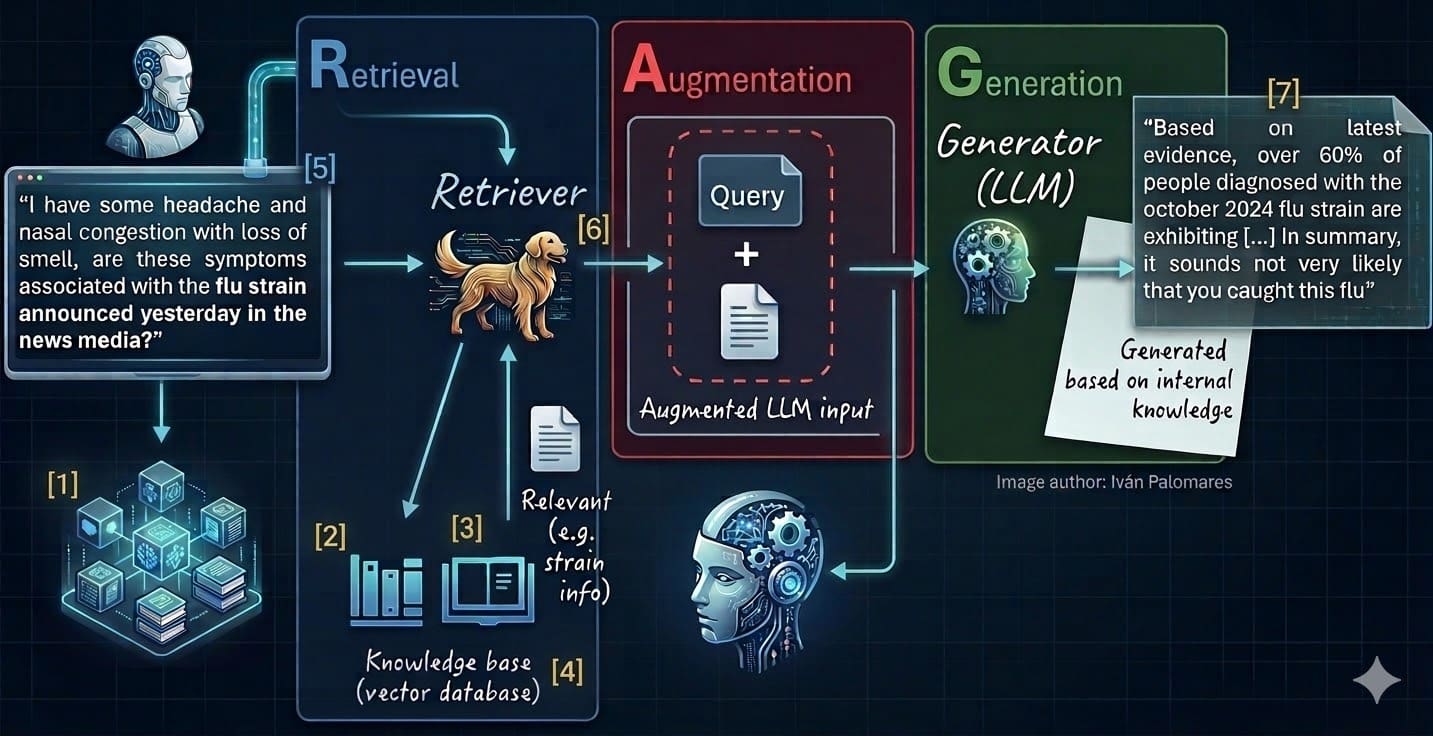
- Выбор и очистка источников данных
- Разбиение на чанки и разделение
- Векторизация и создание встраиваний
- Заполнение векторных баз данных
- Векторизация запросов
- Извлечение подходящего контекста
- Формирование обоснованного ответа
1. Выбор и очистка источников данных
Принцип «мусор на входе — мусор на выходе» приобретает особую силу именно в RAG. Эффективность системы прямо зависит от того, насколько релевантны, качественны и чисты тексты, которые она извлекает. Для создания надежных баз знаний находите ценные хранилища данных и регулярно их проверяйте. Перед загрузкой сырого материала запускайте мощные конвейеры очистки: удаляйте персональные данные (PII), дубликаты и прочий шум. Это постоянный инженерный процесс, который повторяется при добавлении новых порций информации.
2. Разбиение документов на чанки
Многие тексты или документы, такие как романы или диссертации, слишком объемны, чтобы превращать их в единый фрагмент для встраивания. Разбиение на чанки подразумевает деление длинных текстов на небольшие семантически цельные части с сохранением контекста. Важно соблюдать баланс: слишком много фрагментов — и контекст потеряется, слишком мало — и поиск по семантике пострадает.
Существует несколько методов разбиения: от подсчета символов до логических границ вроде абзацев или глав. Инструменты вроде LlamaIndex и LangChain с их Python-библиотеками упрощают задачу за счет продвинутых алгоритмов разделения.
Часто чанки делают с перекрытием, чтобы сохранить связность при извлечении. Вот пример такого разбиения на коротком фрагменте текста:
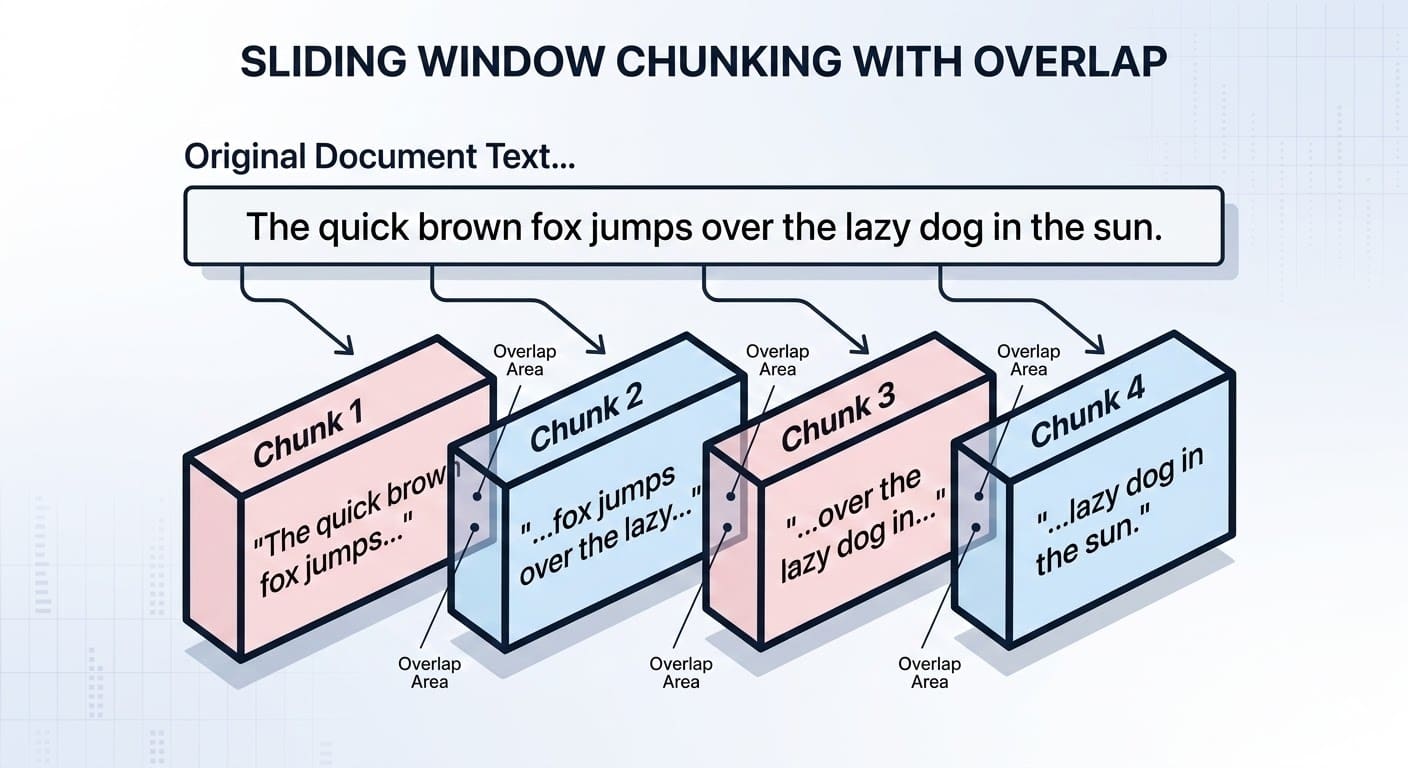
Разбиение документов также помогает управлять размером контекста в RAG-входах.
3. Векторизация документов и создание встраиваний
После разбиения чанки переводят в «язык машин» — числа. Для этого каждый текст превращают в векторное встраивание: плотное числовое представление в многомерном пространстве, которое фиксирует семантику. В последние годы для этого разрабатывают специализированные LLM — модели встраиваний. Популярный открытый вариант — all-MiniLM-L6-v2 от Hugging Face.
Встраивания превосходят классические способы представления текста вроде TF-IDF или bag-of-words.
4. Заполнение векторной базы данных
Векторные базы данных заточены под поиск по многомерным массивам (встраиваниям), представляющим тексты, — это сердце RAG для нахождения релевантных документов по запросу. Подходят открытые хранилища вроде FAISS или платные сервисы вроде Pinecone. Они связывают человеческий текст с математическими векторами.
Вот фрагмент кода для разбиения текста (см. шаг 2) и заполнения локальной бесплатной векторной базы с помощью LangChain и Chroma. Предполагается, что длинный документ лежит в файле knowledge_base.txt:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load and chunk the data
docs = TextLoader("knowledge_base.txt").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(docs)
# Create text embeddings using a free open-source model and store in ChromaDB
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma.from_documents(documents=chunks, embedding=embedding_model, persist_directory="./db")
print(f"Successfully stored {len(chunks)} embedded chunks.")
5. Векторизация запросов
Запросы пользователей на естественном языке не сравнивают напрямую с векторами документов: их тоже преобразуют с помощью той же модели встраиваний (шаг 3). Получившийся вектор запроса сопоставляют с хранимыми, чтобы по мере сходства выбрать наиболее близкие документы.
Продвинутые методы векторизации и оптимизации запросов улучшают точность.
6. Извлечение релевантного контекста
После векторизации запроса ретривер RAG ищет похожие векторы (чанки документов) по сходству. Простой top-k работает, но фьюжн-ретривинг и переранжирование дают лучшие результаты для обогащения промта LLM.
Управление окном контекста важно, когда модель ограничена в обработке больших входов.
7. Формирование обоснованных ответов
На финальном этапе LLM получает запрос пользователя плюс извлеченный контекст и генерирует ответ строго на его основе. В хорошо спроектированной RAG это дает точные, проверяемые отклики, иногда с ссылками на источники из базы знаний.
Оценка качества ответа обязательна для анализа работы всей системы и решений о доработке модели, например, тонкой настройке. Для этого есть специальные фреймворки оценки.
Заключение
Архитектуры RAG стали неотъемлемой частью приложений на базе LLM, особенно в крупных коммерческих проектах. Они повышают надежность и насыщенность знаниями, позволяя моделям выдавать ответы на основе доказательств — в том числе из внутренних данных компаний.
Эти семь шагов подводят к полному пониманию сборки RAG-систем. Освоив их, можно строить продвинутые LLM-приложения с уровнем производительности, точности и прозрачности, недостижимым для общедоступных моделей из интернета.